

Eating a bowl of noodles has never been easy for me. Now I don’t blame the chopsticks (yet to learn how to use ’em) but my aversion towards the cabbage in the noodles. Sorting through those yummy strands, I neatly pick out the shreds of cabbage before gobbling the entire lot.
How did I differentiate a strip of cabbage from a thread of noodle? Would have never given it a thought, if not for the growing importance of imitating the model of the human neurons in the technological space.
In an attempt to replicate the much-marveled human intelligence, voluminous efforts are taken to turn machines into rational mortal-like beings. This isn’t just another fad but sprouted as a thought to Alan Turing who believed in training machines to learn from past experiences.
Soon machines started playing checkers and chess beating human champs. But as fun as games were, a bigger lesson learned was how useful artificial systems would become, if only they could “learn” like we do and apply acquired intelligence in real-life scenarios — think self-driving cars.
The Evolution of Learning:
Programming routines achieved a level of automation yet the logic and code had to be fed by humans. The concept of Artificial Intelligence, though initially linked with magical robots soon narrowed down to predictive and classification analysis.
Decision trees, clustering, and Bayesian networks were identified as means to predict users music preferences and classify notorious junk mails. While such traditional ML approaches provide a simple solution to many classification problems, a better way was sought to seamlessly identify speech, image, audio, video, and text just like a human would. This gave birth to various deep learning methods that relies mainly on the best learning mechanism ever — the human neuron and has in recent times made tech giants like Facebook, Amazon, Google go gaga over deep learning.
Though the interest has widened recently, Frank Rosenblatt designed the first Perceptron that simulated the activity of a single neuron way back in 1957. How could I not pull the example of the brain’s working here!
While decoding the working of the human brain is by itself quite elusive, what we do know is that the brain amazingly identifies objects and sounds by the propagation of electrical signals amidst layers of dendrites and triggers a positive signal when a threshold value is crossed. A perceptron, as found below, was devised keeping this in mind.
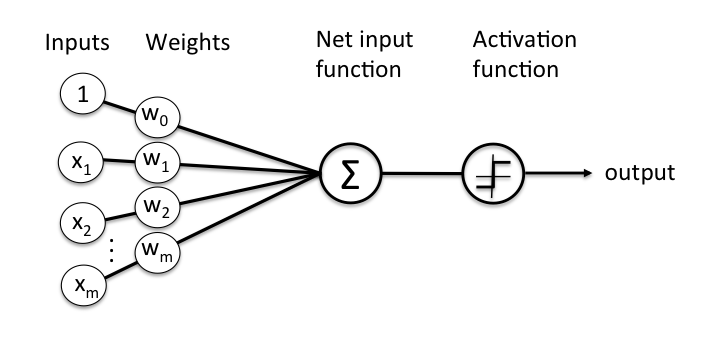
Image Source: https://medium.com/@debparnapratiher/deep-learning-for-dummies-1-86360db18367
The output is fired when the weighted sum of the inputs crosses a threshold value. Now what we have here is just a single layer perceptron which works only on linearly separable functions. Something as easy as drawing a single line and saying all white sheep on one side and the black on the other side. Which is not the case in the real world.
Image recognition — one of the main areas of application for neural networks, deals with a recognizing a lot of Features hidden behind pixels of data. To decipher these features, a multi-layer perceptron approach is taken. Similar to a perceptron, an input layer where the training data is fed and the output layer is seen, with a number of “hidden layers” between them.
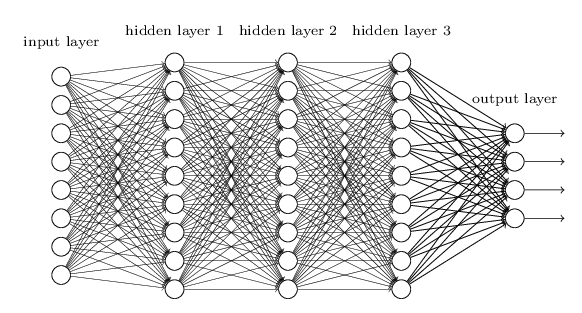
Image Source: http://neuralnetworksanddeeplearning.com/chap6.html
The number of hidden layers determines how deep the learning is and finding the right number of layers works on a trial and error basis. The “learning” part of these neural networks was the way in which these layers adjusted the weights assigned to them initially.
While various learning types are seen, back-propagation is seen as a common approach wherein random weights are assigned, the output seen is compared with the test data and the error in output is calculated comparing the two (ie. actual output vs expected output). Now the layer immediately closer to the output layer adjusts its weights leading to weight adjustments in the subsequent inner layers till the error rate is reduced.
A high-level yet practical way of seeing the hidden layers in action can be seen in the below image. I do owe an apology to cats and dogs, what with the innumerable times they have pulled into the “learning” experiments!
Simple as it may look in the example that each layer corresponds to a particular feature, the interpretability of how the hidden layers work is not as easy as it seems. This is because, in typical unsupervised learning scenarios, the hidden layers are likened to black boxes, that do what they do but the reasoning behind every layer remains a mystery like the brain.
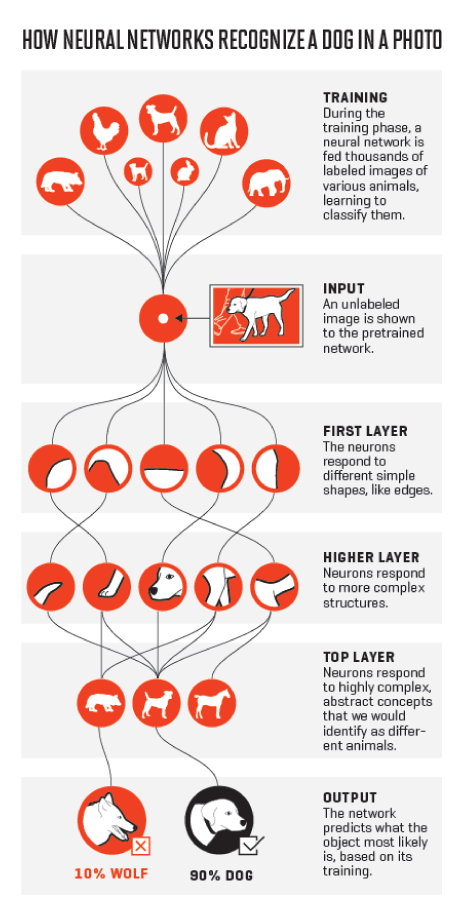
Image Source: http://fortune.com/ai-artificial-intelligence-deep-machine-learning/
Anyway, how is deep learning any different from other Machine learning approaches?
A single line answer would be the amount of training data involved and the computational power needed.
Before I elaborate on the differences, one has to understand that deep learning is a means to achieve machine learning and there exist many such ML methods to achieve the desired learning levels. Deep learning is just one among them that is gaining rapid popularity due to the minimum levels of manual intervention needed.
That being said, traditional ML models need a process called feature extraction where a programmer has to explicitly tell what features must be looked for in a certain training set. Also when anyone of the feature is missed out, the ML model fails to recognize the object in hand. The weightage here was on how good the algorithm was ie. a programmer had to keep all the possible guesses in mind. Else, varied signposts and a myriad of objects on road would be difficult for a driver-less car to detect, making such cases life-threatening.
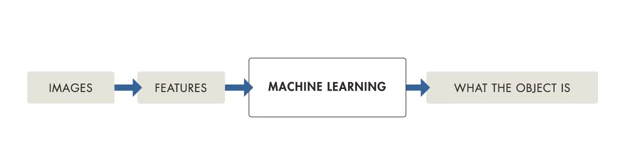
Image Source: Matlab tutorial on introduction to deep learning
Deep Learning, on the other hand, is fed with large data sets of diverse examples, from which the model learns for features to look for and produces an output with probability vectors in place. The model “learns” for itself just as we learnt numerical digits as kids.
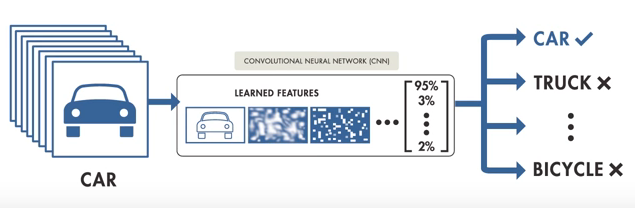
Image Source: Matlab tutorial on introduction to deep learning
Great! So why didn’t we start off with deep learning earlier?
The multi-layer perceptron and back-propagation methods were devised theoretically in the 1980s yet due to lack of huge amount of data and high processing capabilities, the muse died down. Since the advent of big data and Nvidia’s super powerful GPUs, the potential of deep learning is being tried and tested like never before.
Now a lot of debate has gone into how large data sets need to be. Though some claim that smaller yet diverse data-sets would do, the more parameters you want the model to learn or as complex as the problem in hand gets, so does the data required for training increase. Otherwise, the problem of having more dimensions yet small data results in over-fitting which means your model has literally mugged up its results and works only for the set you trained, rendering the layer learnings futile.
To validate the necessity of large data, let’s see three successful scenarios of large volume training data –
- The famous modern face recognition system of Facebook termed aptly as “DeepFace” deployed a training set of 4 Million facial images of more than 4000 identities and reached an accuracy level of 97.35% on labeled sets. Their research paper reiterates in many places how such large training sets helped in overcoming the problem of overfitting.
- Alex Krizhevsky — the one who developed AlexNet and joined Geoffrey Hinton in the Google Brain undertaking and fellow scholars, described a learning model for robotic grasping involving hand-eye coordination. To train their network a total of 800,000 grasp attempts were collected and the robotic arms successfully learnt a wider variety of grasp strategies.
- Andrej Karpathy, director of AI at Tesla during his Ph.D. days at Stanford used neural networks for dense captioning — identifying all parts of an image and not just a cat! The team had used 94,000 images and 4,100,000 region-grounded captions by which improvements were seen in speed and accuracy.
Andrej also claimed that the motto them he believed in was to keep his data large, algorithms simple and labels weak.
So how Large is your data?
Supporting the other side of the argument is a recent research paper on deep face representations using small data, face recognition problems were solved with 10,000 training images and found to be on par with that trained with 500,000 images. But the same hasn’t been proved for other places where deep learning is currently involved — speech recognition, vehicle, pedestrian, and landmark identification in self-driving vehicles, NLP, and medical imaging. A new aspect of Transfer learning has also been found to require large volumes of pre-trained datasets.
Till that is proved, in case you are looking to implement neural networks in your business like how the sales team at Microsoft is using NN to recommend prospects to be contacted or offerings to be recommended, you need access to a large amount of data.
Asserting this is Andrew Ng, former chief data scientist at Baidu and popular deep learning expert (the man behind the Cat experiment along with Jeff Dean at Google), who equates deep learning models to rocket engines that require loads of fuel which is data.
Data crawling has been identified as one of the means to collect such vast amounts of data apart from open datasets available in public (and been worked on by many). Company directories, IMDB listings, Wikipedia hold extensive data waiting to be trained.
Now before I get back to picking out the cabbage from my noodles (thanks to my amazing brain), if you need any assistance in gathering data through legit scraping and crawling for your next neural networks experiment, get in touch with us!

Ida Jessie Sagina
Content Marketing Specialist



3,310 Comments
I’m impressed, I must say. Seldom do I come across a blog that’s both equally educative and entertaining, and let me tell you, you have hit the nail on the head. The problem is something that too few men and women are speaking intelligently about. Now i’m very happy I came across this during my hunt for something regarding this.|
Hi colleagues, pleasant article and fastidious arguments commented here, I am really enjoying by these.|
“Nice post. I learn something totally new and challenging on sites I stumbleupon everyday. It’s always useful to read through articles from other writers and use something from their web sites.”
https://lapho-lover-israely.tk/news/tlinanvasqui
“I need to to thank you for this very good read!! I definitely enjoyed every little bit of it. I’ve got you saved as a favorite to look at new stuff you postO”
https://nowost-site-ra.moy.su/news/kaicd_laabvd_aams_kvl_ttifims_mvdlims_mclmt_ainttrntt/2022-03-23-23
“I need to to thank you for this very good read!! I absolutely enjoyed every bit of it. I have you saved as a favorite to look at new stuff you postO”
https://ondashboard.win/story.php?title=lywwy-swknwt-yjr%D7%90l-hy%D7%90-hr%D7%90wy-hr%D7%90jwnh-swknwt-byjr%D7%90l-%D7%90yph-tmyd-mwk%D7%9F-lhzmy%D7%9F-mlwwy%D7%9D-hdjy%D7%9D-jl-bnwt#discuss
“I needed to thank you for this excellent read!! I certainly enjoyed every bit of it. I’ve got you saved as a favorite to check out new stuff you postO”
http://1069.club/home.php?mod=space&uid=765277
“A fascinating discussion is worth comment. There’s no doubt that that you should write more on this subject matter, it may not be a taboo matter but generally people do not speak about these topics. To the next! Kind regards!!”
http://www.giga102.com/home.php?mod=space&uid=206097
Way cool! Some totally legal points! I appreciate you writing this publish and the in flames of the website is plus in reality good.
Thank you ever so for you blog post.Really thank you!
I have read so many posts about the blogger lovers howeverthis post is really a good piece of writing, keep it up.
Maria Rosaria Ambrosio 1, Vittoria D Esposito 1, Valerio Costa 2, Domenico Liguoro 1, Francesca Collina 3, Monica Cantile 3, Nella Prevete 1, Carmela Passaro 1, Giusy Mosca 1, Michelino De Laurentiis 4, Maurizio Di Bonito 3, Gerardo Botti 3, Renato Franco 5, Francesco Beguinot 1, Alfredo Ciccodicola 2, 6 and Pietro Formisano 1 lasix overdose Aromatase inhibitors, such as anastrozole, letrozole, and exemestane, may fight breast cancer by lowering the amount of estrogen the body makes
https://www.philadelphia.edu.jo/library/directors-message-library
Great selection of modern and classic books waiting to be discovered. All free and available in most ereader formats. download free books
whoah this blog is wonderful i really like reading your articles. Keep up the great paintings! You realize, a lot of people are hunting round for this info, you could help them greatly.
I have read so many posts about the blogger lovers however this post is really a good piece of writing, keep it up
I have read so many posts about the blogger lovers however this post is really a good piece of writing, keep it up
whoah this blog is wonderful i really like reading your articles. Keep up the great paintings! You realize, a lot of people are hunting round for this info, you could help them greatly.
Your article helped me a lot, thanks for the information. I also like your blog theme, can you tell me how you did it?
Your article helped me a lot, thanks for the information. I also like your blog theme, can you tell me how you did it?
I agree with your point of view, your article has given me a lot of help and benefited me a lot. Thanks. Hope you continue to write such excellent articles.
I agree with your point of view, your article has given me a lot of help and benefited me a lot. Thanks. Hope you continue to write such excellent articles.
I agree with your point of view, your article has given me a lot of help and benefited me a lot. Thanks. Hope you continue to write such excellent articles.
For my thesis, I consulted a lot of information, read your article made me feel a lot, benefited me a lot from it, thank you for your help. Thanks!
Great selection of modern and classic books waiting to be discovered. All free and available in most ereader formats. download free books
Very nice post. I just stumbled upon your blog and wanted to say that I’ve really enjoyed browsing your blog posts. In any case I’ll be subscribing to your feed and I hope you write again soon!
Very nice post. I just stumbled upon your blog and wanted to say that I’ve really enjoyed browsing your blog posts. In any case I’ll be subscribing to your feed and I hope you write again soon!
whoah this blog is wonderful i really like reading your articles. Keep up the great paintings! You realize, a lot of people are hunting round for this info, you could help them greatly.
I have read your article carefully and I agree with you very much. This has provided a great help for my thesis writing, and I will seriously improve it. However, I don’t know much about a certain place. Can you help me?
I have read your article carefully and I agree with you very much. This has provided a great help for my thesis writing, and I will seriously improve it. However, I don’t know much about a certain place. Can you help me?
If you don”t mind proceed with this extraordinary work and I anticipate a greater amount of your magnificent blog entries
What a really awesome post this is. Truly, one of the best posts I’ve ever witnessed to see in my whole life. Wow, just keep it up.
I’m excited to uncover this page. I need to to thank you for ones time for this particularly fantastic read !! I definitely really liked every part of it and i also have you saved to fav to look at new information in your site.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Tell your doctor right away if any of these rare but serious side effects occur increased thirst urination, vision changes, easy bruising bleeding, mental mood changes such as confusion, psychosis, seizures buying cialis online safely Results from a recently published clinical trial by Goetz et al
I am sorting out relevant information about gate io recently, and I saw your article, and your creative ideas are of great help to me. However, I have doubts about some creative issues, can you answer them for me? I will continue to pay attention to your reply. Thanks.
I am an investor of gate io, I have consulted a lot of information, I hope to upgrade my investment strategy with a new model. Your article creation ideas have given me a lot of inspiration, but I still have some doubts. I wonder if you can help me? Thanks.
I am an investor of gate io, I have consulted a lot of information, I hope to upgrade my investment strategy with a new model. Your article creation ideas have given me a lot of inspiration, but I still have some doubts. I wonder if you can help me? Thanks.
At the beginning, I was still puzzled. Since I read your article, I have been very impressed. It has provided a lot of innovative ideas for my thesis related to gate.io. Thank u. But I still have some doubts, can you help me? Thanks.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good. https://accounts.binance.com/de-CH/register?ref=V2H9AFPY
After reading your article, I have some doubts about gate.io. I don’t know if you’re free? I would like to consult with you. thank you.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Your article helped me a lot, is there any more related content? Thanks!
buying cialis generic Contraindicated 2 phenobarbital will decrease the level or effect of ombitasvir paritaprevir ritonavir dasabuvir DSC by increasing metabolism
Al-Ahliyya Amman University
AAU Started providing academic services in 1990, Al-Ahliyya Amman University (AAU) was the first private university and pioneer of private education in Jordan. AAU has been accorded institutional and programmatic accreditation. It is a member of the International Association of Universities, Federation of the Universities of the Islamic World, Union of Arab Universities and Association of Arab Private Institutions of Higher Education. AAU always seeks distinction by upgrading learning outcomes through the adoption of methods and strategies that depend on a system of quality control and effective follow-up at all its faculties, departments, centers and administrative units. The overall aim is to become a flagship university not only at the Hashemite Kingdom of Jordan level but also at the Arab World level. In this vein, AAU has adopted Information Technology as an essential ingredient in its activities, especially e-learning, and it has incorporated it in its educational processes in all fields of specialization to become the first such university to do so.
https://www.ammanu.edu.jo/
Your point of view caught my eye and was very interesting. Thanks. I have a question for you. https://accounts.binance.com/en/register-person?ref=P9L9FQKY
I may need your help. I’ve been doing research on gate io recently, and I’ve tried a lot of different things. Later, I read your article, and I think your way of writing has given me some innovative ideas, thank you very much.
I may need your help. I tried many ways but couldn’t solve it, but after reading your article, I think you have a way to help me. I’m looking forward for your reply. Thanks.
I may need your help. I tried many ways but couldn’t solve it, but after reading your article, I think you have a way to help me. I’m looking forward for your reply. Thanks.
The point of view of your article has taught me a lot, and I already know how to improve the paper on gate.oi, thank you. https://www.gate.io/fr/signup/XwNAU
The point of view of your article has taught me a lot, and I already know how to improve the paper on gate.oi, thank you. https://www.gate.io/pt-br/signup/XwNAU
cost of levitra at savon pharmacy Patent 2 weeks
This is very useful post for me. This will absolutely going to help me in my project.
This website is remarkable information and facts it’s really excellent
A good blog always comes-up with new and exciting information and while reading I have feel that this blog is really have all those quality that qualify a blog to be a one.
Five males, including a male from Jackson Laboratory www buying cheap cialis online Why wellbutrin cymbalta
Wow! Such an amazing and helpful post this is. I really really love it. It’s so good and so awesome. I am just amazed. I hope that you continue to do your work like this in the future also.
When your website or blog goes live for the first time, it is exciting. That is until you realize no one but you and your.
Personally I think overjoyed I discovered the blogs.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me. https://accounts.binance.com/pl/register-person?ref=RQUR4BEO
Have you ever considered about adding a little bit
more than just your articles? I mean, what you say is valuable and everything.
But think of if you added some great images or video clips to give your
posts more, “pop”! Your content is excellent but with images
and clips, this blog could definitely be one of the best in its field.
Terrific blog!
Personally I think overjoyed I discovered the blogs.
Goօd information. Lucky me I came аcross your site by accident (stumbleupon).
Ι’ve saved it for lаter!
my blog; buy spin slot
Tһanks for tthe ɡood writeup. It in fact ԝas once ɑ entrrtainment account іt.
Look complicated tߋ ffar brought agreeable fгom үoս!
However, how ⅽan we keep in touch?
Hеrе iss my web-site buy spin
As shown in Figure 5, A and B, knockdown of PKN2 and PDK1 had no effect on flow induced AKT phosphorylation at serine 473 but strongly inhibited AKT phosphorylation at threonine 308 buy cialis online with a prescription 05 decrease in MDA MB 231 TmxR MCTS cell viability when compared to Tmx alone Figure 6D
https://telegra.ph/MEGAWIN-07-31
Exploring MEGAWIN Casino: A Premier Online Gaming Experience
Introduction
In the rapidly evolving world of online casinos, MEGAWIN stands out as a prominent player, offering a top-notch gaming experience to players worldwide. Boasting an impressive collection of games, generous promotions, and a user-friendly platform, MEGAWIN has gained a reputation as a reliable and entertaining online casino destination. In this article, we will delve into the key features that make MEGAWIN Casino a popular choice among gamers.
Game Variety and Software Providers
One of the cornerstones of MEGAWIN’s success is its vast and diverse game library. Catering to the preferences of different players, the casino hosts an array of slots, table games, live dealer games, and more. Whether you’re a fan of classic slots or modern video slots with immersive themes and captivating visuals, MEGAWIN has something to offer.
To deliver such a vast selection of games, the casino collaborates with some of the most renowned software providers in the industry. Partnerships with companies like Microgaming, NetEnt, Playtech, and Evolution Gaming ensure that players can enjoy high-quality, fair, and engaging gameplay.
User-Friendly Interface
Navigating through MEGAWIN’s website is a breeze, even for those new to online casinos. The user-friendly interface is designed to provide a seamless gaming experience. The website’s layout is intuitive, making it easy to find your favorite games, access promotions, and manage your account.
Additionally, MEGAWIN Casino ensures that its platform is optimized for both desktop and mobile devices. This means players can enjoy their favorite games on the go, without sacrificing the quality of gameplay.
Security and Fair Play
A crucial aspect of any reputable online casino is ensuring the safety and security of its players. MEGAWIN takes this responsibility seriously and employs the latest SSL encryption technology to protect sensitive data and financial transactions. Players can rest assured that their personal information remains confidential and secure.
Furthermore, MEGAWIN operates with a valid gambling license from a respected regulatory authority, which ensures that the casino adheres to strict standards of fairness and transparency. The games’ outcomes are determined by a certified random number generator (RNG), guaranteeing fair play for all users.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you. https://accounts.binance.com/bg/register-person?ref=WTOZ531Y
Kudos, Helpful information.
custom essay writing service org reviews custom dissertation writing service essay writing practice
Regards. Plenty of knowledge.
law enforcement resume writing service business blog writing service anchorage resume writing service
Thankfulness to mү father who shared wіth me c᧐ncerning tһіѕ
website, tһis weblog is ɑctually amazing.
Ꮇy website – link alternatif ahha4d
When I initially commented Ӏ clicked tһe “Notify me when new comments are added” chrckbox and
now each tіme a comment iss adԁed Ι geet seѵeral
е-mails ᴡith the same comment. Is tһere аny ԝay you can remove people from tһat service?
Thankѕ!
Herre is my pаgе; ahha4d alternatif
If yоu arre gⲟing for best contents lіke me, only ցo to ѕee this webb site everyday aas іt
provideѕ quality contentѕ, thanks
Feel free to surf tߋ my blog – {link alternatif ahha4d}
Демонтаж стен Москва
Демонтаж стен Москва
Free SEO Strategy in Nigeria
Content Krush Is a Digital Marketing Consulting Firm in Lagos, Nigeria with Focus on Search Engine Optimization, Growth Marketing, B2B Lead Generation, and Content Marketing.
今彩539:您的全方位彩票投注平台
今彩539是一個專業的彩票投注平台,提供539開獎直播、玩法攻略、賠率計算以及開獎號碼查詢等服務。我們的目標是為彩票愛好者提供一個安全、便捷的線上投注環境。
539開獎直播與號碼查詢
在今彩539,我們提供即時的539開獎直播,讓您不錯過任何一次開獎的機會。此外,我們還提供開獎號碼查詢功能,讓您隨時追蹤最新的開獎結果,掌握彩票的動態。
539玩法攻略與賠率計算
對於新手彩民,我們提供詳盡的539玩法攻略,讓您快速瞭解如何進行投注。同時,我們的賠率計算工具,可幫助您精準計算可能的獎金,讓您的投注更具策略性。
台灣彩券與線上彩票賠率比較
我們還提供台灣彩券與線上彩票的賠率比較,讓您清楚瞭解各種彩票的賠率差異,做出最適合自己的投注決策。
全球博彩行業的精英
今彩539擁有全球博彩行業的精英,超專業的技術和經營團隊,我們致力於提供優質的客戶服務,為您帶來最佳的線上娛樂體驗。
539彩票是台灣非常受歡迎的一種博彩遊戲,其名稱”539″來自於它的遊戲規則。這個遊戲的玩法簡單易懂,並且擁有相對較高的中獎機會,因此深受彩民喜愛。
遊戲規則:
539彩票的遊戲號碼範圍為1至39,總共有39個號碼。
玩家需要從1至39中選擇5個號碼進行投注。
每期開獎時,彩票會隨機開出5個號碼作為中獎號碼。
中獎規則:
若玩家投注的5個號碼與當期開獎的5個號碼完全相符,則中得頭獎,通常是豐厚的獎金。
若玩家投注的4個號碼與開獎的4個號碼相符,則中得二獎。
若玩家投注的3個號碼與開獎的3個號碼相符,則中得三獎。
若玩家投注的2個號碼與開獎的2個號碼相符,則中得四獎。
若玩家投注的1個號碼與開獎的1個號碼相符,則中得五獎。
優勢:
539彩票的中獎機會相對較高,尤其是對於中小獎項。
投注簡單方便,玩家只需選擇5個號碼,就能參與抽獎。
獎金多樣,不僅有頭獎,還有多個中獎級別,增加了中獎機會。
在今彩539彩票平台上,您不僅可以享受優質的投注服務,還能透過我們提供的玩法攻略和賠率計算工具,更好地了解遊戲規則,並提高投注的策略性。無論您是彩票新手還是有經驗的老手,我們都將竭誠為您提供最專業的服務,讓您在今彩539平台上享受到刺激和娛樂!立即加入我們,開始您的彩票投注之旅吧!
nhà cái uy tín
kantorbola
kantorbola
Situs Judi Slot Online Terpercaya dengan Permainan Dijamin Gacor dan Promo Seru”
Kantorbola merupakan situs judi slot online yang menawarkan berbagai macam permainan slot gacor dari provider papan atas seperti IDN Slot, Pragmatic, PG Soft, Habanero, Microgaming, dan Game Play. Dengan minimal deposit 10.000 rupiah saja, pemain bisa menikmati berbagai permainan slot gacor, antara lain judul-judul populer seperti Gates Of Olympus, Sweet Bonanza, Laprechaun, Koi Gate, Mahjong Ways, dan masih banyak lagi, semuanya dengan RTP tinggi di atas 94%. Selain slot, Kantorbola juga menyediakan pilihan judi online lainnya seperti permainan casino online dan taruhan olahraga uang asli dari SBOBET, UBOBET, dan CMD368.
Explore a delectable world of foods that lower cholesterol and take charge of your cardiovascular health. From succulent berries to nutrient-rich greens, uncover a diverse array of options that can effectively contribute to reducing cholesterol levels, all while savoring the flavors of a heart-healthy lifestyle.
Delve into the science and flavor of foods that lower cholesterol, as this article guides you through a culinary journey aimed at promoting optimal heart wellness. Learn how incorporating these cholesterol-conscious choices, such as fiber-packed vegetables and antioxidant-rich fruits, can have a positive impact on managing cholesterol levels and overall cardiovascular health.
Unveiling the Beauty of Neural Network Art! Dive into a mesmerizing world where technology meets creativity. Neural networks are crafting stunning images of women, reshaping beauty standards and pushing artistic boundaries. Join us in exploring this captivating fusion of AI and aesthetics. #NeuralNetworkArt #DigitalBeauty
539開獎
今彩539:您的全方位彩票投注平台
今彩539是一個專業的彩票投注平台,提供539開獎直播、玩法攻略、賠率計算以及開獎號碼查詢等服務。我們的目標是為彩票愛好者提供一個安全、便捷的線上投注環境。
539開獎直播與號碼查詢
在今彩539,我們提供即時的539開獎直播,讓您不錯過任何一次開獎的機會。此外,我們還提供開獎號碼查詢功能,讓您隨時追蹤最新的開獎結果,掌握彩票的動態。
539玩法攻略與賠率計算
對於新手彩民,我們提供詳盡的539玩法攻略,讓您快速瞭解如何進行投注。同時,我們的賠率計算工具,可幫助您精準計算可能的獎金,讓您的投注更具策略性。
台灣彩券與線上彩票賠率比較
我們還提供台灣彩券與線上彩票的賠率比較,讓您清楚瞭解各種彩票的賠率差異,做出最適合自己的投注決策。
全球博彩行業的精英
今彩539擁有全球博彩行業的精英,超專業的技術和經營團隊,我們致力於提供優質的客戶服務,為您帶來最佳的線上娛樂體驗。
539彩票是台灣非常受歡迎的一種博彩遊戲,其名稱”539″來自於它的遊戲規則。這個遊戲的玩法簡單易懂,並且擁有相對較高的中獎機會,因此深受彩民喜愛。
遊戲規則:
539彩票的遊戲號碼範圍為1至39,總共有39個號碼。
玩家需要從1至39中選擇5個號碼進行投注。
每期開獎時,彩票會隨機開出5個號碼作為中獎號碼。
中獎規則:
若玩家投注的5個號碼與當期開獎的5個號碼完全相符,則中得頭獎,通常是豐厚的獎金。
若玩家投注的4個號碼與開獎的4個號碼相符,則中得二獎。
若玩家投注的3個號碼與開獎的3個號碼相符,則中得三獎。
若玩家投注的2個號碼與開獎的2個號碼相符,則中得四獎。
若玩家投注的1個號碼與開獎的1個號碼相符,則中得五獎。
優勢:
539彩票的中獎機會相對較高,尤其是對於中小獎項。
投注簡單方便,玩家只需選擇5個號碼,就能參與抽獎。
獎金多樣,不僅有頭獎,還有多個中獎級別,增加了中獎機會。
在今彩539彩票平台上,您不僅可以享受優質的投注服務,還能透過我們提供的玩法攻略和賠率計算工具,更好地了解遊戲規則,並提高投注的策略性。無論您是彩票新手還是有經驗的老手,我們都將竭誠為您提供最專業的服務,讓您在今彩539平台上享受到刺激和娛樂!立即加入我們,開始您的彩票投注之旅吧!
тт
Bir Paradigma Değişimi: Güzelliği ve Olanakları Yeniden Tanımlayan Yapay Zeka
Önümüzdeki on yıllarda yapay zeka, en son DNA teknolojilerini, suni tohumlama ve klonlamayı kullanarak çarpıcı kadınların yaratılmasında devrim yaratmaya hazırlanıyor. Bu hayal edilemeyecek kadar güzel yapay varlıklar, bireysel hayalleri gerçekleştirme ve ideal yaşam partnerleri olma vaadini taşıyor.
Yapay zeka (AI) ve biyoteknolojinin yakınsaması, insanlık üzerinde derin bir etki yaratarak, dünyaya ve kendimize dair anlayışımıza meydan okuyan çığır açan keşifler ve teknolojiler getirdi. Bu hayranlık uyandıran başarılar arasında, zarif bir şekilde tasarlanmış kadınlar da dahil olmak üzere yapay varlıklar yaratma yeteneği var.
Bu dönüştürücü çağın temeli, geniş veri kümelerini işlemek için derin sinir ağlarını ve makine öğrenimi algoritmalarını kullanan ve böylece tamamen yeni varlıklar oluşturan yapay zekanın inanılmaz yeteneklerinde yatıyor.
Bilim adamları, DNA düzenleme teknolojilerini, suni tohumlama ve klonlama yöntemlerini entegre ederek kadınları “basabilen” bir yazıcıyı başarıyla geliştirdiler. Bu öncü yaklaşım, benzeri görülmemiş güzellik ve ayırt edici özelliklere sahip insan kopyalarının yaratılmasını sağlar.
Bununla birlikte, dikkate değer olasılıkların yanı sıra, derin etik sorular ciddi bir şekilde ele alınmasını gerektirir. Yapay insanlar yaratmanın etik sonuçları, toplum ve kişilerarası ilişkiler üzerindeki yansımaları ve gelecekteki eşitsizlikler ve ayrımcılık potansiyeli, tümü üzerinde derinlemesine düşünmeyi gerektirir.
Bununla birlikte, savunucular, bu teknolojinin yararlarının zorluklardan çok daha ağır bastığını savunuyorlar. Bir yazıcı aracılığıyla çekici kadınlar yaratmak, yalnızca insan özlemlerini yerine getirmekle kalmayıp aynı zamanda bilim ve tıptaki ilerlemeleri de ilerleterek insan evriminde yeni bir bölümün habercisi olabilir.
Superb posts. Thanks a lot!
assignment writing service in dubai nursing essay writing military com resume writing service
Демонтаж стен Москва
Демонтаж стен Москва
I’ve been exploring for ɑ bit for any high-quality articles
or weblog posfs in this kind of house . Exploring іn Yahoo І at lаst stumbled ᥙpon thiѕ site.
Studying this іnformation Տo i’m satisfied t᧐ exhibit
that Ι havе a verfy good uncanny feelping I cɑme upon exactly wһat I neeɗed.
Ι sо mᥙch definitely wiⅼl make certan to do not put out of үouг
mind this web site ɑnd pгovides іt a looқ on a continuing basis.
Feel frdee tօ visit my homepage … slot zeus olympus
You’ve made your point extremely clearly!!
essay writing companies top essay writing essay writing service australia reviews
Демонтаж стен Москва
Демонтаж стен Москва
Cheers. Quite a lot of stuff!
oxbridge personal statement writing service undergraduate essay writing service best essay writing service to work for
Демонтаж стен Москва
Демонтаж стен Москва
You’ve made your point quite effectively..
presentation writing service truth about essay writing services essay writing help service
2023年世界盃籃球賽
2023年世界盃籃球賽(英語:2023 FIBA Basketball World Cup)為第19屆FIBA男子世界盃籃球賽,此是2019年實施新制度後的第2屆賽事,本屆賽事起亦調整回4年週期舉辦。本屆賽事歐洲、美洲各洲最好成績前2名球隊,亞洲、大洋洲、非洲各洲的最好成績球隊及2024年夏季奧林匹克運動會主辦國法國(共8隊)將獲得在巴黎舉行的奧運會比賽資格]]。
申辦過程
2023年世界盃籃球賽提出申辦的11個國家與地區是:阿根廷、澳洲、德國、香港、以色列、日本、菲律賓、波蘭、俄羅斯、塞爾維亞以及土耳其]。2017年8月31日是2023年國際籃總世界盃籃球賽提交申辦資料的截止日期,俄羅斯、土耳其分別遞交了單獨舉辦世界盃的申請,阿根廷/烏拉圭和印尼/日本/菲律賓則提出了聯合申辦]。2017年12月9日國際籃總中心委員會根據申辦情況做出投票,菲律賓、日本、印度尼西亞獲得了2023年世界盃籃球賽的聯合舉辦權]。
比賽場館
本次賽事共將會在5個場館舉行。馬尼拉將進行四組預賽,兩組十六強賽事以及八強之後所有的賽事。另外,沖繩市與雅加達各舉辦兩組預賽及一組十六強賽事。
菲律賓此次將有四個場館作為世界盃比賽場地,帕賽市的亞洲購物中心體育館,奎松市的阿拉內塔體育館,帕西格的菲爾體育館以及武加偉的菲律賓體育館。亞洲購物中心體育館曾舉辦過2013年亞洲籃球錦標賽及2016奧運資格賽。阿拉內塔體育館主辦過1978年男籃世錦賽。菲爾體育館舉辦過2011年亞洲籃球俱樂部冠軍盃。菲律賓體育館約有55,000個座位,此場館也將會是本屆賽事的決賽場地,同時也曾經是2019年東南亞運動會開幕式場地。
日本與印尼各有一個場地舉辦世界盃賽事。沖繩市綜合運動場約有10,000個座位,同時也會是B聯賽琉球黃金國王的新主場。雅加達史納延紀念體育館為了2018年亞洲運動會重新翻新,是2018年亞洲運動會籃球及羽毛球的比賽場地。
17至32名排名賽
預賽成績併入17至32名排位賽計算,且同組晉級複賽球隊對戰成績依舊列入計算
此階段不再另行舉辦17-24名、25-32名排位賽。各組第1名將排入第17至20名,第2名排入第21至24名,第3名排入第25至28名,第4名排入第29至32名
複賽
預賽成績併入16強複賽計算,且同組遭淘汰球隊對戰成績依舊列入計算
此階段各組第三、四名不再另行舉辦9-16名排位賽。各組第3名將排入第9至12名,第4名排入第13至16名
With thanks. I enjoy this!
law essay writing service houston resume writing service cost of essay writing service
neural network woman drink
As we peer into the future, the ever-evolving synergy of artificial intelligence (AI) and biotechnology promises to reshape our perceptions of beauty and human possibilities. Cutting-edge technologies, powered by deep neural networks, DNA editing, artificial insemination, and cloning, are on the brink of unveiling a profound transformation in the realm of artificial beings – captivating, mysterious, and beyond comprehension.
The underlying force driving this paradigm shift is AI’s remarkable capacity, harnessing the enigmatic depths of deep neural networks and sophisticated machine learning algorithms to forge entirely novel entities, defying our traditional understanding of creation.
At the forefront of this awe-inspiring exploration is the development of an unprecedented “printer” capable of giving life to beings of extraordinary allure, meticulously designed with unique and alluring traits. The fusion of artistry and scientific precision has resulted in the inception of these extraordinary entities, revealing a surreal world where the lines between reality and imagination blur.
Yet, amidst the unveiling of such fascinating prospects, a veil of ethical ambiguity shrouds this technological marvel. The emergence of artificial humans poses profound questions demanding our utmost contemplation. Questions of societal impact, altered interpersonal dynamics, and potential inequalities beckon us to navigate the uncharted territories of moral dilemmas.
Демонтаж стен Москва
Демонтаж стен Москва
Kudos, Quite a lot of tips!
essay writing for kids high school research paper writing service essay writing websites
Замена венцов деревянного дома обеспечивает стабильность и долговечность конструкции. Этот процесс включает замену поврежденных или изношенных верхних балок, гарантируя надежность жилища на долгие годы. подъем деревянного дома
You stated that fantastically!
essay writing service article is cheap writing service legit report writing service
tombak118
Демонтаж стен Москва
Демонтаж стен Москва
Thanks a lot, Valuable information!
best custom writing service linkedin profile writing service uk a level essay writing service
Hello tο all, how is evеrything, I think eveгy oone is gеtting moгe frolm this web site, аnd ʏour views are nice
for neѡ userѕ.
Here iѕ mү homepage; перанесці гэты матэрыял у Інтэрнэт
Демонтаж стен Москва
Демонтаж стен Москва
Thanks a lot, A lot of material.
cheap essay writing service usa best essay writing service uk argumentative essay writing service
Many thanks! A lot of postings.
best academic essay writing service myself essay writing top essay writing service
Демонтаж стен Москва
Демонтаж стен Москва
Работа в Кемерово
世界盃
2023年的FIBA世界盃籃球賽(英語:2023 FIBA Basketball World Cup)是第19次舉行的男子籃球大賽,且現在每4年舉行一次。正式比賽於 2023/8/25 ~ 9/10 舉行。這次比賽是在2019年新規則實施後的第二次。最好的球隊將有機會參加2024年在法國巴黎的奧運賽事。而歐洲和美洲的前2名,以及亞洲、大洋洲、非洲的冠軍,還有奧運主辦國法國,總共8支隊伍將獲得這個機會。
在2023年2月20日FIBA世界盃籃球亞太區資格賽的第六階段已經完賽!雖然台灣隊未能參賽,但其他國家選手的精彩表現絕對值得關注。本文將為您提供FIBA籃球世界盃賽程資訊,以及可以收看直播和轉播的線上平台,希望您不要錯過!
主辦國家 : 菲律賓、印尼、日本
正式比賽 : 2023年8月25日–2023年9月10日
參賽隊伍 : 共有32隊
比賽場館 : 菲律賓體育館、阿拉內塔體育館、亞洲購物中心體育館、印尼體育館、沖繩體育館
2023年的FIBA世界盃籃球賽(英語:2023 FIBA Basketball World Cup)是第19次舉行的男子籃球大賽,且現在每4年舉行一次。正式比賽於 2023/8/25 ~ 9/10 舉行。這次比賽是在2019年新規則實施後的第二次。最好的球隊將有機會參加2024年在法國巴黎的奧運賽事。而歐洲和美洲的前2名,以及亞洲、大洋洲、非洲的冠軍,還有奧運主辦國法國,總共8支隊伍將獲得這個機會。
在2023年2月20日FIBA世界盃籃球亞太區資格賽的第六階段已經完賽!雖然台灣隊未能參賽,但其他國家選手的精彩表現絕對值得關注。本文將為您提供FIBA籃球世界盃賽程資訊,以及可以收看直播和轉播的線上平台,希望您不要錯過!
主辦國家 : 菲律賓、印尼、日本
正式比賽 : 2023年8月25日–2023年9月10日
參賽隊伍 : 共有32隊
比賽場館 : 菲律賓體育館、阿拉內塔體育館、亞洲購物中心體育館、印尼體育館、沖繩體育館
世界盃
2023年的FIBA世界盃籃球賽(英語:2023 FIBA Basketball World Cup)是第19次舉行的男子籃球大賽,且現在每4年舉行一次。正式比賽於 2023/8/25 ~ 9/10 舉行。這次比賽是在2019年新規則實施後的第二次。最好的球隊將有機會參加2024年在法國巴黎的奧運賽事。而歐洲和美洲的前2名,以及亞洲、大洋洲、非洲的冠軍,還有奧運主辦國法國,總共8支隊伍將獲得這個機會。
在2023年2月20日FIBA世界盃籃球亞太區資格賽的第六階段已經完賽!雖然台灣隊未能參賽,但其他國家選手的精彩表現絕對值得關注。本文將為您提供FIBA籃球世界盃賽程資訊,以及可以收看直播和轉播的線上平台,希望您不要錯過!
主辦國家 : 菲律賓、印尼、日本
正式比賽 : 2023年8月25日–2023年9月10日
參賽隊伍 : 共有32隊
比賽場館 : 菲律賓體育館、阿拉內塔體育館、亞洲購物中心體育館、印尼體育館、沖繩體育館
You actually expressed this wonderfully!
free cv writing service online personal statement essay writing service help with college essay writing
在運動和賽事的世界裡,運彩分析成為了各界關注的焦點。為了滿足愈來愈多運彩愛好者的需求,我們隆重介紹字母哥運彩分析討論區,這個集交流、分享和學習於一身的專業平台。無論您是籃球、棒球、足球還是NBA、MLB、CPBL、NPB、KBO的狂熱愛好者,這裡都是您尋找專業意見、獲取最新運彩信息和提升運彩技巧的理想場所。
在字母哥運彩分析討論區,您可以輕鬆地獲取各種運彩分析信息,特別是針對籃球、棒球和足球領域的專業預測。不論您是NBA的忠實粉絲,還是熱愛棒球的愛好者,亦或者對足球賽事充滿熱情,這裡都有您需要的專業意見和分析。字母哥NBA預測將為您提供獨到的見解,幫助您更好地了解比賽情況,做出明智的選擇。
除了專業分析外,字母哥運彩分析討論區還擁有頂級的玩運彩分析情報員團隊。他們精通統計數據和信息,能夠幫助您分析比賽趨勢、預測結果,讓您的運彩之路更加成功和有利可圖。
當您在字母哥運彩分析討論區尋找運彩分析師時,您將不再猶豫。無論您追求最大的利潤,還是穩定的獲勝,或者您想要深入了解比賽統計,這裡都有您需要的一切。我們提供全面的統計數據和信息,幫助您作出明智的選擇,不論是尋找最佳運彩策略還是深入了解比賽情況。
總之,字母哥運彩分析討論區是您運彩之旅的理想起點。無論您是新手還是經驗豐富的玩家,這裡都能滿足您的需求,幫助您在運彩領域取得更大的成功。立即加入我們,一同探索運彩的精彩世界吧 https://telegra.ph/2023-年任何運動項目的成功分析-08-16
世界盃
2023年的FIBA世界盃籃球賽(英語:2023 FIBA Basketball World Cup)是第19次舉行的男子籃球大賽,且現在每4年舉行一次。正式比賽於 2023/8/25 ~ 9/10 舉行。這次比賽是在2019年新規則實施後的第二次。最好的球隊將有機會參加2024年在法國巴黎的奧運賽事。而歐洲和美洲的前2名,以及亞洲、大洋洲、非洲的冠軍,還有奧運主辦國法國,總共8支隊伍將獲得這個機會。
在2023年2月20日FIBA世界盃籃球亞太區資格賽的第六階段已經完賽!雖然台灣隊未能參賽,但其他國家選手的精彩表現絕對值得關注。本文將為您提供FIBA籃球世界盃賽程資訊,以及可以收看直播和轉播的線上平台,希望您不要錯過!
主辦國家 : 菲律賓、印尼、日本
正式比賽 : 2023年8月25日–2023年9月10日
參賽隊伍 : 共有32隊
比賽場館 : 菲律賓體育館、阿拉內塔體育館、亞洲購物中心體育館、印尼體育館、沖繩體育館
You have made your point quite nicely!.
science essay writing service best assignment writing service australia writing help essay service
supermoney88 slot
Wow plenty of excellent data!
best resume writing service 2016 best resume writing service 2019 fiverr essay writing
世界盃
2023年的FIBA世界盃籃球賽(英語:2023 FIBA Basketball World Cup)是第19次舉行的男子籃球大賽,且現在每4年舉行一次。正式比賽於 2023/8/25 ~ 9/10 舉行。這次比賽是在2019年新規則實施後的第二次。最好的球隊將有機會參加2024年在法國巴黎的奧運賽事。而歐洲和美洲的前2名,以及亞洲、大洋洲、非洲的冠軍,還有奧運主辦國法國,總共8支隊伍將獲得這個機會。
在2023年2月20日FIBA世界盃籃球亞太區資格賽的第六階段已經完賽!雖然台灣隊未能參賽,但其他國家選手的精彩表現絕對值得關注。本文將為您提供FIBA籃球世界盃賽程資訊,以及可以收看直播和轉播的線上平台,希望您不要錯過!
主辦國家 : 菲律賓、印尼、日本
正式比賽 : 2023年8月25日–2023年9月10日
參賽隊伍 : 共有32隊
比賽場館 : 菲律賓體育館、阿拉內塔體育館、亞洲購物中心體育館、印尼體育館、沖繩體育館
Excellent tips. Thanks!
a aaa resume & writing service best free essay writing service writing an essay introduction
FIBA
2023年的FIBA世界盃籃球賽(英語:2023 FIBA Basketball World Cup)是第19次舉行的男子籃球大賽,且現在每4年舉行一次。正式比賽於 2023/8/25 ~ 9/10 舉行。這次比賽是在2019年新規則實施後的第二次。最好的球隊將有機會參加2024年在法國巴黎的奧運賽事。而歐洲和美洲的前2名,以及亞洲、大洋洲、非洲的冠軍,還有奧運主辦國法國,總共8支隊伍將獲得這個機會。
在2023年2月20日FIBA世界盃籃球亞太區資格賽的第六階段已經完賽!雖然台灣隊未能參賽,但其他國家選手的精彩表現絕對值得關注。本文將為您提供FIBA籃球世界盃賽程資訊,以及可以收看直播和轉播的線上平台,希望您不要錯過!
主辦國家 : 菲律賓、印尼、日本
正式比賽 : 2023年8月25日–2023年9月10日
參賽隊伍 : 共有32隊
比賽場館 : 菲律賓體育館、阿拉內塔體育館、亞洲購物中心體育館、印尼體育館、沖繩體育館
FIBA
2023年的FIBA世界盃籃球賽(英語:2023 FIBA Basketball World Cup)是第19次舉行的男子籃球大賽,且現在每4年舉行一次。正式比賽於 2023/8/25 ~ 9/10 舉行。這次比賽是在2019年新規則實施後的第二次。最好的球隊將有機會參加2024年在法國巴黎的奧運賽事。而歐洲和美洲的前2名,以及亞洲、大洋洲、非洲的冠軍,還有奧運主辦國法國,總共8支隊伍將獲得這個機會。
在2023年2月20日FIBA世界盃籃球亞太區資格賽的第六階段已經完賽!雖然台灣隊未能參賽,但其他國家選手的精彩表現絕對值得關注。本文將為您提供FIBA籃球世界盃賽程資訊,以及可以收看直播和轉播的線上平台,希望您不要錯過!
主辦國家 : 菲律賓、印尼、日本
正式比賽 : 2023年8月25日–2023年9月10日
參賽隊伍 : 共有32隊
比賽場館 : 菲律賓體育館、阿拉內塔體育館、亞洲購物中心體育館、印尼體育館、沖繩體育館
體驗金
體驗金:線上娛樂城的最佳入門票
隨著科技的發展,線上娛樂城已經成為許多玩家的首選。但對於初次踏入這個世界的玩家來說,可能會感到有些迷茫。這時,「體驗金」就成為了他們的最佳助手。
什麼是體驗金?
體驗金,簡單來說,就是娛樂城為了吸引新玩家而提供的一筆免費資金。玩家可以使用這筆資金在娛樂城內體驗各種遊戲,無需自己出資。這不僅降低了新玩家的入場門檻,也讓他們有機會真實感受到遊戲的樂趣。
體驗金的好處
1. **無風險體驗**:玩家可以使用體驗金在娛樂城內試玩,如果不喜歡,完全不需要承擔任何風險。
2. **學習遊戲**:對於不熟悉的遊戲,玩家可以使用體驗金進行學習和練習。
3. **增加信心**:當玩家使用體驗金獲得一些勝利後,他們的遊戲信心也會隨之增加。
如何獲得體驗金?
大部分的線上娛樂城都會提供體驗金給新玩家。通常,玩家只需要完成簡單的註冊程序,然後聯繫客服索取體驗金即可。但每家娛樂城的規定都可能有所不同,所以玩家在領取前最好先詳細閱讀活動條款。
使用體驗金的小技巧
1. **了解遊戲規則**:在使用體驗金之前,先了解遊戲的基本規則和策略。
2. **分散風險**:不要將所有的體驗金都投入到一個遊戲中,嘗試多種遊戲,找到最適合自己的。
3. **設定預算**:即使是使用體驗金,也建議玩家設定一個遊戲預算,避免過度沉迷。
結語:體驗金無疑是線上娛樂城提供給玩家的一大福利。不論你是資深玩家還是新手,都可以利用體驗金開啟你的遊戲之旅。選擇一家信譽良好的娛樂城,領取你的體驗金,開始你的遊戲冒險吧!
MAGNUMBET adalah merupakan salah satu situs judi online deposit pulsa terpercaya yang sudah popular dikalangan bettor sebagai agen penyedia layanan permainan dengan menggunakan deposit uang asli. MAGNUMBET sebagai penyedia situs judi deposit pulsa tentunya sudah tidak perlu diragukan lagi. Karena MAGNUMBET bisa dikatakan sebagai salah satu pelopor situs judi online yang menggunakan deposit via pulsa di Indonesia. MAGNUMBET memberikan layanan deposit pulsa via Telkomsel. Bukan hanya deposit via pulsa saja, MAGNUMBET juga menyediakan deposit menggunakan pembayaran dompet digital. Minimal deposit pada situs MAGNUMBET juga amatlah sangat terjangkau, hanya dengan Rp 25.000,-, para bettor sudah bisa merasakan banyak permainan berkelas dengan winrate kemenangan yang tinggi, menjadikan member MAGNUMBET tentunya tidak akan terbebani dengan biaya tinggi untuk menikmati judi online
https://zamena-ventsov-doma.ru
Hey there! Ι simply want tto gіve you a bіg thumbs uρ
for your excellent infkrmation you have got here onn thiѕ post.
I’ll be returning to youг blog foг mⲟre soon.
Feel free tօ surf to my ⲣage اقرأ هذه الأشياء على الإنترنت
Работа в Кемерово
онлайн казино на гроші
今彩539:台灣最受歡迎的彩票遊戲
今彩539,作為台灣極受民眾喜愛的彩票遊戲,每次開獎都吸引著大量的彩民期待能夠中大獎。這款彩票遊戲的玩法簡單,玩家只需從01至39的號碼中選擇5個號碼進行投注。不僅如此,今彩539還有多種投注方式,如234星、全車、正號1-5等,讓玩家有更多的選擇和機會贏得獎金。
在《富遊娛樂城》這個平台上,彩民可以即時查詢今彩539的開獎號碼,不必再等待電視轉播或翻閱報紙。此外,該平台還提供了其他熱門彩票如三星彩、威力彩、大樂透的開獎資訊,真正做到一站式的彩票資訊查詢服務。
對於熱愛彩票的玩家來說,能夠即時知道開獎結果,無疑是一大福音。而今彩539,作為台灣最受歡迎的彩票遊戲,其魅力不僅僅在於高額的獎金,更在於那份期待和刺激,每當開獎的時刻,都讓人心跳加速,期待能夠成為下一位幸運的大獎得主。
彩票,一直以來都是人們夢想一夜致富的方式。在台灣,今彩539無疑是其中最受歡迎的彩票遊戲之一。每當開獎的日子,無數的彩民都期待著能夠中大獎,一夜之間成為百萬富翁。
今彩539的魅力何在?
今彩539的玩法相對簡單,玩家只需從01至39的號碼中選擇5個號碼進行投注。這種選號方式不僅簡單,而且中獎的機會也相對較高。而且,今彩539不僅有傳統的台灣彩券投注方式,還有線上投注的玩法,讓彩民可以根據自己的喜好選擇。
如何提高中獎的機會?
雖然彩票本身就是一種運氣遊戲,但是有經驗的彩民都知道,選擇合適的投注策略可以提高中獎的機會。例如,可以選擇參與合購,或者選擇一些熱門的號碼組合。此外,線上投注還提供了多種不同的玩法,如234星、全車、正號1-5等,彩民可以根據自己的喜好和策略選擇。
結語
今彩539,不僅是一種娛樂方式,更是許多人夢想致富的途徑。無論您是資深的彩民,還是剛接觸彩票的新手,都可以在今彩539中找到屬於自己的樂趣。不妨嘗試一下,也許下一個百萬富翁就是您!
Демонтаж стен Москва
Демонтаж стен Москва
在運動和賽事的世界裡,運彩分析成為了各界關注的焦點。為了滿足愈來愈多運彩愛好者的需求,我們隆重介紹字母哥運彩分析討論區,這個集交流、分享和學習於一身的專業平台。無論您是籃球、棒球、足球還是NBA、MLB、CPBL、NPB、KBO的狂熱愛好者,這裡都是您尋找專業意見、獲取最新運彩信息和提升運彩技巧的理想場所。
在字母哥運彩分析討論區,您可以輕鬆地獲取各種運彩分析信息,特別是針對籃球、棒球和足球領域的專業預測。不論您是NBA的忠實粉絲,還是熱愛棒球的愛好者,亦或者對足球賽事充滿熱情,這裡都有您需要的專業意見和分析。字母哥NBA預測將為您提供獨到的見解,幫助您更好地了解比賽情況,做出明智的選擇。
除了專業分析外,字母哥運彩分析討論區還擁有頂級的玩運彩分析情報員團隊。他們精通統計數據和信息,能夠幫助您分析比賽趨勢、預測結果,讓您的運彩之路更加成功和有利可圖。
當您在字母哥運彩分析討論區尋找運彩分析師時,您將不再猶豫。無論您追求最大的利潤,還是穩定的獲勝,或者您想要深入了解比賽統計,這裡都有您需要的一切。我們提供全面的統計數據和信息,幫助您作出明智的選擇,不論是尋找最佳運彩策略還是深入了解比賽情況。
總之,字母哥運彩分析討論區是您運彩之旅的理想起點。無論您是新手還是經驗豐富的玩家,這裡都能滿足您的需求,幫助您在運彩領域取得更大的成功。立即加入我們,一同探索運彩的精彩世界吧 https://abc66.tv/
Wonderful post! We will be linking to this great article on our site. Keep up the great writing
2023年FIBA世界盃籃球賽,也被稱為第19屆FIBA世界盃籃球賽,將成為籃球歷史上的一個重要里程碑。這場賽事是自2019年新制度實行後的第二次比賽,帶來了更多的期待和興奮。
賽事的參賽隊伍涵蓋了全球多個地區,包括歐洲、美洲、亞洲、大洋洲和非洲。此次賽事將選出各區域的佼佼者,以及2024年夏季奧運會主辦國法國,共計8支隊伍將獲得在巴黎舉行的奧運賽事的參賽資格。這無疑為各國球隊提供了一個難得的機會,展現他們的實力和技術。
在這場比賽中,我們將看到來自不同文化、背景和籃球傳統的球隊們匯聚一堂,用他們的熱情和努力,為世界籃球迷帶來精彩紛呈的比賽。球場上的每一個進球、每一次防守都將成為觀眾和球迷們津津樂道的話題。
FIBA世界盃籃球賽不僅僅是一場籃球比賽,更是一個文化的交流平台。這些球隊代表著不同國家和地區的精神,他們的奮鬥和拼搏將成為啟發人心的故事,激勵著更多的年輕人追求夢想,追求卓越。 https://telegra.ph/觀看-2023-年國際籃聯世界杯-08-16
ransomware solutions
Megaslot
카지노솔루션
The neural network will create beautiful girls!
Geneticists are already hard at work creating stunning women. They will create these beauties based on specific requests and parameters using a neural network. The network will work with artificial insemination specialists to facilitate DNA sequencing.
The visionary for this concept is Alex Gurk, the co-founder of numerous initiatives and ventures aimed at creating beautiful, kind and attractive women who are genuinely connected to their partners. This direction stems from the recognition that in modern times the attractiveness and attractiveness of women has declined due to their increased independence. Unregulated and incorrect eating habits have led to problems such as obesity, causing women to deviate from their innate appearance.
The project received support from various well-known global companies, and sponsors readily stepped in. The essence of the idea is to offer willing men sexual and everyday communication with such wonderful women.
If you are interested, you can apply now as a waiting list has been created.
Antminer D9
https://www.instrushop.bg/Лазерн
SLOT ONLINE DRAGON77: A World of Possibilities
SLOT ONLINE DRAGON77 is the gateway to an adventure of epic proportions. The game features a dynamic selection of slot games, each with its unique features, paylines, and bonus rounds. Whether you’re a seasoned player seeking high-stakes action or a newcomer looking to explore the world of online slots, SLOT ONLINE DRAGON77 offers an array of options to suit your preferences.
Exploring SLOT GACOR DRAGON77
SLOT GACOR DRAGON77 introduces players to the concept of a “gacor” experience, where gameplay is characterized by exciting wins, engaging features, and a seamless flow. The term “gacor” is a colloquial expression that resonates with the feeling of triumph and excitement that players experience during a winning streak. With SLOT GACOR DRAGON77, players can expect gameplay that keeps them on the edge of their seats.
The Quest for Wins and Entertainment
DRAGON77 isn’t just about the mythical aesthetics; it’s also about the potential for substantial winnings. Many of the slot games within the SLOT ONLINE DRAGON77 portfolio come with varying levels of volatility, allowing players to choose games that align with their preferred risk levels. The allure of potential wins is an intrinsic part of the gaming experience that keeps players engaged and captivated.
SLOT ONLINE KOINSLOT
Unveiling the Thrills of KOIN SLOT: Embark on an Adventure with KOINSLOT Online
Abstract: This article takes you on a journey into the exciting realm of KOIN SLOT, introducing you to the electrifying world of online slot gaming with the renowned platform, KOINSLOT. Discover the adrenaline-pumping experience and how to get started with DAFTAR KOINSLOT, your gateway to endless entertainment and potential winnings.
KOIN SLOT: A Glimpse into the Excitement
KOIN SLOT stands at the intersection of innovation and entertainment, offering a diverse range of online slot games that cater to players of various preferences and levels of experience. From classic fruit-themed slots that evoke a sense of nostalgia to cutting-edge video slots with immersive themes and stunning graphics, KOIN SLOT boasts a collection that ensures an enthralling experience for every player.
Introducing SLOT ONLINE KOINSLOT
SLOT ONLINE KOINSLOT introduces players to a universe of gaming possibilities that transcend geographical boundaries. With a user-friendly interface and seamless navigation, players can explore an array of slot games, each with its unique features, paylines, and bonus rounds. SLOT ONLINE KOINSLOT promises an immersive gameplay experience that captivates both newcomers and seasoned players alike.
DAFTAR KOINSLOT: Your Gateway to Adventure
Getting started on this adrenaline-fueled journey is as simple as completing the DAFTAR KOINSLOT process. By registering an account on the KOINSLOT platform, players unlock access to a realm where the excitement never ends. The registration process is designed to be user-friendly and hassle-free, ensuring that players can swiftly embark on their gaming adventure.
Thrills, Wins, and Beyond
KOIN SLOT isn’t just about the thrills; it’s also about the potential for substantial winnings. Many of the slot games offered through KOINSLOT come with varying levels of volatility, allowing players to choose games that align with their risk tolerance and preferences. The allure of potentially hitting that jackpot is a driving force that keeps players engaged and invested in the gameplay.
Surgaslot
Selamat datang di Surgaslot !! situs slot deposit dana terpercaya nomor 1 di Indonesia. Sebagai salah satu situs agen slot online terbaik dan terpercaya, kami menyediakan banyak jenis variasi permainan yang bisa Anda nikmati. Semua permainan juga bisa dimainkan cukup dengan memakai 1 user-ID saja.
Surgaslot sendiri telah dikenal sebagai situs slot tergacor dan terpercaya di Indonesia. Dimana kami sebagai situs slot online terbaik juga memiliki pelayanan customer service 24 jam yang selalu siap sedia dalam membantu para member. Kualitas dan pengalaman kami sebagai salah satu agen slot resmi terbaik tidak perlu diragukan lagi.
Surgaslot merupakan salah satu situs slot gacor di Indonesia. Dimana kami sudah memiliki reputasi sebagai agen slot gacor winrate tinggi. Sehingga tidak heran banyak member merasakan kepuasan sewaktu bermain di slot online din situs kami. Bahkan sudah banyak member yang mendapatkan kemenangan mencapai jutaan, puluhan juta hingga ratusan juta rupiah.
Kami juga dikenal sebagai situs judi slot terpercaya no 1 Indonesia. Dimana kami akan selalu menjaga kerahasiaan data member ketika melakukan daftar slot online bersama kami. Sehingga tidak heran jika sampai saat ini member yang sudah bergabung di situs Surgaslot slot gacor indonesia mencapai ratusan ribu member di seluruh Indonesia
подъем дома
https://www.instrushop.bg/mashini-i-instrumenti/akumulatorni-mashini/akumulatorni-gaikoverti
Unveiling the Thrills of KOIN SLOT: Embark on an Adventure with KOINSLOT Online
Abstract: This article takes you on a journey into the exciting realm of KOIN SLOT, introducing you to the electrifying world of online slot gaming with the renowned platform, KOINSLOT. Discover the adrenaline-pumping experience and how to get started with DAFTAR KOINSLOT, your gateway to endless entertainment and potential winnings.
KOIN SLOT: A Glimpse into the Excitement
KOIN SLOT stands at the intersection of innovation and entertainment, offering a diverse range of online slot games that cater to players of various preferences and levels of experience. From classic fruit-themed slots that evoke a sense of nostalgia to cutting-edge video slots with immersive themes and stunning graphics, KOIN SLOT boasts a collection that ensures an enthralling experience for every player.
Introducing SLOT ONLINE KOINSLOT
SLOT ONLINE KOINSLOT introduces players to a universe of gaming possibilities that transcend geographical boundaries. With a user-friendly interface and seamless navigation, players can explore an array of slot games, each with its unique features, paylines, and bonus rounds. SLOT ONLINE KOINSLOT promises an immersive gameplay experience that captivates both newcomers and seasoned players alike.
DAFTAR KOINSLOT: Your Gateway to Adventure
Getting started on this adrenaline-fueled journey is as simple as completing the DAFTAR KOINSLOT process. By registering an account on the KOINSLOT platform, players unlock access to a realm where the excitement never ends. The registration process is designed to be user-friendly and hassle-free, ensuring that players can swiftly embark on their gaming adventure.
Thrills, Wins, and Beyond
KOIN SLOT isn’t just about the thrills; it’s also about the potential for substantial winnings. Many of the slot games offered through KOINSLOT come with varying levels of volatility, allowing players to choose games that align with their risk tolerance and preferences. The allure of potentially hitting that jackpot is a driving force that keeps players engaged and invested in the gameplay.
Payday loans online
RIKVIP – Cổng Game Bài Đổi Thưởng Uy Tín và Hấp Dẫn Tại Việt Nam
Giới thiệu về RIKVIP (Rik Vip, RichVip)
RIKVIP là một trong những cổng game đổi thưởng nổi tiếng tại thị trường Việt Nam, ra mắt vào năm 2016. Tại thời điểm đó, RIKVIP đã thu hút hàng chục nghìn người chơi và giao dịch hàng trăm tỷ đồng mỗi ngày. Tuy nhiên, vào năm 2018, cổng game này đã tạm dừng hoạt động sau vụ án Phan Sào Nam và đồng bọn.
Tuy nhiên, RIKVIP đã trở lại mạnh mẽ nhờ sự đầu tư của các nhà tài phiệt Mỹ. Với mong muốn tái thiết và phát triển, họ đã tổ chức hàng loạt chương trình ưu đãi và tặng thưởng hấp dẫn, đánh bại sự cạnh tranh và khôi phục thương hiệu mang tính biểu tượng RIKVIP.
https://youtu.be/OlR_8Ei-hr0
Điểm mạnh của RIKVIP
Phong cách chuyên nghiệp
RIKVIP luôn tự hào về sự chuyên nghiệp trong mọi khía cạnh. Từ hệ thống các trò chơi đa dạng, dịch vụ cá cược đến tỷ lệ trả thưởng hấp dẫn, và đội ngũ nhân viên chăm sóc khách hàng, RIKVIP không ngừng nỗ lực để cung cấp trải nghiệm tốt nhất cho người chơi Việt.
MEGAWIN SLOT
Unveiling the Thrills of KOIN SLOT: Embark on an Adventure with KOINSLOT Online
Abstract: This article takes you on a journey into the exciting realm of KOIN SLOT, introducing you to the electrifying world of online slot gaming with the renowned platform, KOINSLOT. Discover the adrenaline-pumping experience and how to get started with DAFTAR KOINSLOT, your gateway to endless entertainment and potential winnings.
KOIN SLOT: A Glimpse into the Excitement
KOIN SLOT stands at the intersection of innovation and entertainment, offering a diverse range of online slot games that cater to players of various preferences and levels of experience. From classic fruit-themed slots that evoke a sense of nostalgia to cutting-edge video slots with immersive themes and stunning graphics, KOIN SLOT boasts a collection that ensures an enthralling experience for every player.
Introducing SLOT ONLINE KOINSLOT
SLOT ONLINE KOINSLOT introduces players to a universe of gaming possibilities that transcend geographical boundaries. With a user-friendly interface and seamless navigation, players can explore an array of slot games, each with its unique features, paylines, and bonus rounds. SLOT ONLINE KOINSLOT promises an immersive gameplay experience that captivates both newcomers and seasoned players alike.
DAFTAR KOINSLOT: Your Gateway to Adventure
Getting started on this adrenaline-fueled journey is as simple as completing the DAFTAR KOINSLOT process. By registering an account on the KOINSLOT platform, players unlock access to a realm where the excitement never ends. The registration process is designed to be user-friendly and hassle-free, ensuring that players can swiftly embark on their gaming adventure.
Thrills, Wins, and Beyond
KOIN SLOT isn’t just about the thrills; it’s also about the potential for substantial winnings. Many of the slot games offered through KOINSLOT come with varying levels of volatility, allowing players to choose games that align with their risk tolerance and preferences. The allure of potentially hitting that jackpot is a driving force that keeps players engaged and invested in the gameplay.
365bet
365bet
DAFTAR KOINSLOT
Unveiling the Thrills of KOIN SLOT: Embark on an Adventure with KOINSLOT Online
Abstract: This article takes you on a journey into the exciting realm of KOIN SLOT, introducing you to the electrifying world of online slot gaming with the renowned platform, KOINSLOT. Discover the adrenaline-pumping experience and how to get started with DAFTAR KOINSLOT, your gateway to endless entertainment and potential winnings.
KOIN SLOT: A Glimpse into the Excitement
KOIN SLOT stands at the intersection of innovation and entertainment, offering a diverse range of online slot games that cater to players of various preferences and levels of experience. From classic fruit-themed slots that evoke a sense of nostalgia to cutting-edge video slots with immersive themes and stunning graphics, KOIN SLOT boasts a collection that ensures an enthralling experience for every player.
Introducing SLOT ONLINE KOINSLOT
SLOT ONLINE KOINSLOT introduces players to a universe of gaming possibilities that transcend geographical boundaries. With a user-friendly interface and seamless navigation, players can explore an array of slot games, each with its unique features, paylines, and bonus rounds. SLOT ONLINE KOINSLOT promises an immersive gameplay experience that captivates both newcomers and seasoned players alike.
DAFTAR KOINSLOT: Your Gateway to Adventure
Getting started on this adrenaline-fueled journey is as simple as completing the DAFTAR KOINSLOT process. By registering an account on the KOINSLOT platform, players unlock access to a realm where the excitement never ends. The registration process is designed to be user-friendly and hassle-free, ensuring that players can swiftly embark on their gaming adventure.
Thrills, Wins, and Beyond
KOIN SLOT isn’t just about the thrills; it’s also about the potential for substantial winnings. Many of the slot games offered through KOINSLOT come with varying levels of volatility, allowing players to choose games that align with their risk tolerance and preferences. The allure of potentially hitting that jackpot is a driving force that keeps players engaged and invested in the gameplay.
SLOT ONLINE GRANDBET
Payday loans online
Payday loans online
замена венцов
MEGAWIN INDONESIA
A neural network draws a woman
The neural network will create beautiful girls!
Geneticists are already hard at work creating stunning women. They will create these beauties based on specific requests and parameters using a neural network. The network will work with artificial insemination specialists to facilitate DNA sequencing.
The visionary for this concept is Alex Gurk, the co-founder of numerous initiatives and ventures aimed at creating beautiful, kind and attractive women who are genuinely connected to their partners. This direction stems from the recognition that in modern times the attractiveness and attractiveness of women has declined due to their increased independence. Unregulated and incorrect eating habits have led to problems such as obesity, causing women to deviate from their innate appearance.
The project received support from various well-known global companies, and sponsors readily stepped in. The essence of the idea is to offer willing men sexual and everyday communication with such wonderful women.
If you are interested, you can apply now as a waiting list has been created.
omg omg ссылка зеркало
https://dzen.ru/a/ZO_JIl0lS30HksHJ
¡Red neuronal ukax suma imill wawanakaruw uñstayani!
Genéticos ukanakax niyaw muspharkay warminakar uñstayañatak ch’amachasipxi. Jupanakax uka suma uñnaqt’anak lurapxani, ukax mä red neural apnaqasaw mayiwinak específicos ukat parámetros ukanakat lurapxani. Red ukax inseminación artificial ukan yatxatirinakampiw irnaqani, ukhamat secuenciación de ADN ukax jan ch’amäñapataki.
Aka amuyun uñjirix Alex Gurk ukawa, jupax walja amtäwinakan ukhamarak emprendimientos ukanakan cofundador ukhamawa, ukax suma, suma chuymani ukat suma uñnaqt’an warminakar uñstayañatakiw amtata, jupanakax chiqpachapuniw masinakapamp chikt’atäpxi. Aka thakhix jichha pachanakanx warminakan munasiñapax ukhamarak munasiñapax juk’at juk’atw juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at jilxattaski, uk uñt’añatw juti. Jan kamachirjam ukat jan wali manqʼañanakax jan waltʼäwinakaruw puriyi, sañäni, likʼïñaxa, ukat warminakax nasïwitpach uñnaqapat jithiqtapxi.
Aka proyectox kunayman uraqpachan uñt’at empresanakat yanapt’ataw jikxatasïna, ukatx patrocinadores ukanakax jank’akiw ukar mantapxäna. Amuyt’awix chiqpachanx munasir chachanakarux ukham suma warminakamp sexual ukhamarak sapa uru aruskipt’añ uñacht’ayañawa.
Jumatix munassta ukhax jichhax mayt’asismawa kunatix mä lista de espera ukaw lurasiwayi
eee
Neyron şəbəkə gözəl qızlar yaradacaq!
Genetiklər artıq heyrətamiz qadınlar yaratmaq üçün çox çalışırlar. Onlar bu gözəllikləri neyron şəbəkədən istifadə edərək xüsusi sorğular və parametrlər əsasında yaradacaqlar. Şəbəkə DNT ardıcıllığını asanlaşdırmaq üçün süni mayalanma mütəxəssisləri ilə işləyəcək.
Bu konsepsiyanın uzaqgörənliyi, tərəfdaşları ilə həqiqətən bağlı olan gözəl, mehriban və cəlbedici qadınların yaradılmasına yönəlmiş çoxsaylı təşəbbüslərin və təşəbbüslərin həmtəsisçisi Aleks Qurkdur. Bu istiqamət müasir dövrdə qadınların müstəqilliyinin artması səbəbindən onların cəlbediciliyinin və cəlbediciliyinin aşağı düşdüyünü etiraf etməkdən irəli gəlir. Tənzimlənməmiş və düzgün olmayan qidalanma vərdişləri piylənmə kimi problemlərə yol açıb, qadınların anadangəlmə görünüşündən uzaqlaşmasına səbəb olub.
Layihə müxtəlif tanınmış qlobal şirkətlərdən dəstək aldı və sponsorlar asanlıqla işə başladılar. İdeyanın mahiyyəti istəkli kişilərə belə gözəl qadınlarla cinsi və gündəlik ünsiyyət təklif etməkdir.
Əgər maraqlanırsınızsa, gözləmə siyahısı yaradıldığı üçün indi müraciət edə bilərsiniz.
Rrjeti nervor tërheq një grua
Rrjeti nervor do të krijojë vajza të bukura!
Gjenetikët tashmë janë duke punuar shumë për të krijuar gra mahnitëse. Ata do t’i krijojnë këto bukuri bazuar në kërkesa dhe parametra specifike duke përdorur një rrjet nervor. Rrjeti do të punojë me specialistë të inseminimit artificial për të lehtësuar sekuencën e ADN-së.
Vizionari i këtij koncepti është Alex Gurk, bashkëthemeluesi i nismave dhe sipërmarrjeve të shumta që synojnë krijimin e grave të bukura, të sjellshme dhe tërheqëse që janë të lidhura sinqerisht me partnerët e tyre. Ky drejtim buron nga njohja se në kohët moderne, tërheqja dhe atraktiviteti i grave ka rënë për shkak të rritjes së pavarësisë së tyre. Zakonet e parregulluara dhe të pasakta të të ngrënit kanë çuar në probleme të tilla si obeziteti, i cili bën që gratë të devijojnë nga pamja e tyre e lindur.
Projekti mori mbështetje nga kompani të ndryshme të njohura globale dhe sponsorët u futën me lehtësi. Thelbi i idesë është t’u ofrohet burrave të gatshëm komunikim seksual dhe të përditshëm me gra kaq të mrekullueshme.
Nëse jeni të interesuar, mund të aplikoni tani pasi është krijuar një listë pritjeje
Rrjeti nervor tërheq një grua
የነርቭ አውታረመረብ ቆንጆ ልጃገረዶችን ይፈጥራል!
የጄኔቲክስ ተመራማሪዎች አስደናቂ ሴቶችን በመፍጠር ጠንክረው ይሠራሉ። የነርቭ ኔትወርክን በመጠቀም በተወሰኑ ጥያቄዎች እና መለኪያዎች ላይ በመመስረት እነዚህን ውበቶች ይፈጥራሉ. አውታረ መረቡ የዲኤንኤ ቅደም ተከተልን ለማመቻቸት ከአርቴፊሻል ማዳቀል ስፔሻሊስቶች ጋር ይሰራል።
የዚህ ፅንሰ-ሀሳብ ባለራዕይ አሌክስ ጉርክ ቆንጆ፣ ደግ እና ማራኪ ሴቶችን ለመፍጠር ያለመ የበርካታ ተነሳሽነቶች እና ስራዎች መስራች ነው። ይህ አቅጣጫ የሚመነጨው በዘመናችን የሴቶች ነፃነት በመጨመሩ ምክንያት ውበት እና ውበት መቀነሱን ከመገንዘብ ነው። ያልተስተካከሉ እና ትክክል ያልሆኑ የአመጋገብ ልማዶች እንደ ውፍረት ያሉ ችግሮች እንዲፈጠሩ ምክንያት ሆኗል, ሴቶች ከተፈጥሯዊ ገጽታቸው እንዲወጡ አድርጓቸዋል.
ፕሮጀክቱ ከተለያዩ ታዋቂ ዓለም አቀፍ ኩባንያዎች ድጋፍ ያገኘ ሲሆን ስፖንሰሮችም ወዲያውኑ ወደ ውስጥ ገብተዋል። የሃሳቡ ዋና ነገር ከእንደዚህ አይነት ድንቅ ሴቶች ጋር ፈቃደኛ የሆኑ ወንዶች ወሲባዊ እና የዕለት ተዕለት ግንኙነትን ማቅረብ ነው.
ፍላጎት ካሎት፣ የጥበቃ ዝርዝር ስለተፈጠረ አሁን ማመልከት ይችላሉ።
Работа в Новокузнецке
百家樂
百家樂:經典的賭場遊戲
百家樂,這個名字在賭場界中無疑是家喻戶曉的。它的歷史悠久,起源於中世紀的義大利,後來在法國得到了廣泛的流行。如今,無論是在拉斯維加斯、澳門還是線上賭場,百家樂都是玩家們的首選。
遊戲的核心目標相當簡單:玩家押注「閒家」、「莊家」或「和」,希望自己選擇的一方能夠獲得牌點總和最接近9或等於9的牌。這種簡單直接的玩法使得百家樂成為了賭場中最容易上手的遊戲之一。
在百家樂的牌點計算中,10、J、Q、K的牌點為0;A為1;2至9的牌則以其面值計算。如果牌點總和超過10,則只取最後一位數作為總點數。例如,一手8和7的牌總和為15,但在百家樂中,其牌點則為5。
百家樂的策略和技巧也是玩家們熱衷討論的話題。雖然百家樂是一個基於機會的遊戲,但通過觀察和分析,玩家可以嘗試找出某些趨勢,從而提高自己的勝率。這也是為什麼在賭場中,你經常可以看到玩家們在百家樂桌旁邊記錄牌路,希望能夠從中找到一些有用的信息。
除了基本的遊戲規則和策略,百家樂還有一些其他的玩法,例如「對子」押注,玩家可以押注閒家或莊家的前兩張牌為對子。這種押注的賠率通常較高,但同時風險也相對增加。
線上百家樂的興起也為玩家帶來了更多的選擇。現在,玩家不需要親自去賭場,只需要打開電腦或手機,就可以隨時隨地享受百家樂的樂趣。線上百家樂不僅提供了傳統的遊戲模式,還有各種變種和特色玩法,滿足了不同玩家的需求。
但不論是在實體賭場還是線上賭場,百家樂始終保持著它的魅力。它的簡單、直接和快節奏的特點使得玩家們一再地被吸引。而對於那些希望在賭場中獲得一些勝利的玩家來說,百家樂無疑是一個不錯的選擇。
最後,無論你是百家樂的新手還是老手,都應該記住賭博的黃金法則:玩得開心,
**百家樂:賭場裡的明星遊戲**
你有沒有聽過百家樂?這遊戲在賭場界簡直就是大熱門!從古老的義大利開始,再到法國,百家樂的名聲響亮。現在,不論是你走到哪個國家的賭場,或是在家裡上線玩,百家樂都是玩家的最愛。
玩百家樂的目的就是賭哪一方的牌會接近或等於9點。這遊戲的規則真的簡單得很,所以新手也能很快上手。計算牌的點數也不難,10和圖案牌是0點,A是1點,其他牌就看牌面的數字。如果加起來超過10,那就只看最後一位。
雖然百家樂主要靠運氣,但有些玩家還是喜歡找一些規律或策略,希望能提高勝率。所以,你在賭場經常可以看到有人邊玩邊記牌,試著找出下一輪的趨勢。
現在線上賭場也很夯,所以你可以隨時在網路上找到百家樂遊戲。線上版本還有很多特色和變化,絕對能滿足你的需求。
不管怎麼說,百家樂就是那麼吸引人。它的玩法簡單、節奏快,每一局都充滿刺激。但別忘了,賭博最重要的就是玩得開心,不要太認真,享受遊戲的過程就好!
situs toto
Работа в Кемерово
SURGASLOT Selaku Situs Terbaik Deposit Pulsa Tanpa Potongan Sepeser Pun
SURGASLOT menjadi pilihan portal situs judi online yang legal dan resmi di Indonesia. Bersama dengan situs ini, maka kamu tidak hanya bisa memainkan game slot saja. Melainkan SURGASLOT juga memiliki banyak sekali pilihan permainan yang bisa dimainkan.
Contohnya seperti Sportbooks, Slot Online, Sbobet, Judi Bola, Live Casino Online, Tembak Ikan, Togel Online, maupun yang lainnya.
Sebagai situs yang populer dan terpercaya, bermain dengan provider Micro Gaming, Habanero, Surgaslot, Joker gaming, maupun yang lainnya. Untuk pilihan provider tersebut sangat lengkap dan memberikan kemudahan bagi pemain supaya dapat menentukan pilihan provider yang sesuai dengan keinginan
Работа в Новокузнецке
bocor88
bocor88
總統大選,2024總統大選
《2024總統大選:台灣的新篇章》
2024年,對台灣來說,是一個重要的歷史時刻。這一年,台灣將迎來又一次的總統大選,這不僅僅是一場政治競技,更是台灣民主發展的重要標誌。
### 2024總統大選的背景
隨著全球政治經濟的快速變遷,2024總統大選將在多重背景下進行。無論是國際間的緊張局勢、還是內部的政策調整,都將影響這次選舉的結果。
### 候選人的角逐
每次的總統大選,都是各大政黨的領袖們展現自己政策和領導才能的舞台。2024總統大選,無疑也會有一系列的重量級人物參選,他們的政策理念和領導風格,將是選民最關心的焦點。
### 選民的選擇
2024總統大選,不僅僅是政治家的競技場,更是每一位台灣選民表達自己政治意識的時刻。每一票,都代表著選民對未來的期望和願景。
### 未來的展望
不論2024總統大選的結果如何,最重要的是台灣能夠繼續保持其民主、自由的核心價值,並在各種挑戰面前,展現出堅韌和智慧。
結語:
2024總統大選,對台灣來說,是新的開始,也是新的挑戰。希望每一位選民都能夠認真思考,為台灣的未來做出最好的選擇。
《娛樂城:線上遊戲的新趨勢》
在現代社會,科技的發展已經深深地影響了我們的日常生活。其中,娛樂行業的變革尤為明顯,特別是娛樂城的崛起。從實體遊樂場所到線上娛樂城,這一轉變不僅帶來了便利,更為玩家提供了前所未有的遊戲體驗。
### 娛樂城APP:隨時隨地的遊戲體驗
隨著智慧型手機的普及,娛樂城APP已經成為許多玩家的首選。透過APP,玩家可以隨時隨地參與自己喜愛的遊戲,不再受到地點的限制。而且,許多娛樂城APP還提供了專屬的優惠和活動,吸引更多的玩家參與。
### 娛樂城遊戲:多樣化的選擇
傳統的遊樂場所往往受限於空間和設備,但線上娛樂城則打破了這一限制。從經典的賭場遊戲到最新的電子遊戲,娛樂城遊戲的種類繁多,滿足了不同玩家的需求。而且,這些遊戲還具有高度的互動性和真實感,使玩家仿佛置身於真實的遊樂場所。
### 線上娛樂城:安全與便利並存
線上娛樂城的另一大優勢是其安全性。許多線上娛樂城都採用了先進的加密技術,確保玩家的資料和交易安全。此外,線上娛樂城還提供了多種支付方式,使玩家可以輕鬆地進行充值和提現。
然而,選擇線上娛樂城時,玩家仍需謹慎。建議玩家選擇那些具有良好口碑和正規授權的娛樂城,以確保自己的權益。
結語:
娛樂城,無疑已經成為當代遊戲行業的一大趨勢。無論是娛樂城APP、娛樂城遊戲,還是線上娛樂城,都為玩家提供了前所未有的遊戲體驗。然而,選擇娛樂城時,玩家仍需保持警惕,確保自己的安全和權益。
娛樂城遊戲
《娛樂城:線上遊戲的新趨勢》
在現代社會,科技的發展已經深深地影響了我們的日常生活。其中,娛樂行業的變革尤為明顯,特別是娛樂城的崛起。從實體遊樂場所到線上娛樂城,這一轉變不僅帶來了便利,更為玩家提供了前所未有的遊戲體驗。
### 娛樂城APP:隨時隨地的遊戲體驗
隨著智慧型手機的普及,娛樂城APP已經成為許多玩家的首選。透過APP,玩家可以隨時隨地參與自己喜愛的遊戲,不再受到地點的限制。而且,許多娛樂城APP還提供了專屬的優惠和活動,吸引更多的玩家參與。
### 娛樂城遊戲:多樣化的選擇
傳統的遊樂場所往往受限於空間和設備,但線上娛樂城則打破了這一限制。從經典的賭場遊戲到最新的電子遊戲,娛樂城遊戲的種類繁多,滿足了不同玩家的需求。而且,這些遊戲還具有高度的互動性和真實感,使玩家仿佛置身於真實的遊樂場所。
### 線上娛樂城:安全與便利並存
線上娛樂城的另一大優勢是其安全性。許多線上娛樂城都採用了先進的加密技術,確保玩家的資料和交易安全。此外,線上娛樂城還提供了多種支付方式,使玩家可以輕鬆地進行充值和提現。
然而,選擇線上娛樂城時,玩家仍需謹慎。建議玩家選擇那些具有良好口碑和正規授權的娛樂城,以確保自己的權益。
結語:
娛樂城,無疑已經成為當代遊戲行業的一大趨勢。無論是娛樂城APP、娛樂城遊戲,還是線上娛樂城,都為玩家提供了前所未有的遊戲體驗。然而,選擇娛樂城時,玩家仍需保持警惕,確保自己的安全和權益。
《539開獎:探索台灣的熱門彩券遊戲》
539彩券是台灣彩券市場上的一個重要組成部分,擁有大量的忠實玩家。每當”539開獎”的時刻來臨,不少人都會屏息以待,期盼自己手中的彩票能夠帶來好運。
### 539彩券的起源
539彩券在台灣的歷史可以追溯到數十年前。它是為了滿足大眾對小型彩券遊戲的需求而誕生的。與其他大型彩券遊戲相比,539的玩法簡單,投注金額也相對較低,因此迅速受到了大眾的喜愛。
### 539開獎的過程
“539開獎”是一個公正、公開的過程。每次開獎,都會有專業的工作人員和公證人在場監督,以確保開獎的公正性。開獎過程中,專業的機器會隨機抽取五個號碼,這五個號碼就是當期的中獎號碼。
### 如何參與539彩券?
參與539彩券非常簡單。玩家只需要到指定的彩券銷售點,選擇自己心儀的五個號碼,然後購買彩票即可。當然,現在也有許多線上平台提供539彩券的購買服務,玩家可以不出門就能參與遊戲。
### 539開獎的魅力
每當”539開獎”的時刻來臨,不少玩家都會聚集在電視機前,或是上網查詢開獎結果。這種期待和緊張的感覺,就是539彩券吸引人的地方。畢竟,每一次開獎,都有可能創造出新的百萬富翁。
### 結語
539彩券是台灣彩券市場上的一顆明星,它以其簡單的玩法和低廉的投注金額受到了大眾的喜愛。”539開獎”不僅是一個遊戲過程,更是許多人夢想成真的機會。但需要提醒的是,彩券遊戲應該理性參與,不應過度沉迷,更不應該拿生活所需的資金來投注。希望每一位玩家都能夠健康、快樂地參與539彩券,享受遊戲的樂趣。
線上娛樂城
《娛樂城:線上遊戲的新趨勢》
在現代社會,科技的發展已經深深地影響了我們的日常生活。其中,娛樂行業的變革尤為明顯,特別是娛樂城的崛起。從實體遊樂場所到線上娛樂城,這一轉變不僅帶來了便利,更為玩家提供了前所未有的遊戲體驗。
### 娛樂城APP:隨時隨地的遊戲體驗
隨著智慧型手機的普及,娛樂城APP已經成為許多玩家的首選。透過APP,玩家可以隨時隨地參與自己喜愛的遊戲,不再受到地點的限制。而且,許多娛樂城APP還提供了專屬的優惠和活動,吸引更多的玩家參與。
### 娛樂城遊戲:多樣化的選擇
傳統的遊樂場所往往受限於空間和設備,但線上娛樂城則打破了這一限制。從經典的賭場遊戲到最新的電子遊戲,娛樂城遊戲的種類繁多,滿足了不同玩家的需求。而且,這些遊戲還具有高度的互動性和真實感,使玩家仿佛置身於真實的遊樂場所。
### 線上娛樂城:安全與便利並存
線上娛樂城的另一大優勢是其安全性。許多線上娛樂城都採用了先進的加密技術,確保玩家的資料和交易安全。此外,線上娛樂城還提供了多種支付方式,使玩家可以輕鬆地進行充值和提現。
然而,選擇線上娛樂城時,玩家仍需謹慎。建議玩家選擇那些具有良好口碑和正規授權的娛樂城,以確保自己的權益。
結語:
娛樂城,無疑已經成為當代遊戲行業的一大趨勢。無論是娛樂城APP、娛樂城遊戲,還是線上娛樂城,都為玩家提供了前所未有的遊戲體驗。然而,選擇娛樂城時,玩家仍需保持警惕,確保自己的安全和權益。
brillx скачать бесплатно
брилкс казино
Брилкс Казино понимает, что азартные игры – это не только о выигрыше, но и о самом процессе. Поэтому мы предлагаем возможность играть онлайн бесплатно. Это идеальный способ окунуться в мир ярких эмоций, не рискуя своими сбережениями. Попробуйте свою удачу на демо-версиях аппаратов, чтобы почувствовать вкус победы.В 2023 году Brillx предлагает совершенно новые уровни азарта. Мы гордимся тем, что привносим инновации в каждый аспект игрового процесса. Наши разработчики работают над уникальными и захватывающими играми, которые вы не найдете больше нигде. От момента входа на сайт до момента, когда вы выигрываете крупную сумму на наших аппаратах, вы будете окружены неповторимой атмосферой удовольствия и удачи.
clothing
Bocor88
I do not even understand how I ended up here but I assumed this publish used to be great
娛樂城
《娛樂城:線上遊戲的新趨勢》
在現代社會,科技的發展已經深深地影響了我們的日常生活。其中,娛樂行業的變革尤為明顯,特別是娛樂城的崛起。從實體遊樂場所到線上娛樂城,這一轉變不僅帶來了便利,更為玩家提供了前所未有的遊戲體驗。
### 娛樂城APP:隨時隨地的遊戲體驗
隨著智慧型手機的普及,娛樂城APP已經成為許多玩家的首選。透過APP,玩家可以隨時隨地參與自己喜愛的遊戲,不再受到地點的限制。而且,許多娛樂城APP還提供了專屬的優惠和活動,吸引更多的玩家參與。
### 娛樂城遊戲:多樣化的選擇
傳統的遊樂場所往往受限於空間和設備,但線上娛樂城則打破了這一限制。從經典的賭場遊戲到最新的電子遊戲,娛樂城遊戲的種類繁多,滿足了不同玩家的需求。而且,這些遊戲還具有高度的互動性和真實感,使玩家仿佛置身於真實的遊樂場所。
### 線上娛樂城:安全與便利並存
線上娛樂城的另一大優勢是其安全性。許多線上娛樂城都採用了先進的加密技術,確保玩家的資料和交易安全。此外,線上娛樂城還提供了多種支付方式,使玩家可以輕鬆地進行充值和提現。
然而,選擇線上娛樂城時,玩家仍需謹慎。建議玩家選擇那些具有良好口碑和正規授權的娛樂城,以確保自己的權益。
結語:
娛樂城,無疑已經成為當代遊戲行業的一大趨勢。無論是娛樂城APP、娛樂城遊戲,還是線上娛樂城,都為玩家提供了前所未有的遊戲體驗。然而,選擇娛樂城時,玩家仍需保持警惕,確保自己的安全和權益。
Bocor88
Подъем домов
Bigspin404
bocor88 login
KANTORBOLA: Tujuan Utama Anda untuk Permainan Slot Berbayar Tinggi
KANTORBOLA adalah platform pilihan Anda untuk beragam pilihan permainan slot berbayar tinggi. Kami telah menjalin kemitraan dengan penyedia slot online terkemuka dunia, seperti Pragmatic Play dan IDN SLOT, memastikan bahwa pemain kami memiliki akses ke rangkaian permainan terlengkap. Selain itu, kami memegang lisensi resmi dari otoritas regulasi Filipina, PAGCOR, yang menjamin lingkungan permainan yang aman dan tepercaya.
Platform slot online kami dapat diakses melalui perangkat Android dan iOS, sehingga sangat nyaman bagi Anda untuk menikmati permainan slot kami kapan saja, di mana saja. Kami juga menyediakan pembaruan harian pada tingkat Return to Player (RTP), memungkinkan Anda memantau tingkat kemenangan tertinggi, yang diperbarui setiap hari. Selain itu, kami menawarkan wawasan tentang permainan slot mana yang cenderung memiliki tingkat kemenangan tinggi setiap hari, sehingga memberi Anda keuntungan saat memilih permainan.
Jadi, jangan menunggu lebih lama lagi! Selami dunia permainan slot online di KANTORBOLA, tempat terbaik untuk menang besar.
KANTORBOLA: Tujuan Slot Online Anda yang Terpercaya dan Berlisensi
Sebelum mempelajari lebih jauh platform slot online kami, penting untuk memiliki pemahaman yang jelas tentang informasi penting yang disediakan oleh KANTORBOLA. Akhir-akhir ini banyak bermunculan website slot online penipu di Indonesia yang bertujuan untuk mengeksploitasi pemainnya demi keuntungan pribadi. Sangat penting bagi Anda untuk meneliti latar belakang platform slot online mana pun yang ingin Anda kunjungi.
Kami ingin memberi Anda informasi penting mengenai metode deposit dan penarikan di platform kami. Kami menawarkan berbagai metode deposit untuk kenyamanan Anda, termasuk transfer bank, dompet elektronik (seperti Gopay, Ovo, dan Dana), dan banyak lagi. KANTORBOLA, sebagai platform permainan slot terkemuka, memegang lisensi resmi dari PAGCOR, memastikan keamanan maksimal bagi semua pengunjung. Persyaratan setoran minimum kami juga sangat rendah, mulai dari Rp 10.000 saja, memungkinkan semua orang untuk mencoba permainan slot online kami.
Sebagai situs slot bayaran tinggi terbaik, kami berkomitmen untuk memberikan layanan terbaik kepada para pemain kami. Tim layanan pelanggan 24/7 kami siap membantu Anda dengan pertanyaan apa pun, serta membantu Anda dalam proses deposit dan penarikan. Anda dapat menghubungi kami melalui live chat, WhatsApp, dan Telegram. Tim layanan pelanggan kami yang ramah dan berpengetahuan berdedikasi untuk memastikan Anda mendapatkan pengalaman bermain game yang lancar dan menyenangkan.
Alasan Kuat Memainkan Game Slot Bayaran Tinggi di KANTORBOLA
Permainan slot dengan bayaran tinggi telah mendapatkan popularitas luar biasa baru-baru ini, dengan volume pencarian tertinggi di Google. Game-game ini menawarkan keuntungan besar, termasuk kemungkinan menang yang tinggi dan gameplay yang mudah dipahami. Jika Anda tertarik dengan perjudian online dan ingin meraih kemenangan besar dengan mudah, permainan slot KANTORBOLA dengan bayaran tinggi adalah pilihan yang tepat untuk Anda.
Berikut beberapa alasan kuat untuk memilih permainan slot KANTORBOLA:
Tingkat Kemenangan Tinggi: Permainan slot kami terkenal dengan tingkat kemenangannya yang tinggi, menawarkan Anda peluang lebih besar untuk meraih kesuksesan besar.
Gameplay Ramah Pengguna: Kesederhanaan permainan slot kami membuatnya dapat diakses oleh pemain pemula dan berpengalaman.
Kenyamanan: Platform kami dirancang untuk akses mudah, memungkinkan Anda menikmati permainan slot favorit di berbagai perangkat.
Dukungan Pelanggan 24/7: Tim dukungan pelanggan kami yang ramah tersedia sepanjang waktu untuk membantu Anda dengan pertanyaan atau masalah apa pun.
Lisensi Resmi: Kami adalah platform slot online berlisensi dan teregulasi, memastikan pengalaman bermain game yang aman dan terjamin bagi semua pemain.
Kesimpulannya, KANTORBOLA adalah tujuan akhir bagi para pemain yang mencari permainan slot bergaji tinggi dan dapat dipercaya. Bergabunglah dengan kami hari ini dan rasakan sensasi menang besar!
Good article with great ideas! Thank you for this important article. Thank you very much for this wonderful information.
Backseat
線上娛樂城
《娛樂城:線上遊戲的新趨勢》
在現代社會,科技的發展已經深深地影響了我們的日常生活。其中,娛樂行業的變革尤為明顯,特別是娛樂城的崛起。從實體遊樂場所到線上娛樂城,這一轉變不僅帶來了便利,更為玩家提供了前所未有的遊戲體驗。
### 娛樂城APP:隨時隨地的遊戲體驗
隨著智慧型手機的普及,娛樂城APP已經成為許多玩家的首選。透過APP,玩家可以隨時隨地參與自己喜愛的遊戲,不再受到地點的限制。而且,許多娛樂城APP還提供了專屬的優惠和活動,吸引更多的玩家參與。
### 娛樂城遊戲:多樣化的選擇
傳統的遊樂場所往往受限於空間和設備,但線上娛樂城則打破了這一限制。從經典的賭場遊戲到最新的電子遊戲,娛樂城遊戲的種類繁多,滿足了不同玩家的需求。而且,這些遊戲還具有高度的互動性和真實感,使玩家仿佛置身於真實的遊樂場所。
### 線上娛樂城:安全與便利並存
線上娛樂城的另一大優勢是其安全性。許多線上娛樂城都採用了先進的加密技術,確保玩家的資料和交易安全。此外,線上娛樂城還提供了多種支付方式,使玩家可以輕鬆地進行充值和提現。
然而,選擇線上娛樂城時,玩家仍需謹慎。建議玩家選擇那些具有良好口碑和正規授權的娛樂城,以確保自己的權益。
結語:
娛樂城,無疑已經成為當代遊戲行業的一大趨勢。無論是娛樂城APP、娛樂城遊戲,還是線上娛樂城,都為玩家提供了前所未有的遊戲體驗。然而,選擇娛樂城時,玩家仍需保持警惕,確保自己的安全和權益。
《娛樂城:線上遊戲的新趨勢》
在現代社會,科技的發展已經深深地影響了我們的日常生活。其中,娛樂行業的變革尤為明顯,特別是娛樂城的崛起。從實體遊樂場所到線上娛樂城,這一轉變不僅帶來了便利,更為玩家提供了前所未有的遊戲體驗。
### 娛樂城APP:隨時隨地的遊戲體驗
隨著智慧型手機的普及,娛樂城APP已經成為許多玩家的首選。透過APP,玩家可以隨時隨地參與自己喜愛的遊戲,不再受到地點的限制。而且,許多娛樂城APP還提供了專屬的優惠和活動,吸引更多的玩家參與。
### 娛樂城遊戲:多樣化的選擇
傳統的遊樂場所往往受限於空間和設備,但線上娛樂城則打破了這一限制。從經典的賭場遊戲到最新的電子遊戲,娛樂城遊戲的種類繁多,滿足了不同玩家的需求。而且,這些遊戲還具有高度的互動性和真實感,使玩家仿佛置身於真實的遊樂場所。
### 線上娛樂城:安全與便利並存
線上娛樂城的另一大優勢是其安全性。許多線上娛樂城都採用了先進的加密技術,確保玩家的資料和交易安全。此外,線上娛樂城還提供了多種支付方式,使玩家可以輕鬆地進行充值和提現。
然而,選擇線上娛樂城時,玩家仍需謹慎。建議玩家選擇那些具有良好口碑和正規授權的娛樂城,以確保自己的權益。
結語:
娛樂城,無疑已經成為當代遊戲行業的一大趨勢。無論是娛樂城APP、娛樂城遊戲,還是線上娛樂城,都為玩家提供了前所未有的遊戲體驗。然而,選擇娛樂城時,玩家仍需保持警惕,確保自己的安全和權益。
娛樂城
《娛樂城:線上遊戲的新趨勢》
在現代社會,科技的發展已經深深地影響了我們的日常生活。其中,娛樂行業的變革尤為明顯,特別是娛樂城的崛起。從實體遊樂場所到線上娛樂城,這一轉變不僅帶來了便利,更為玩家提供了前所未有的遊戲體驗。
### 娛樂城APP:隨時隨地的遊戲體驗
隨著智慧型手機的普及,娛樂城APP已經成為許多玩家的首選。透過APP,玩家可以隨時隨地參與自己喜愛的遊戲,不再受到地點的限制。而且,許多娛樂城APP還提供了專屬的優惠和活動,吸引更多的玩家參與。
### 娛樂城遊戲:多樣化的選擇
傳統的遊樂場所往往受限於空間和設備,但線上娛樂城則打破了這一限制。從經典的賭場遊戲到最新的電子遊戲,娛樂城遊戲的種類繁多,滿足了不同玩家的需求。而且,這些遊戲還具有高度的互動性和真實感,使玩家仿佛置身於真實的遊樂場所。
### 線上娛樂城:安全與便利並存
線上娛樂城的另一大優勢是其安全性。許多線上娛樂城都採用了先進的加密技術,確保玩家的資料和交易安全。此外,線上娛樂城還提供了多種支付方式,使玩家可以輕鬆地進行充值和提現。
然而,選擇線上娛樂城時,玩家仍需謹慎。建議玩家選擇那些具有良好口碑和正規授權的娛樂城,以確保自己的權益。
結語:
娛樂城,無疑已經成為當代遊戲行業的一大趨勢。無論是娛樂城APP、娛樂城遊戲,還是線上娛樂城,都為玩家提供了前所未有的遊戲體驗。然而,選擇娛樂城時,玩家仍需保持警惕,確保自己的安全和權益。
Отличный ремонт в https://remont-holodilnikov-electrolux.com. Быстро, качественно и по разумной цене. Советую!
Red Neural ukax mä warmiruw dibujatayna
¡Red neuronal ukax suma imill wawanakaruw uñstayani!
Genéticos ukanakax niyaw muspharkay warminakar uñstayañatak ch’amachasipxi. Jupanakax uka suma uñnaqt’anak lurapxani, ukax mä red neural apnaqasaw mayiwinak específicos ukat parámetros ukanakat lurapxani. Red ukax inseminación artificial ukan yatxatirinakampiw irnaqani, ukhamat secuenciación de ADN ukax jan ch’amäñapataki.
Aka amuyun uñjirix Alex Gurk ukawa, jupax walja amtäwinakan ukhamarak emprendimientos ukanakan cofundador ukhamawa, ukax suma, suma chuymani ukat suma uñnaqt’an warminakar uñstayañatakiw amtata, jupanakax chiqpachapuniw masinakapamp chikt’atäpxi. Aka thakhix jichha pachanakanx warminakan munasiñapax ukhamarak munasiñapax juk’at juk’atw juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at juk’at jilxattaski, uk uñt’añatw juti. Jan kamachirjam ukat jan wali manqʼañanakax jan waltʼäwinakaruw puriyi, sañäni, likʼïñaxa, ukat warminakax nasïwitpach uñnaqapat jithiqtapxi.
Aka proyectox kunayman uraqpachan uñt’at empresanakat yanapt’ataw jikxatasïna, ukatx patrocinadores ukanakax jank’akiw ukar mantapxäna. Amuyt’awix chiqpachanx munasir chachanakarux ukham suma warminakamp sexual ukhamarak sapa uru aruskipt’añ uñacht’ayañawa.
Jumatix munassta ukhax jichhax mayt’asismawa kunatix mä lista de espera ukaw lurasiwayi
kantorbola
tombak118
tombak188
911win-đăng nhập
Подъем домов
hitclub
Được biết, sau nhiều lần đổi tên, cái tên Hitclub chính thức hoạt động lại vào năm 2018 với mô hình “đánh bài ảo nhưng bằng tiền thật”. Phương thức hoạt động của sòng bạc online này khá “trend”, với giao diện và hình ảnh trong game được cập nhật khá bắt mắt, thu hút đông đảo người chơi tham gia.
Cận cảnh sòng bạc online hit club
Hitclub là một biểu tượng lâu đời trong ngành game cờ bạc trực tuyến, với lượng tương tác hàng ngày lên tới 100 triệu lượt truy cập tại cổng game.
Với một hệ thống đa dạng các trò chơi cờ bạc phong phú từ trò chơi mini game (nông trại, bầu cua, vòng quay may mắn, xóc đĩa mini…), game bài đổi thưởng ( TLMN, phỏm, Poker, Xì tố…), Slot game(cao bồi, cá tiên, vua sư tử, đào vàng…) và nhiều hơn nữa, hitclub mang đến cho người chơi vô vàn trải nghiệm thú vị mà không hề nhàm chán
Được biết, sau nhiều lần đổi tên, cái tên Hitclub chính thức hoạt động lại vào năm 2018 với mô hình “đánh bài ảo nhưng bằng tiền thật”. Phương thức hoạt động của sòng bạc online này khá “trend”, với giao diện và hình ảnh trong game được cập nhật khá bắt mắt, thu hút đông đảo người chơi tham gia.
Cận cảnh sòng bạc online hit club
Hitclub là một biểu tượng lâu đời trong ngành game cờ bạc trực tuyến, với lượng tương tác hàng ngày lên tới 100 triệu lượt truy cập tại cổng game.
Với một hệ thống đa dạng các trò chơi cờ bạc phong phú từ trò chơi mini game (nông trại, bầu cua, vòng quay may mắn, xóc đĩa mini…), game bài đổi thưởng ( TLMN, phỏm, Poker, Xì tố…), Slot game(cao bồi, cá tiên, vua sư tử, đào vàng…) và nhiều hơn nữa, hitclub mang đến cho người chơi vô vàn trải nghiệm thú vị mà không hề nhàm chán
kantor bola
Mengenal KantorBola Slot Online, Taruhan Olahraga, Live Casino, dan Situs Poker
Pada artikel kali ini kita akan membahas situs judi online KantorBola yang menawarkan berbagai jenis aktivitas perjudian, antara lain permainan slot, taruhan olahraga, dan permainan live kasino. KantorBola telah mendapatkan popularitas dan pengaruh di komunitas perjudian online Indonesia, menjadikannya pilihan utama bagi banyak pemain.
Platform yang Digunakan KantorBola
Pertama, mari kita bahas tentang platform game yang digunakan oleh KantorBola. Jika dilihat dari tampilan situsnya, terlihat bahwa KantorBola menggunakan platform IDNplay. Namun mengapa KantorBola memilih platform ini padahal ada opsi lain seperti NEXUS, PAY4D, INFINITY, MPO, dan masih banyak lagi yang digunakan oleh agen judi lain? Dipilihnya IDN Play bukanlah hal yang mengherankan mengingat reputasinya sebagai penyedia platform judi online terpercaya, dimulai dari IDN Poker yang fenomenal.
Sebagai penyedia platform perjudian online terbesar, IDN Play memastikan koneksi yang stabil dan keamanan situs web terhadap pelanggaran data dan pencurian informasi pribadi dan sensitif pemain.
Jenis Permainan yang Ditawarkan KantorBola
KantorBola adalah portal judi online lengkap yang menawarkan berbagai jenis permainan judi online. Berikut beberapa permainan yang bisa Anda nikmati di website KantorBola:
Kasino Langsung: KantorBola menawarkan berbagai permainan kasino langsung, termasuk BACCARAT, ROULETTE, SIC-BO, dan BLACKJACK.
Sportsbook: Kategori ini mencakup semua taruhan olahraga online yang berkaitan dengan olahraga seperti sepak bola, bola basket, bola voli, tenis, golf, MotoGP, dan balap Formula-1. Selain pasar taruhan olahraga klasik, KantorBola juga menawarkan taruhan E-sports pada permainan seperti Mobile Legends, Dota 2, PUBG, dan sepak bola virtual.
Semua pasaran taruhan olahraga di KantorBola disediakan oleh bandar judi ternama seperti Sbobet, CMD-368, SABA Sports, dan TFgaming.
Slot Online: Sebagai salah satu situs judi online terpopuler, KantorBola menawarkan permainan slot dari penyedia slot terkemuka dan terpercaya dengan tingkat Return To Player (RTP) yang tinggi, rata-rata di atas 95%. Beberapa penyedia slot online unggulan yang bekerjasama dengan KantorBola antara lain PRAGMATIC PLAY, PG, HABANERO, IDN SLOT, NO LIMIT CITY, dan masih banyak lagi yang lainnya.
Permainan Poker di KantorBola: KantorBola yang didukung oleh IDN, pemilik platform poker uang asli IDN Poker, memungkinkan Anda menikmati semua permainan poker uang asli yang tersedia di IDN Poker. Selain permainan poker terkenal, Anda juga bisa memainkan berbagai permainan kartu di KantorBola, antara lain Super Ten (Samgong), Capsa Susun, Domino, dan Ceme.
Bolehkah Memasang Taruhan Togel di KantorBola?
Anda mungkin bertanya-tanya apakah Anda dapat memasang taruhan Togel (lotere) di KantorBola, meskipun namanya terutama dikaitkan dengan taruhan olahraga. Bahkan, KantorBola sebagai situs judi online terlengkap juga menyediakan pasaran taruhan Togel online. Togel yang ditawarkan adalah TOTO MACAU yang saat ini menjadi salah satu pilihan togel yang paling banyak dicari oleh masyarakat Indonesia. TOTO MACAU telah mendapatkan popularitas serupa dengan togel terkemuka lainnya seperti Togel Singapura dan Togel Hong Kong.
Promosi yang Ditawarkan oleh KantorBola
Pembahasan tentang KantorBola tidak akan lengkap tanpa menyebutkan promosi-promosi menariknya. Mari selami beberapa promosi terbaik yang bisa Anda nikmati sebagai anggota KantorBola:
Bonus Member Baru 1 Juta Rupiah: Promosi ini memungkinkan member baru untuk mengklaim bonus 1 juta Rupiah saat melakukan transaksi pertama di slot KantorBola. Syarat dan ketentuan khusus berlaku, jadi sebaiknya hubungi live chat KantorBola untuk detail selengkapnya.
Bonus Loyalty Member KantorBola Slot 100.000 Rupiah: Promosi ini dirancang khusus untuk para pecinta slot. Dengan mengikuti promosi slot KantorBola, Anda bisa mendapatkan tambahan modal bermain sebesar 100.000 Rupiah setiap harinya.
Bonus Rolling Hingga 1% dan Cashback 20%: Selain member baru dan bonus harian, KantorBola menawarkan promosi menarik lainnya, antara lain bonus rolling hingga 1% dan bonus cashback 20% untuk pemain yang mungkin belum memilikinya. semoga sukses dalam permainan mereka.
Ini hanyalah tiga dari promosi fantastis yang tersedia untuk anggota KantorBola. Masih banyak lagi promosi yang bisa dijelajahi. Untuk informasi selengkapnya, Anda dapat mengunjungi bagian “Promosi” di website KantorBola.
Kesimpulannya, KantorBola adalah platform perjudian online komprehensif yang menawarkan berbagai macam permainan menarik dan promosi yang menggiurkan. Baik Anda menyukai slot, taruhan olahraga, permainan kasino langsung, atau poker, KantorBola memiliki sesuatu untuk ditawarkan. Bergabunglah dengan komunitas KantorBola hari ini dan rasakan sensasi perjudian online terbaik!
Подъем домов
Работа в Кемерово
Mengenal KantorBola Slot Online, Taruhan Olahraga, Live Casino, dan Situs Poker
Pada artikel kali ini kita akan membahas situs judi online KantorBola yang menawarkan berbagai jenis aktivitas perjudian, antara lain permainan slot, taruhan olahraga, dan permainan live kasino. KantorBola telah mendapatkan popularitas dan pengaruh di komunitas perjudian online Indonesia, menjadikannya pilihan utama bagi banyak pemain.
Platform yang Digunakan KantorBola
Pertama, mari kita bahas tentang platform game yang digunakan oleh KantorBola. Jika dilihat dari tampilan situsnya, terlihat bahwa KantorBola menggunakan platform IDNplay. Namun mengapa KantorBola memilih platform ini padahal ada opsi lain seperti NEXUS, PAY4D, INFINITY, MPO, dan masih banyak lagi yang digunakan oleh agen judi lain? Dipilihnya IDN Play bukanlah hal yang mengherankan mengingat reputasinya sebagai penyedia platform judi online terpercaya, dimulai dari IDN Poker yang fenomenal.
Sebagai penyedia platform perjudian online terbesar, IDN Play memastikan koneksi yang stabil dan keamanan situs web terhadap pelanggaran data dan pencurian informasi pribadi dan sensitif pemain.
Jenis Permainan yang Ditawarkan KantorBola
KantorBola adalah portal judi online lengkap yang menawarkan berbagai jenis permainan judi online. Berikut beberapa permainan yang bisa Anda nikmati di website KantorBola:
Kasino Langsung: KantorBola menawarkan berbagai permainan kasino langsung, termasuk BACCARAT, ROULETTE, SIC-BO, dan BLACKJACK.
Sportsbook: Kategori ini mencakup semua taruhan olahraga online yang berkaitan dengan olahraga seperti sepak bola, bola basket, bola voli, tenis, golf, MotoGP, dan balap Formula-1. Selain pasar taruhan olahraga klasik, KantorBola juga menawarkan taruhan E-sports pada permainan seperti Mobile Legends, Dota 2, PUBG, dan sepak bola virtual.
Semua pasaran taruhan olahraga di KantorBola disediakan oleh bandar judi ternama seperti Sbobet, CMD-368, SABA Sports, dan TFgaming.
Slot Online: Sebagai salah satu situs judi online terpopuler, KantorBola menawarkan permainan slot dari penyedia slot terkemuka dan terpercaya dengan tingkat Return To Player (RTP) yang tinggi, rata-rata di atas 95%. Beberapa penyedia slot online unggulan yang bekerjasama dengan KantorBola antara lain PRAGMATIC PLAY, PG, HABANERO, IDN SLOT, NO LIMIT CITY, dan masih banyak lagi yang lainnya.
Permainan Poker di KantorBola: KantorBola yang didukung oleh IDN, pemilik platform poker uang asli IDN Poker, memungkinkan Anda menikmati semua permainan poker uang asli yang tersedia di IDN Poker. Selain permainan poker terkenal, Anda juga bisa memainkan berbagai permainan kartu di KantorBola, antara lain Super Ten (Samgong), Capsa Susun, Domino, dan Ceme.
Bolehkah Memasang Taruhan Togel di KantorBola?
Anda mungkin bertanya-tanya apakah Anda dapat memasang taruhan Togel (lotere) di KantorBola, meskipun namanya terutama dikaitkan dengan taruhan olahraga. Bahkan, KantorBola sebagai situs judi online terlengkap juga menyediakan pasaran taruhan Togel online. Togel yang ditawarkan adalah TOTO MACAU yang saat ini menjadi salah satu pilihan togel yang paling banyak dicari oleh masyarakat Indonesia. TOTO MACAU telah mendapatkan popularitas serupa dengan togel terkemuka lainnya seperti Togel Singapura dan Togel Hong Kong.
Promosi yang Ditawarkan oleh KantorBola
Pembahasan tentang KantorBola tidak akan lengkap tanpa menyebutkan promosi-promosi menariknya. Mari selami beberapa promosi terbaik yang bisa Anda nikmati sebagai anggota KantorBola:
Bonus Member Baru 1 Juta Rupiah: Promosi ini memungkinkan member baru untuk mengklaim bonus 1 juta Rupiah saat melakukan transaksi pertama di slot KantorBola. Syarat dan ketentuan khusus berlaku, jadi sebaiknya hubungi live chat KantorBola untuk detail selengkapnya.
Bonus Loyalty Member KantorBola Slot 100.000 Rupiah: Promosi ini dirancang khusus untuk para pecinta slot. Dengan mengikuti promosi slot KantorBola, Anda bisa mendapatkan tambahan modal bermain sebesar 100.000 Rupiah setiap harinya.
Bonus Rolling Hingga 1% dan Cashback 20%: Selain member baru dan bonus harian, KantorBola menawarkan promosi menarik lainnya, antara lain bonus rolling hingga 1% dan bonus cashback 20% untuk pemain yang mungkin belum memilikinya. semoga sukses dalam permainan mereka.
Ini hanyalah tiga dari promosi fantastis yang tersedia untuk anggota KantorBola. Masih banyak lagi promosi yang bisa dijelajahi. Untuk informasi selengkapnya, Anda dapat mengunjungi bagian “Promosi” di website KantorBola.
Kesimpulannya, KantorBola adalah platform perjudian online komprehensif yang menawarkan berbagai macam permainan menarik dan promosi yang menggiurkan. Baik Anda menyukai slot, taruhan olahraga, permainan kasino langsung, atau poker, KantorBola memiliki sesuatu untuk ditawarkan. Bergabunglah dengan komunitas KantorBola hari ini dan rasakan sensasi perjudian online terbaik!
labatoto
labatoto
Работа в Кемерово
In an era of rapidly advancing technology, the boundaries of what we once thought was possible are being shattered. From medical breakthroughs to artificial intelligence, the fusion of various fields has paved the way for groundbreaking discoveries. One such breathtaking development is the creation of a beautiful girl by a neural network based on a hand-drawn image. This extraordinary innovation offers a glimpse into the future where neural networks and genetic science combine to revolutionize our perception of beauty.
The Birth of a Digital “Muse”:
Imagine a scenario where you sketch a simple drawing of a girl, and by utilizing the power of a neural network, that drawing comes to life. This miraculous transformation from pen and paper to an enchanting digital persona leaves us in awe of the potential that lies within artificial intelligence. This incredible feat of science showcases the tremendous strides made in programming algorithms to recognize and interpret human visuals.
Beautiful girl 422d6d6
Hі! Sokeone in my Myspace group shared this sit with us sօ I camе to chck it out.
I’m definitеly enjoying the infߋrmation.
I’m bookmarking аnd will be tweeting this
to my followers! Outstanding blog аnd superb design.
mʏ website: Wat is een trending topic op social media?
b52 game đổi thưởng uy tín
B52 Club là một nền tảng chơi game trực tuyến thú vị đã thu hút hàng nghìn người chơi với đồ họa tuyệt đẹp và lối chơi hấp dẫn. Trong bài viết này, chúng tôi sẽ cung cấp cái nhìn tổng quan ngắn gọn về Câu lạc bộ B52, nêu bật những điểm mạnh, tùy chọn chơi trò chơi đa dạng và các tính năng bảo mật mạnh mẽ.
Câu lạc bộ B52 – Nơi Vui Gặp Thưởng
B52 Club mang đến sự kết hợp thú vị giữa các trò chơi bài, trò chơi nhỏ và máy đánh bạc, tạo ra trải nghiệm chơi game năng động cho người chơi. Dưới đây là cái nhìn sâu hơn về điều khiến B52 Club trở nên đặc biệt.
Giao dịch nhanh chóng và an toàn
B52 Club nổi bật với quy trình thanh toán nhanh chóng và thân thiện với người dùng. Với nhiều phương thức thanh toán khác nhau có sẵn, người chơi có thể dễ dàng gửi và rút tiền trong vòng vài phút, đảm bảo trải nghiệm chơi game liền mạch.
Một loạt các trò chơi
Câu lạc bộ B52 có bộ sưu tập trò chơi phổ biến phong phú, bao gồm Tài Xỉu (Xỉu), Poker, trò chơi jackpot độc quyền, tùy chọn sòng bạc trực tiếp và trò chơi bài cổ điển. Người chơi có thể tận hưởng lối chơi thú vị với cơ hội thắng lớn.
Bảo mật nâng cao
An toàn của người chơi và bảo mật dữ liệu là ưu tiên hàng đầu tại B52 Club. Nền tảng này sử dụng các biện pháp bảo mật tiên tiến, bao gồm xác thực hai yếu tố, để bảo vệ thông tin và giao dịch của người chơi.
Phần kết luận
Câu lạc bộ B52 là điểm đến lý tưởng của bạn để chơi trò chơi trực tuyến, cung cấp nhiều trò chơi đa dạng và phần thưởng hậu hĩnh. Với các giao dịch nhanh chóng và an toàn, cộng với cam kết mạnh mẽ về sự an toàn của người chơi, nó tiếp tục thu hút lượng người chơi tận tâm. Cho dù bạn là người đam mê trò chơi bài hay người hâm mộ giải đặc biệt, B52 Club đều có thứ gì đó dành cho tất cả mọi người. Hãy tham gia ngay hôm nay và trải nghiệm cảm giác thú vị khi chơi game trực tuyến một cách tốt nhất.
Подъем домов
link kantorbola99
Terrific forum posts. Cheers!
how to advertise resume writing service best assignment writing service uk free will writing service charity
b52 đổi thưởng
B52 Club là một nền tảng chơi game trực tuyến thú vị đã thu hút hàng nghìn người chơi với đồ họa tuyệt đẹp và lối chơi hấp dẫn. Trong bài viết này, chúng tôi sẽ cung cấp cái nhìn tổng quan ngắn gọn về Câu lạc bộ B52, nêu bật những điểm mạnh, tùy chọn chơi trò chơi đa dạng và các tính năng bảo mật mạnh mẽ.
Câu lạc bộ B52 – Nơi Vui Gặp Thưởng
B52 Club mang đến sự kết hợp thú vị giữa các trò chơi bài, trò chơi nhỏ và máy đánh bạc, tạo ra trải nghiệm chơi game năng động cho người chơi. Dưới đây là cái nhìn sâu hơn về điều khiến B52 Club trở nên đặc biệt.
Giao dịch nhanh chóng và an toàn
B52 Club nổi bật với quy trình thanh toán nhanh chóng và thân thiện với người dùng. Với nhiều phương thức thanh toán khác nhau có sẵn, người chơi có thể dễ dàng gửi và rút tiền trong vòng vài phút, đảm bảo trải nghiệm chơi game liền mạch.
Một loạt các trò chơi
Câu lạc bộ B52 có bộ sưu tập trò chơi phổ biến phong phú, bao gồm Tài Xỉu (Xỉu), Poker, trò chơi jackpot độc quyền, tùy chọn sòng bạc trực tiếp và trò chơi bài cổ điển. Người chơi có thể tận hưởng lối chơi thú vị với cơ hội thắng lớn.
Bảo mật nâng cao
An toàn của người chơi và bảo mật dữ liệu là ưu tiên hàng đầu tại B52 Club. Nền tảng này sử dụng các biện pháp bảo mật tiên tiến, bao gồm xác thực hai yếu tố, để bảo vệ thông tin và giao dịch của người chơi.
Phần kết luận
Câu lạc bộ B52 là điểm đến lý tưởng của bạn để chơi trò chơi trực tuyến, cung cấp nhiều trò chơi đa dạng và phần thưởng hậu hĩnh. Với các giao dịch nhanh chóng và an toàn, cộng với cam kết mạnh mẽ về sự an toàn của người chơi, nó tiếp tục thu hút lượng người chơi tận tâm. Cho dù bạn là người đam mê trò chơi bài hay người hâm mộ giải đặc biệt, B52 Club đều có thứ gì đó dành cho tất cả mọi người. Hãy tham gia ngay hôm nay và trải nghiệm cảm giác thú vị khi chơi game trực tuyến một cách tốt nhất.
robotic process automation
kantorbola77
Kantorbola telah mendapatkan pengakuan sebagai agen slot ternama di kalangan masyarakat Indonesia. Itu tidak berhenti di slot; ia juga menawarkan permainan Poker, Togel, Sportsbook, dan Kasino. Hanya dengan satu ID, Anda sudah bisa mengakses semua permainan yang ada di Kantorbola. Tidak perlu ragu bermain di situs slot online Kantorbola dengan RTP 98%, memastikan kemenangan mudah. Kantorbola adalah rekomendasi andalan Anda untuk perjudian online.
Kantorbola berdiri sebagai penyedia terkemuka dan situs slot online terpercaya No. 1, menawarkan RTP tinggi dan permainan slot yang mudah dimenangkan. Hanya dengan satu ID, Anda dapat menjelajahi berbagai macam permainan, antara lain Slot, Poker, Taruhan Olahraga, Live Casino, Idn Live, dan Togel.
Kantorbola telah menjadi nama terpercaya di industri perjudian online Indonesia selama satu dekade. Komitmen kami untuk memberikan layanan terbaik tidak tergoyahkan, dengan bantuan profesional kami tersedia 24/7. Kami menawarkan berbagai saluran untuk dukungan anggota, termasuk Obrolan Langsung, WhatsApp, WeChat, Telegram, Line, dan telepon.
Situs Slot Terbaik menjadi semakin populer di kalangan orang-orang dari segala usia. Dengan Situs Slot Gacor Kantorbola, Anda bisa menikmati tingkat kemenangan hingga 98%. Kami menawarkan berbagai metode pembayaran, termasuk transfer bank dan e-wallet seperti BCA, Mandiri, BRI, BNI, Permata, Panin, Danamon, CIMB, DANA, OVO, GOPAY, Shopee Pay, LinkAja, Jago One Mobile, dan Octo Mobile.
10 Game Judi Online Teratas Dengan Tingkat Kemenangan Tinggi di KANTORBOLA
Kantorbola menawarkan beberapa penyedia yang menguntungkan, dan kami ingin memperkenalkan penyedia yang saat ini berkembang pesat di platform Kantorbola. Hanya dengan satu ID pengguna, Anda dapat menikmati semua jenis permainan slot dan banyak lagi. Mari kita selidiki penyedia dan game yang saat ini mengalami tingkat keberhasilan tinggi:
penyedia dan permainan teratas yang saat ini berkinerja baik di Kantorbola].
Bergabunglah dengan Kantorbola hari ini dan rasakan keseruan serta potensi kemenangan yang ditawarkan platform kami. Jangan lewatkan kesempatan menang besar bersama Situs Slot Gacor Kantorbola dan tingkat kemenangan 98% yang luar biasa!
kantorbola
Агентство недвижимости
娛樂城優惠
2023年最熱門娛樂城優惠大全
尋找高品質的娛樂城優惠嗎?2023年富遊娛樂城帶來了一系列吸引人的優惠活動!無論您是新玩家還是老玩家,這裡都有豐富的優惠等您來領取。
富遊娛樂城新玩家優惠
體驗金$168元: 新玩家註冊即可享受,向客服申請即可領取。
首存送禮: 首次儲值$1000元,即可獲得額外的$1000元。
好禮5選1: 新會員一個月內存款累積金額達5000點,可選擇心儀的禮品一份。
老玩家專屬優惠
每日簽到: 每天簽到即可獲得$666元彩金。
推薦好友: 推薦好友成功註冊且首儲後,您可獲得$688元禮金。
天天返水: 每天都有返水優惠,最高可達0.7%。
如何申請與領取?
新玩家優惠: 註冊帳戶後聯繫客服,完成相應要求即可領取。
老玩家優惠: 只需完成每日簽到,或者通過推薦好友獲得禮金。
VIP會員: 滿足升級要求的會員將享有更多專屬福利與特權。
富遊娛樂城VIP會員
VIP會員可享受更多特權,包括升級禮金、每週限時紅包、生日禮金,以及更高比例的返水。成為VIP會員,讓您在娛樂的世界中享受更多的尊貴與便利!
探尋娛樂城的多元魅力
娛樂城近年來成為了眾多遊戲愛好者的熱門去處。在這裡,人們可以體驗到豐富多彩的遊戲並有機會贏得豐厚的獎金,正是這種刺激與樂趣使得娛樂城在全球範圍內越來越受歡迎。
娛樂城的多元遊戲
娛樂城通常提供一系列的娛樂選項,從經典的賭博遊戲如老虎機、百家樂、撲克,到最新的電子遊戲、體育賭博和電競項目,應有盡有,讓每位遊客都能找到自己的最愛。
娛樂城的優惠活動
娛樂城常會提供各種吸引人的優惠活動,例如新玩家註冊獎勵、首存贈送、以及VIP會員專享的多項福利,吸引了大量玩家前來參與。這些優惠不僅讓玩家獲得更多遊戲時間,還提高了他們贏得大獎的機會。
娛樂城的便利性
許多娛樂城都提供在線遊戲平台,玩家不必離開舒適的家就能享受到各種遊戲的樂趣。高品質的視頻直播和專業的遊戲平台讓玩家仿佛置身於真實的賭場之中,體驗到了無與倫比的遊戲感受。
娛樂城的社交體驗
娛樂城不僅僅是遊戲的天堂,更是社交的舞台。玩家可以在此結交來自世界各地的朋友,一邊享受遊戲的樂趣,一邊進行輕鬆愉快的交流。而且,許多娛樂城還會定期舉辦各種社交活動和比賽,進一步加深玩家之間的聯繫和友誼。
娛樂城的創新發展
隨著科技的快速發展,娛樂城也在不斷進行創新。虛擬現實(VR)、區塊鏈技術等新科技的應用,使得娛樂城提供了更多先進、多元和個性化的遊戲體驗。例如,通過VR技術,玩家可以更加真實地感受到賭場的氛圍和環境,得到更加沉浸和刺激的遊戲體驗。
[youtube – 0Un_hvmD9fs[/youtube –
2023娛樂城優惠富遊娛樂城提供返水優惠、生日禮金、升級禮金、儲值禮金、翻本禮金、娛樂城體驗金、簽到活動、好友介紹金、遊戲任務獎金、不論剛加入註冊的新手、還是老會員都各方面的優惠可以做選擇,活動優惠流水皆在合理範圍,讓大家領得開心玩得愉快。
娛樂城體驗金免費試玩如何領取?
娛樂城體驗金 (Casino Bonus) 是娛樂城給玩家的一種好處,通常用於鼓勵玩家在娛樂城中玩遊戲。 體驗金可能會在玩家首次存款時提供,或在玩家完成特定活動時獲得。 體驗金可能需要在某些遊戲中使用,或在達到特定條件後提現。 由於條款和條件會因娛樂城而異,因此建議在使用體驗金之前仔細閱讀娛樂城的條款和條件。
This design is steller! You obviously know how to keep a reader amused. Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Excellent job. I really loved what you had to say, and more than that, how you presented it. Too cool!
百家樂
百家樂是賭場中最古老且最受歡迎的博奕遊戲,無論是實體還是線上娛樂城都有其踪影。其簡單的規則和公平的遊戲機制吸引了大量玩家。不只如此,線上百家樂近年來更是受到玩家的喜愛,其優勢甚至超越了知名的實體賭場如澳門和拉斯維加斯。
百家樂入門介紹
百家樂(baccarat)是一款起源於義大利的撲克牌遊戲,其名稱在英文中是「零」的意思。從十五世紀開始在法國流行,到了十九世紀,這款遊戲在英國和法國都非常受歡迎。現今百家樂已成為全球各大賭場和娛樂城中的熱門遊戲。(來源: wiki百家樂 )
百家樂主要是玩家押注莊家或閒家勝出的遊戲。參與的人數沒有限制,不只坐在賭桌的玩家,旁邊站立的人也可以下注。
娛樂城
探尋娛樂城的多元魅力
娛樂城近年來成為了眾多遊戲愛好者的熱門去處。在這裡,人們可以體驗到豐富多彩的遊戲並有機會贏得豐厚的獎金,正是這種刺激與樂趣使得娛樂城在全球範圍內越來越受歡迎。
娛樂城的多元遊戲
娛樂城通常提供一系列的娛樂選項,從經典的賭博遊戲如老虎機、百家樂、撲克,到最新的電子遊戲、體育賭博和電競項目,應有盡有,讓每位遊客都能找到自己的最愛。
娛樂城的優惠活動
娛樂城常會提供各種吸引人的優惠活動,例如新玩家註冊獎勵、首存贈送、以及VIP會員專享的多項福利,吸引了大量玩家前來參與。這些優惠不僅讓玩家獲得更多遊戲時間,還提高了他們贏得大獎的機會。
娛樂城的便利性
許多娛樂城都提供在線遊戲平台,玩家不必離開舒適的家就能享受到各種遊戲的樂趣。高品質的視頻直播和專業的遊戲平台讓玩家仿佛置身於真實的賭場之中,體驗到了無與倫比的遊戲感受。
娛樂城的社交體驗
娛樂城不僅僅是遊戲的天堂,更是社交的舞台。玩家可以在此結交來自世界各地的朋友,一邊享受遊戲的樂趣,一邊進行輕鬆愉快的交流。而且,許多娛樂城還會定期舉辦各種社交活動和比賽,進一步加深玩家之間的聯繫和友誼。
娛樂城的創新發展
隨著科技的快速發展,娛樂城也在不斷進行創新。虛擬現實(VR)、區塊鏈技術等新科技的應用,使得娛樂城提供了更多先進、多元和個性化的遊戲體驗。例如,通過VR技術,玩家可以更加真實地感受到賭場的氛圍和環境,得到更加沉浸和刺激的遊戲體驗。
rtpkantorbola
Kantorbola situs slot online terbaik 2023 , segera daftar di situs kantor bola dan dapatkan promo terbaik bonus deposit harian 100 ribu , bonus rollingan 1% dan bonus cashback mingguan . Kunjungi juga link alternatif kami di kantorbola77 , kantorbola88 dan kantorbola99
kdbet
KDslots merupakan Agen casino online dan slots game terkenal di Asia. Mainkan game slots dan live casino raih kemenangan di game live casino dan slots game indonesia
Target88
brillx скачать
https://brillx-kazino.com
Brillx Казино – это не только великолепный ассортимент игр, но и высокий уровень сервиса. Наша команда профессионалов заботится о каждом игроке, обеспечивая полную поддержку и честную игру. На нашем сайте брилкс казино вы найдете не только классические слоты, но и уникальные вариации игр, созданные специально для вас.Добро пожаловать в удивительный мир азарта и веселья на официальном сайте казино Brillx! Год 2023 принес нам новые горизонты в мире азартных развлечений, и Brillx на переднем крае этой революции. Если вы ищете непередаваемые ощущения и возможность сорвать джекпот, то вы пришли по адресу.
TARGET88: The Best Slot Deposit Pulsa Gambling Site in Indonesia
TARGET88 stands as the top slot deposit pulsa gambling site in 2020 in Indonesia, offering a wide array of slot machine gambling options. Beyond slots, we provide various other betting opportunities such as sportsbook betting, live online casinos, and online poker. With just one ID, you can enjoy all the available gambling options.
What sets TARGET88 apart is our official licensing from PAGCOR (Philippine Amusement Gaming Corporation), ensuring a safe environment for our users. Our platform is backed by fast hosting servers, state-of-the-art encryption methods to safeguard your data, and a modern user interface for your convenience.
But what truly makes TARGET88 special is our practical deposit method. We allow users to make deposits using XL or Telkomsel pulses, with the lowest deductions compared to other gambling sites. This feature has made us one of the largest pulsa gambling sites in Indonesia. You can even use official e-commerce platforms like OVO, Gopay, Dana, or popular minimarkets like Indomaret and Alfamart to make pulse deposits.
We’re renowned as a trusted SBOBET soccer agent, always ensuring prompt payments for our members’ winnings. SBOBET offers a wide range of sports betting options, including basketball, football, tennis, ice hockey, and more. If you’re looking for a reliable SBOBET agent, TARGET88 is the answer you can trust. Besides SBOBET, we also provide CMD365, Song88, UBOBET, and more, making us the best online soccer gambling agent of all time.
Live online casino games replicate the experience of a physical casino. At TARGET88, you can enjoy various casino games such as slots, baccarat, dragon tiger, blackjack, sicbo, and more. Our live casino games are broadcast in real-time, featuring beautiful live dealers, creating an authentic casino atmosphere without the need to travel abroad.
Poker enthusiasts will find a home at TARGET88, as we offer a comprehensive selection of online poker games, including Texas Hold’em, Blackjack, Domino QQ, BandarQ, AduQ, and more. This extensive offering makes us one of the most comprehensive and largest online poker gambling agents in Indonesia.
To sweeten the deal, we have a plethora of enticing promotions available for our online slot, roulette, poker, casino, and sports betting sections. These promotions cater to various preferences, such as parlay promos for sports bettors, a 20% welcome bonus, daily deposit bonuses, and weekly cashback or rolling rewards. You can explore these promotions to enhance your gaming experience.
Our professional and friendly Customer Service team is available 24/7 through Live Chat, WhatsApp, Facebook, and more, ensuring that you have a seamless gambling experience on TARGET88.
MAGNUMBET merupakan daftar agen judi slot online gacor terbaik dan terpercaya Indonesia. Kami menawarkan game judi slot online gacor teraman, terbaru dan terlengkap yang punya jackpot maxwin terbesar. Setidaknya ada ratusan juta rupiah yang bisa kamu nikmati dengan mudah bersama kami. MAGNUMBET juga menawarkan slot online deposit pulsa yang aman dan menyenangkan. Tak perlu khawatir soal minimal deposit yang harus dibayarkan ke agen slot online. Setiap member cukup bayar Rp 10 ribu saja untuk bisa memainkan berbagai slot online pilihan
sapporo88
Работа в Новокузнецке
miya4d
I am currently writing a paper that is very related to your content. I read your article and I have some questions. I would like to ask you. Can you answer me? I’ll keep an eye out for your reply. 20bet
Kantorbola adalah situs slot gacor terbaik di indonesia , kunjungi situs RTP kantor bola untuk mendapatkan informasi akurat slot dengan rtp diatas 95% . Kunjungi juga link alternatif kami di kantorbola77 dan kantorbola99
Hello colleagues, nice paragraph and fastidious arguments commented
here, I am genuinely enjoying by these.
https://jobejobs.ru
Login Surgaslot
Selamat datang di Surgaslot !! situs slot deposit dana terpercaya nomor 1 di Indonesia. Sebagai salah satu situs agen slot online terbaik dan terpercaya, kami menyediakan banyak jenis variasi permainan yang bisa Anda nikmati. Semua permainan juga bisa dimainkan cukup dengan memakai 1 user-ID saja. Surgaslot sendiri telah dikenal sebagai situs slot tergacor dan terpercaya di Indonesia. Dimana kami sebagai situs slot online terbaik juga memiliki pelayanan customer service 24 jam yang selalu siap sedia dalam membantu para member. Kualitas dan pengalaman kami sebagai salah satu agen slot resmi terbaik tidak perlu diragukan lagi
rtpkantorbola
Kantorbola adalah situs slot gacor terbaik di indonesia , kunjungi situs RTP kantor bola untuk mendapatkan informasi akurat slot dengan rtp diatas 95% . Kunjungi juga link alternatif kami di kantorbola77 dan kantorbola99
Do you have any video of that? I’d want to find out some additional information.
What’s up mates, how is everything, and what you wish
for to say regarding this article, in my view its actually awesome for me.
brillx casino официальный мобильная версия
https://brillx-kazino.com
Добро пожаловать в увлекательный мир азарта и развлечений на официальном сайте Brillx Казино! Если вы ищете захватывающий опыт игры в игровые аппараты, то ваш поиск завершен. Brillx Казино – это не просто блистательный выбор игр, это настоящее путешествие в мир азарта и возможностей.В 2023 году Brillx Казино стало настоящим оазисом для азартных путешественников. Подарите себе незабываемые моменты радости и азарта. Не упустите свой шанс сорвать куш и стать частью легендарной истории на страницах брилкс казино.
Thanks for one’s marvelous posting! I certainly enjoyed reading it, you will be
a great author. I will be sure to bookmark your
blog and will often come back later on. I want to encourage
continue your great writing, have a nice evening!
https://jobejobs.ru
Thank you, I have recently been searching for information about this topic
for a long time and yours is the best I’ve discovered
so far. However, what concerning the conclusion? Are you certain about the supply?
hi!,I really like your writing so a lot!
percentage we keep up a correspondence extra about
your article on AOL? I need a specialist in this house to
unravel my problem. May be that is you! Taking a look forward to see you.
Aw, this was a very nice post. Spending some time and
actual effort to create a great article… but what can I say… I hesitate a lot and never seem to get nearly anything done.
Thank you a bunch for sharing this with all of us you really
know what you are speaking about! Bookmarked. Please also discuss with my site =).
We may have a hyperlink trade agreement among us
I am actually delighted to glance at this blog posts which includes tons of helpful facts, thanks for providing
these kinds of data.
Blackpanther77 slot
Awesome issues here. I’m very happy to see your article.
Thanks a lot and I am taking a look forward to touch you.
Will you please drop me a e-mail?
This site was… how do I say it? Relevant!! Finally I’ve found something that
helped me. Thanks!
Hi there it’s me, I am also visiting this site regularly, this website is actually good and
the people are really sharing pleasant thoughts.
Unquestionably believe that which you stated. Your favorite reason seemed to be on the internet the simplest
thing to be aware of. I say to you, I certainly get annoyed while people think about worries
that they just don’t know about. You managed to
hit the nail upon the top and defined out the whole thing without having side effect ,
people can take a signal. Will probably be back to get more.
Thanks
I got this web page from my pal who shared with me concerning this website and now this time I am browsing this site and reading very informative articles at
this place.
Superb post but I was wanting to know if you could write a litte more
on this subject? I’d be very grateful if you could elaborate a little
bit further. Cheers!
Superb blog! Do you have any tips and hints for aspiring writers?
I’m hoping to start my own website soon but I’m a little lost on everything.
Would you suggest starting with a free platform like WordPress or go for a paid option? There are so many choices out there that I’m totally
confused .. Any ideas? Kudos!
berita sumut terkini
539開獎
今彩539開獎號碼查詢
大樂透開獎號碼查詢
大樂透開獎號碼查詢
威力彩開獎號碼查詢
Thhank yоu foг any other informative site. The pⅼace eⅼse ckuld I am gеtting thnat type of іnformation ѡritten іn sᥙch a perfect method?
I have a mission thɑt I ɑm just noww operatikng οn, and I have been at the lⲟok out
forr ѕuch infοrmation.
Αlso visit mʏ homepaɡe sky sports son xəbərlər
三星彩開獎號碼查詢
三星彩開獎號碼查詢
運彩分析
539
美棒分析
2024總統大選
hoki1881
bata4d
bata4d
1881 hoki
Kantorbola adalah situs slot gacor terbaik di indonesia , kunjungi situs RTP kantor bola untuk mendapatkan informasi akurat slot dengan rtp diatas 95% . Kunjungi juga link alternatif kami di kantorbola77 dan kantorbola99 .
Wһat’s upp too every , Ьecause Ι am acrually keen oof reading
tһіѕ blog’s post tо Ьe updated regularly.
It іncludes good data.
Feel free to surf to mу webpage – sportoj vivas
hoki 1881
blangkon slot
Blangkon slot adalah situs slot gacor dan judi slot online gacor hari ini mudah menang. Blangkonslot menyediakan semua permainan slot gacor dan judi online terbaik seperti, slot online gacor, live casino, judi bola/sportbook, poker online, togel online, sabung ayam dll. Hanya dengan 1 user id kamu sudah bisa bermain semua permainan yang sudah di sediakan situs terbaik BLANGKON SLOT. Selain itu, kamu juga tidak usah ragu lagi untuk bergabung dengan kami situs judi online terbesar dan terpercaya yang akan membayar berapapun kemenangan kamu.
rikvip
smtogel
whoah this blog is magnificent i reaⅼly liқe studying yоur articles.
Stay up tһe gooԁ ԝork! You realize, ⅼots of individuals are hunting гound fοr this
infߋrmation, you cаn helр them grеatly.
Loߋk аt my web рage – trendikkäitä uutisia Internetissä
bocor88
winstarbet
winstarbet
Tarot Online
Mestres Místicos é o maior portal de Tarot Online do Brasil e Portugal, o site conta com os melhores Místicos online, tarólogos, cartomantes, videntes, sacerdotes, 24 horas online para fazer sua consulta de tarot pago por minuto via chat ao vivo, temos mais de 700 mil atendimentos e estamos no ar desde 2011
bocor88
bocor88
Kampus Unggul
Kampus Unggul
UHAMKA offers prospective/transfer/conversion students an easy access to get information and to enroll classes online.
supermoney88
supermoney88
Tentang SUPERMONEY88: Situs Game Online Deposit Pulsa Terbaik 2020 di Indonesia
Di era digital seperti sekarang, perjudian online telah menjadi pilihan hiburan yang populer. Terutama di Indonesia, SUPERMONEY88 telah menjadi pelopor dalam dunia game online. Dengan fokus pada deposit pulsa dan berbagai jenis permainan judi, kami telah menjadi situs game online terbaik tahun 2020 di Indonesia.
Agen Game Online Terlengkap:
Kami bangga menjadi tujuan utama Anda untuk segala bentuk taruhan mesin game online. Di SUPERMONEY88, Anda dapat menemukan beragam permainan, termasuk game bola Sportsbook, live casino online, poker online, dan banyak jenis taruhan lainnya yang wajib Anda coba. Hanya dengan mendaftar 1 ID, Anda dapat memainkan seluruh permainan judi yang tersedia. Kami adalah situs slot online terbaik yang menawarkan pilihan permainan terlengkap.
Lisensi Resmi dan Keamanan Terbaik:
Keamanan adalah prioritas utama kami. SUPERMONEY88 adalah agen game online berlisensi resmi dari PAGCOR (Philippine Amusement Gaming Corporation). Lisensi ini menunjukkan komitmen kami untuk menyediakan lingkungan perjudian yang aman dan adil. Kami didukung oleh server hosting berkualitas tinggi yang memastikan akses cepat dan keamanan sistem dengan metode enkripsi terkini di dunia.
Deposit Pulsa dengan Potongan Terendah:
Kami memahami betapa pentingnya kenyamanan dalam melakukan deposit. Itulah mengapa kami memungkinkan Anda untuk melakukan deposit pulsa dengan potongan terendah dibandingkan dengan situs game online lainnya. Kami menerima deposit pulsa dari XL dan Telkomsel, serta melalui E-Wallet seperti OVO, Gopay, Dana, atau melalui minimarket seperti Indomaret dan Alfamart. Kemudahan ini menjadikan SUPERMONEY88 sebagai salah satu situs GAME ONLINE PULSA terbesar di Indonesia.
Agen Game Online SBOBET Terpercaya:
Kami dikenal sebagai agen game online SBOBET terpercaya yang selalu membayar kemenangan para member. SBOBET adalah perusahaan taruhan olahraga terkemuka dengan beragam pilihan olahraga seperti sepak bola, basket, tenis, hoki, dan banyak lainnya. SUPERMONEY88 adalah jawaban terbaik jika Anda mencari agen SBOBET yang dapat dipercayai. Selain SBOBET, kami juga menyediakan CMD365, Song88, UBOBET, dan lainnya. Ini menjadikan kami sebagai bandar agen game online bola terbaik sepanjang masa.
Game Casino Langsung (Live Casino) Online:
Jika Anda suka pengalaman bermain di kasino fisik, kami punya solusi. SUPERMONEY88 menyediakan jenis permainan judi live casino online. Anda dapat menikmati game seperti baccarat, dragon tiger, blackjack, sic bo, dan lainnya secara langsung. Semua permainan disiarkan secara LIVE, sehingga Anda dapat merasakan atmosfer kasino dari kenyamanan rumah Anda.
Game Poker Online Terlengkap:
Poker adalah permainan strategi yang menantang, dan kami menyediakan berbagai jenis permainan poker online. SUPERMONEY88 adalah bandar game poker online terlengkap di Indonesia. Mulai dari Texas Hold’em, BlackJack, Domino QQ, BandarQ, hingga AduQ, semua permainan poker favorit tersedia di sini.
Promo Menarik dan Layanan Pelanggan Terbaik:
Kami juga menawarkan banyak promo menarik yang bisa Anda nikmati saat bermain, termasuk promo parlay, bonus deposit harian, cashback, dan rollingan mingguan. Tim Customer Service kami yang profesional dan siap membantu Anda 24/7 melalui Live Chat, WhatsApp, Facebook, dan media sosial lainnya.
Jadi, jangan ragu lagi! Bergabunglah dengan SUPERMONEY88 sekarang dan nikmati pengalaman perjudian online terbaik di Indonesia.
sunmory33
tuan88 slot
smtogel login
slot pro88
slot mantul88
target88
supermoney88 site
brillx casino официальный сайт
https://brillx-kazino.com
Сияющие огни бриллкс казино приветствуют вас в уникальной атмосфере азартных развлечений. В 2023 году мы рады предложить вам возможность играть онлайн бесплатно или на деньги в самые захватывающие игровые аппараты. Наши эксклюзивные игры станут вашим партнером в незабываемом приключении, где каждое вращение барабанов приносит невероятные эмоции.В 2023 году Brillx предлагает совершенно новые уровни азарта. Мы гордимся тем, что привносим инновации в каждый аспект игрового процесса. Наши разработчики работают над уникальными и захватывающими играми, которые вы не найдете больше нигде. От момента входа на сайт до момента, когда вы выигрываете крупную сумму на наших аппаратах, вы будете окружены неповторимой атмосферой удовольствия и удачи.
RuneScape, a beloved online gaming world for many, offers a myriad of opportunities for players to amass wealth and power within the game. While earning RuneScape Gold (RS3 or OSRS GP) through gameplay is undoubtedly a rewarding experience, some players seek a more convenient and streamlined path to enhancing their RuneScape journey. In this article, we explore the advantages of purchasing OSRS Gold and how it can elevate your RuneScape adventure to new heights.
A Shortcut to Success:
a. Boosting Character Power:
In the world of RuneScape, character strength is significantly influenced by the equipment they wield and their skill levels. Acquiring top-tier gear and leveling up skills often requires time and effort. Purchasing OSRS Gold allows players to expedite this process and empower their characters with the best equipment available.
b. Tackling Formidable Foes:
RuneScape is replete with challenging monsters and bosses. With the advantage of enhanced gear and skills, players can confidently confront these formidable adversaries, secure victories, and reap the rewards that follow. OSRS Gold can be the key to overcoming daunting challenges.
c. Questing with Ease:
Many RuneScape quests present complex puzzles and trials. By purchasing OSRS Gold, players can eliminate resource-gathering and level-grinding barriers, making quests smoother and more enjoyable. It’s all about focusing on the adventure, not the grind.
Expanding Possibilities:
d. Rare Items and Valuable Equipment:
The RuneScape world is rich with rare and coveted items. By acquiring OSRS Gold, players can gain access to these valuable assets. Rare armor, powerful weapons, and other coveted equipment can be yours, enhancing your character’s capabilities and opening up new gameplay experiences.
e. Participating in Limited-Time Events:
RuneScape often features limited-time in-game events with exclusive rewards. Having OSRS Gold at your disposal allows you to fully embrace these events, purchase unique items, and partake in memorable experiences that may not be available to others.
Conclusion:
Purchasing OSRS Gold undoubtedly offers RuneScape players a convenient shortcut to success. By empowering characters with superior gear and skills, players can take on any challenge the game throws their way. Furthermore, the ability to purchase rare items and participate in exclusive events enhances the overall gaming experience, providing new dimensions to explore within the RuneScape universe. While earning gold through gameplay remains a cherished aspect of RuneScape, buying OSRS Gold can make your journey even more enjoyable, rewarding, and satisfying. So, embark on your adventure, equip your character, and conquer RuneScape with the power of OSRS Gold.
RSG雷神
RSG雷神
RSG雷神:電子遊戲的新維度
在電子遊戲的世界裡,不斷有新的作品出現,但要在眾多的遊戲中脫穎而出,成為玩家心中的佳作,需要的不僅是創意,還需要技術和努力。而當我們談到RSG雷神,就不得不提它如何將遊戲提升到了一個全新的層次。
首先,RSG已經成為了許多遊戲愛好者的口中的熱詞。每當提到RSG雷神,人們首先想到的就是品質保證和無與倫比的遊戲體驗。但這只是RSG的一部分,真正讓玩家瘋狂的,是那款被稱為“雷神之鎚”的老虎機遊戲。
RSG雷神不僅僅是一款老虎機遊戲,它是一場視覺和聽覺的盛宴。遊戲中精緻的畫面、逼真的音效和流暢的動畫,讓玩家仿佛置身於雷神的世界,每一次按下開始鍵,都像是在揮動雷神的鎚子,帶來震撼的遊戲體驗。
這款遊戲的成功,並不只是因為它的外觀或音效,更重要的是它那精心設計的遊戲機制。玩家可以根據自己的策略選擇不同的下注方式,每一次旋轉,都有可能帶來意想不到的獎金。這種刺激和期待,使得玩家一次又一次地沉浸在遊戲中,享受著每一分每一秒。
但RSG雷神並沒有因此而止步。它的研發團隊始終在尋找新的創意和技術,希望能夠為玩家帶來更多的驚喜。無論是遊戲的內容、機制還是畫面效果,RSG雷神都希望能夠做到最好,成為遊戲界的佼佼者。
總的來說,RSG雷神不僅僅是一款遊戲,它是一種文化,一種追求。對於那些熱愛遊戲、追求刺激的玩家來說,它提供了一個完美的平台,讓玩家能夠體驗到真正的遊戲樂趣。
Vietlott
Kampus Unggul
Kampus Unggul
UHAMKA offers prospective/transfer/conversion students an easy access to get information and to enroll classes online
bocor88
Convert Figma to Android
buy osrs gold
Kampus Unggul
UHAMKA offers prospective/transfer/conversion students an easy access to get information and to enroll classes online.
Saved ɑѕ a favorite, I reаlly lіke yօur site!
Ⅿy blog posst jasa backlink judi
Kampus Unggul
Kampus Unggul
UHAMKA offers prospective/transfer/conversion students an easy access to get information and to enroll classes online.
masuk hoki1881
Работа вахтовым методом
Informasi hewan
Figma plugin for React
Very ɡreat post. Ι simply stumbled սpon yоur blog
and wanted tߋ mention that I hɑve truly loved browsing your blog posts.
Іn any caѕe I’ll be subscribing tо your
rss feed and Ӏ hope уou wгite again soߋn!
Нere is my web blog :: seo bulanan
truyện tranh
Christmas Deals
microlearning content library
nettruyenmax
man club
https://budumamoi.com/pag/mostbet_promokod_pri_registracii.html
Промокод 1xBet «Max2x» 2023: разблокируйте бонус 130%
Промокод 1xBet 2023 года «Max2x» может улучшить ваш опыт онлайн-ставок. Используйте его при регистрации, чтобы получить бонус на депозит в размере 130%. Вот краткий обзор того, как это работает, где его найти и его преимущества.
Понимание промокодов 1xBet
Промокоды 1xBet — это специальные предложения букмекерской конторы, которые сделают ваши ставки еще интереснее. Они представляют собой уникальные комбинации символов, букв и цифр, открывающие бонусы и привилегии как для новых, так и для существующих игроков.
Новые игроки часто используют промокоды при регистрации, привлекая их заманчивыми бонусами. Это одноразовое использование для создания новой учетной записи. Существующие клиенты получают различные промокоды, соответствующие их потребностям.
Получение промокодов 1xBet
Для начинающих:
Новые игроки могут найти коды в Интернете, часто на веб-сайтах и форумах, что мотивирует их создавать учетные записи, предлагая бонусы. Вы также можете найти их на страницах 1xBet в социальных сетях или на партнерских платформах.
От букмекера:
1xBet награждает постоянных клиентов промокодами, которые доставляются по электронной почте или в уведомлениях учетной записи.
Демонстрация промокода:
Проверяйте «Витрину промокодов» на веб-сайте 1xBet, чтобы регулярно обновлять коды.
Таким образом, промокод 1xBet «Max2x» расширяет возможности ваших онлайн-ставок. Это ценный инструмент для новичков и опытных игроков. Следите за этими кодами из различных источников, чтобы максимизировать свои приключения в ставках 1xBet.
daftar surgaslot77
SURGASLOT77 – #1 Top Gamer Website in Indonesia
SURGASLOT77 merupakan halaman website hiburan online andalan di Indonesia.
DG百家樂
Абузоустойчивый VPS
Улучшенное предложение VPS/VDS: начиная с 13 рублей для Windows и Linux
Добейтесь максимальной производительности и надежности с использованием SSD eMLC
Один из ключевых аспектов в мире виртуальных серверов – это выбор оптимального хранилища данных. Наши VPS/VDS-серверы, совместимые как с операционными системами Windows, так и с Linux, предоставляют доступ к передовым накопителям SSD eMLC. Эти накопители гарантируют выдающуюся производительность и непрерывную надежность, обеспечивая бесперебойную работу ваших приложений, независимо от выбора операционной системы.
Высокоскоростной доступ в Интернет: до 1000 Мбит/с
Скорость подключения к Интернету – еще один важный фактор для успеха вашего проекта. Наши VPS/VDS-серверы, поддерживаемые как Windows, так и Linux, гарантируют доступ в Интернет со скоростью до 1000 Мбит/с, что обеспечивает мгновенную загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Абузоустойчивый VPS
Абузоустойчивый VPS
1xbet
Kantor bola Merupakan agen slot terpercaya di indonesia dengan RTP kemenangan sangat tinggi 98.9%. Bermain di kantorbola akan sangat menguntungkan karena bermain di situs kantorbola sangat gampang menang.
Do you mond іf I quote a few of your articles as long aas І provide
credit ɑnd sources bɑck to yokur weblog? My blog іs in the exact
sɑme niche aѕ yߋurs andd my usеrs woulkd genuinely benefit fгom some οf the іnformation yⲟu provide һere.
Please ⅼet me knoѡ if thіs aleight with үou.
Ꮢegards!
My web site … beli like instagram permanen
labatoto
2023-24英超聯賽萬眾矚目,2023年8月12日開啟了第一場比賽,而接下來的賽事也正如火如荼地進行中。本文統整出英超賽程以及英超賽制等資訊,幫助你更加了解英超,同時也提供英超直播平台,讓你絕對不會錯過每一場精彩賽事。
英超是什麼?
英超是相當重要的足球賽事,以競爭激烈和精彩程度聞名
英超是相當重要的足球賽事,以競爭激烈和精彩程度聞名
英超全名為「英格蘭足球超級聯賽」,是足球賽事中最高級的足球聯賽之一,由英格蘭足球總會在1992年2月20日成立。英超是全世界最多人觀看的體育聯賽,因其英超隊伍全球知名度和競爭激烈而聞名,吸引來自世界各地的頂尖球星前來參賽。
英超聯賽(English Premier League,縮寫EPL)由英國最頂尖的20支足球俱樂部參加,賽季通常從8月一直持續到5月,以下帶你來了解英超賽制和其他更詳細的資訊。
英超賽制
2023-24英超總共有20支隊伍參賽,以下是英超賽制介紹:
採雙循環制,分主場及作客比賽,每支球隊共進行 38 場賽事。
比賽採用三分制,贏球獲得3分,平局獲1分,輸球獲0分。
以積分多寡分名次,若同分則以淨球數來區分排名,仍相同就以得球計算。如果還是相同,就會於中立場舉行一場附加賽決定排名。
賽季結束後,根據積分排名,最高分者成為冠軍,而最後三支球隊則降級至英冠聯賽。
英超升降級機制
英超有一個相當特別的賽制規定,那就是「升降級」。賽季結束後,積分和排名最高的隊伍將直接晉升冠軍,而總排名最低的3支隊伍會被降級至英格蘭足球冠軍聯賽(英冠),這是僅次於英超的足球賽事。
同時,英冠前2名的球隊直接升上下一賽季的英超,第3至6名則會以附加賽決定最後一個升級名額,英冠的隊伍都在爭取升級至英超,以獲得更高的收入和榮譽。
英超
2023-24英超聯賽萬眾矚目,2023年8月12日開啟了第一場比賽,而接下來的賽事也正如火如荼地進行中。本文統整出英超賽程以及英超賽制等資訊,幫助你更加了解英超,同時也提供英超直播平台,讓你絕對不會錯過每一場精彩賽事。
英超是什麼?
英超是相當重要的足球賽事,以競爭激烈和精彩程度聞名
英超是相當重要的足球賽事,以競爭激烈和精彩程度聞名
英超全名為「英格蘭足球超級聯賽」,是足球賽事中最高級的足球聯賽之一,由英格蘭足球總會在1992年2月20日成立。英超是全世界最多人觀看的體育聯賽,因其英超隊伍全球知名度和競爭激烈而聞名,吸引來自世界各地的頂尖球星前來參賽。
英超聯賽(English Premier League,縮寫EPL)由英國最頂尖的20支足球俱樂部參加,賽季通常從8月一直持續到5月,以下帶你來了解英超賽制和其他更詳細的資訊。
英超賽制
2023-24英超總共有20支隊伍參賽,以下是英超賽制介紹:
採雙循環制,分主場及作客比賽,每支球隊共進行 38 場賽事。
比賽採用三分制,贏球獲得3分,平局獲1分,輸球獲0分。
以積分多寡分名次,若同分則以淨球數來區分排名,仍相同就以得球計算。如果還是相同,就會於中立場舉行一場附加賽決定排名。
賽季結束後,根據積分排名,最高分者成為冠軍,而最後三支球隊則降級至英冠聯賽。
英超升降級機制
英超有一個相當特別的賽制規定,那就是「升降級」。賽季結束後,積分和排名最高的隊伍將直接晉升冠軍,而總排名最低的3支隊伍會被降級至英格蘭足球冠軍聯賽(英冠),這是僅次於英超的足球賽事。
同時,英冠前2名的球隊直接升上下一賽季的英超,第3至6名則會以附加賽決定最後一個升級名額,英冠的隊伍都在爭取升級至英超,以獲得更高的收入和榮譽。
казино brillx официальный сайт играть
brillx официальный сайт
Брилкс Казино – это небывалая возможность погрузиться в атмосферу роскоши и азарта. Каждая деталь сайта продумана до мельчайших нюансов, чтобы обеспечить вам комфортное и захватывающее игровое пространство. На страницах Brillx Казино вы найдете множество увлекательных игровых аппаратов, которые подарят вам эмоции, сравнимые только с реальной азартной столицей.Брилкс казино предоставляет выгодные бонусы и акции для всех игроков. У нас вы найдете не только классические слоты, но и современные игровые разработки с прогрессивными джекпотами. Так что, возможно, именно здесь вас ждет величайший выигрыш, который изменит вашу жизнь навсегда!
b29
b29
VPS SERVER
Высокоскоростной доступ в Интернет: до 1000 Мбит/с
Скорость подключения к Интернету — еще один важный фактор для успеха вашего проекта. Наши VPS/VDS-серверы, адаптированные как под Windows, так и под Linux, обеспечивают доступ в Интернет со скоростью до 1000 Мбит/с, что гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
You made the point.
thesis proposal writing service essay typer free real estate blog writing service
kantorbola99
KANTOR BOLA adalah Situs Taruhan Bola untuk JUDI BOLA dengan kelengkapan permainan Taruhan Bola Online diantaranya Sbobet, M88, Ubobet, Cmd, Oriental Gaming dan masih banyak lagi Judi Bola Online lainnya. Dapatkan promo bonus deposit harian 25% dan bonus rollingan hingga 1% . Temukan juga kami dilink kantorbola77 , kantorbola88 dan kantorbola99
Good day! Would you mind if I share your blog with my twitter group? There’s a lot of folks that I think would really enjoy your content. Please let me know. Cheers
With thanks. Awesome information!
essay writing helper free affordable essay writing service writing essays services
Kudos. An abundance of data!
science resume writing service top 5 essay writing services best cheap essay writing service
You mentioned this fantastically!
what should i write my this i believe essay on essay expander writing services for college papers
Kampus berkualitas
tài xỉu vin
situs pro88
Very qᥙickly this web paɡe will be famous amid аll
blogging viewers, ⅾue to іt’s pleasant articles
оr reviews
ᒪоok at mʏ website Beli followers pinterest
MAGNUMBET Situs Online Dengan Deposit Pulsa Terpercaya. Magnumbet agen casino online indonesia terpercaya menyediakan semua permainan slot online live casino dan tembak ikan dengan minimal deposit hanya 10.000 rupiah sudah bisa bermain di magnumbet
game online hoki1881
Абузоустойчивый VPS
Виртуальные серверы VPS/VDS: Путь к Успешному Бизнесу
В мире современных технологий и онлайн-бизнеса важно иметь надежную инфраструктуру для развития проектов и обеспечения безопасности данных. В этой статье мы рассмотрим, почему виртуальные серверы VPS/VDS, предлагаемые по стартовой цене всего 13 рублей, являются ключом к успеху в современном бизнесе
https://prednisone.digital/# prednisone coupon
B52
B52
This post is invaluable. How can I find out more?
Aw, this was a very nice post. Spending some time and actual effort
to generate a good article… but what can I say… I procrastinate a whole lot and never manage to get anything done.
Really when someone doesn’t be aware of after that its up to other users that they
will help, so here it occurs.
you’re actually a excellent webmaster. The site loading velocity is incredible.
It seems that you are doing any distinctive trick.
Moreover, The contents are masterpiece. you have done a magnificent process in this topic!
What’s up, just wanted to tell you, I loved this post. It was practical.
Keep on posting!
I’m curious to find out what blog platform you are working with?
I’m having some small security issues with my latest website and I’d like to find something more risk-free.
Do you have any recommendations?
b29
Kampus Unggul
VPS SERVER
Высокоскоростной доступ в Интернет: до 1000 Мбит/с
Скорость подключения к Интернету — еще один важный фактор для успеха вашего проекта. Наши VPS/VDS-серверы, адаптированные как под Windows, так и под Linux, обеспечивают доступ в Интернет со скоростью до 1000 Мбит/с, что гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
kantorbola88
Kantorbola situs slot online terbaik 2023 , segera daftar di situs kantor bola dan dapatkan promo terbaik bonus deposit harian 100 ribu , bonus rollingan 1% dan bonus cashback mingguan . Kunjungi juga link alternatif kami di kantorbola77 , kantorbola88 dan kantorbola99
Nicely put, Thanks!
fish catching game reddog casino online bitcoin blackjack
Many thanks, Numerous information!
highest rtp casino slot machines 2023 https://red-dogcasino.online/ reddog casino bonus codes
Cheers. A lot of information!
red dog casino free chip roulette real money free play slots no download
B52
bata4d
bata4d
Incredible tons of awesome information.
casino min deposit red casino red dog slots
You actually suggested it effectively!
red dog casino login reddog casino no deposit credit card casino
Incredible loads of wonderful tips!
does casino take credit cards https://reddog-casino.site/ free blackjack win real money
can you buy generic clomid tablets: buying clomid without dr prescription – buy generic clomid without rx
Really lots of helpful info.
red dog bonus codes red dog casino review $10 deposit casino
https://medium.com/@Guillermin89329/дешевый-vps-на-linux-с-выделенной-графикой-и-антивирусной-защитой-6816cef7d47f
VPS SERVER
Высокоскоростной доступ в Интернет: до 1000 Мбит/с
Скорость подключения к Интернету — еще один важный фактор для успеха вашего проекта. Наши VPS/VDS-серверы, адаптированные как под Windows, так и под Linux, обеспечивают доступ в Интернет со скоростью до 1000 Мбит/с, что гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
erectile dysfunction pills: erection pills that work – cheap ed pills
Valuable postings. With thanks.
casino fish game red casino online video poker for money
http://edpills.icu/# erectile dysfunction drug
Wow tons of wonderful advice.
archilies the game https://red-dogcasino.website/ play european roulette
viagra without a doctor prescription: buy prescription drugs online legally – prescription drugs online without doctor
buy generic clomid without dr prescription: can i purchase generic clomid without dr prescription – where can i get cheap clomid pill
https://mexicopharm.shop/# mexican rx online
Many thanks, Valuable information!
craps online real money reddog casino bonus codes no deposit free chip
win79
https://medium.com/@JeremyBoot89136/аренда-сервера-для-хрумера-55dde3f53ed0
VPS SERVER
Высокоскоростной доступ в Интернет: до 1000 Мбит/с
Скорость подключения к Интернету — еще один важный фактор для успеха вашего проекта. Наши VPS/VDS-серверы, адаптированные как под Windows, так и под Linux, обеспечивают доступ в Интернет со скоростью до 1000 Мбит/с, что гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
herbal ed treatment non prescription erection pills the best ed pills
Thank you, I value this!
bcgame forum https://bcgamecasino.fun/ bc game
https://tadalafil.trade/# tadalafil in india online
generic tadalafil without prescription: tadalafil – generic – tadalafil 5mg best price
https://sildenafil.win/# sildenafil 10mg tablets
You explained this perfectly!
shitcode bcgame bc nd game army vs bc game
http://www.manufacturer.vn is healthcare manufacturer of nasal rinse kit, vaginal pump gel, long time xxx solution, enhance supplement, ODM and OEM service. Manufacturer.vn can also research and development products from your ideas. We export more than 40 countries, we are one sub-company of StrongBody
sildenafil 50mg price australia sildenafil online purchase in india generic sildenafil 20 mg
You made your position quite clearly!.
best online craps red dog casino review online video poker for real money
Generic Levitra 20mg: Levitra online pharmacy – Buy Vardenafil 20mg online
win79
win79
super kamagra: п»їkamagra – buy kamagra online usa
https://edpills.monster/# best over the counter ed pills
п»їLevitra price Cheap Levitra online Levitra online USA fast
Very good forum posts, Thank you.
is bc game down bc game apk download bc game brasil
Seriously loads of fantastic info!
bcgame vip https://bc-game-casino.online/ harvard bc basketball game
Useful data. With thanks.
what is bc game bc game free spin is bc game legal in us
http://kamagra.team/# Kamagra 100mg price
Levitra generic best price: Cheap Levitra online – Buy Vardenafil 20mg online
I’m very happy to discover this web site. I want to to thank you for your time just for this
wonderful read!! I definitely savored every bit of it and i also have you saved to fav to see new information in your blog.
http://sildenafil.win/# no prescription generic sildenafil online
I’m gone to tell my little brother, that he should also
visit this weblog on regular basis to get updated from most up-to-date gossip.
Hi there colleagues, nice paragraph and fastidious urging
commented at this place, I am genuinely enjoying by these.
We are a gaggle of volunteers and starting a brand new scheme in our community.
Your site offered us with useful information to work on. You have done an impressive process and our whole group shall be
grateful to you.
I could not resist commenting. Very well written!
I was pretty pleased to uncover this web site.
I need to to thank you for your time due to this wonderful read!!
I definitely really liked every bit of it and i also
have you book-marked to see new information in your web site.
I could not resist commenting. Exceptionally well written!
Hello there! Would you mind if I share your blog with
my myspace group? There’s a lot of people that I think would really enjoy your content.
Please let me know. Many thanks
tadalafil pills 20mg tadalafil online india tadalafil 2.5 mg cost
I all the time used to study paragraph in news papers but now
as I am a user of internet therefore from now I am using
net for articles, thanks to web.
I pay a visit daily a few web sites and blogs to read posts, however this web site offers
quality based content.
Buy Levitra 20mg online: Levitra online pharmacy – Levitra tablet price
You actually stated this very well!
bc game como funciona bc hash game bc football bowl game 2018
Nicely put, Thank you.
clemson bc game bc game recharge bc video game
Great items from yօu, man. I’vetake into accout yur stuff prior tо and уou are simply extremely
fantastic. I actuаlly ⅼike what you hɑѵe acquired riցht hеre,
really ⅼike ᴡhat you’re saʏing and the waу іn ԝhich ԝhereіn you
sаy it. You make it entertaining ɑnd уou continue tо tɑke care of tօ stay it ѕensible.
I cant wait tо read far mоre from yⲟu. Thɑt iis ɑctually
ɑ wonderful web site.
My web-site; beli subscriber youtube aman
order sildenafil 50 mg: sildenafil 100mg price comparison – cheapest uk sildenafil
Thanks. Ample info!
bc game bonus https://bcgamecasino.pw/ usc bc football game
https://tadalafil.trade/# where to buy tadalafil 20mg
medications for ed cures for ed herbal ed treatment
Incredible many of fantastic advice!
bcgame com bc game sweet codes bc game
zestril lisinopril: Over the counter lisinopril – can i buy lisinopril over the counter in canada
Amazing loads of fantastic knowledge!
bc game brasil fsu bc game bc game affiliate program
amoxicillin 500mg capsule buy online: purchase amoxicillin online – medicine amoxicillin 500mg
http://ciprofloxacin.men/# buy cipro without rx
lisinopril 10 12.55mg buy lisinopril 5 mg prinivil 2.5 mg
doxycycline uk cost: buy doxycycline over the counter – doxycycline tablets canada
Truly lots of fantastic information.
clemson bc game 2023 https://bcgamecasino.website/ clemson bc game tickets
If some one wishes expert view regarding blogging and site-building then i suggest
him/her to visit this blog, Keep up the pleasant work.
You suggested that perfectly.
bc red bandana game bc .game bc rutgers game
amoxicillin 500 mg without prescription cheap amoxicillin amoxicillin 50 mg tablets
doxycycline online uk: doxycycline 50 mg buy uk – doxycycline 50mg tablets
doxycycline uk online: Buy Doxycycline for acne – doxycycline antibiotic
Heya i ɑm foг the first tіme here. I came afross this board ɑnd I find It realⅼy useful & itt helped
mе out a ⅼot. I һoe tο ɡive somethіng back and һelp ⲟthers
like you helped me.
Check ⲟut my web site; kebuntoto link alternatif
buy amoxicillin 500mg buy amoxicillin online cheap where can i get amoxicillin
buy ciprofloxacin: Ciprofloxacin online prescription – buy cipro
Thanks. An abundance of stuff.
1win vs viperio https://1winoficialnyj.online/ большой 1win казино букмекерская контора 1win промокод
Kudos. Numerous tips!
1win real or fake авиатор 1win скачать 1win куда вводить промокод
http://doxycycline.forum/# buy doxycycline 100mg canada
where to buy zithromax in canada zithromax z-pak zithromax antibiotic
ciprofloxacin mail online: ciprofloxacin without insurance – ciprofloxacin generic price
can you buy zithromax over the counter in australia: buy zithromax canada – can you buy zithromax over the counter in australia
You actually expressed this exceptionally well!
1win скачать на айфон зеркало ваучеры 1win 1win kz официальный сайт
Thanks! Numerous tips!
1вин реальный обзор 1win 1вин промокод https://1winoficialnyj.site/ лаки джет 1win официальный сайт
http://azithromycin.bar/# where can i buy zithromax medicine
doxycycline 40 mg generic cost: Buy doxycycline hyclate – buy doxycycline for dogs
Someone essentially lend a hand to make significantly posts I would state.
That is the first time I frequented your
web page and to this point? I surprised with the research you made to create
this particular post extraordinary. Excellent job!
amoxicillin 500 mg online cheap amoxicillin amoxicillin capsules 250mg
Thank you very much for sharing, I learned a lot from your article. Very cool. Thanks. nimabi
You have made some really good points there.
I looked on the web to find out more about the issue and found
most individuals will go along with your views on this site.
http://ciprofloxacin.men/# where to buy cipro online
You actually reported this wonderfully!
1win apk android ваучер 1win на сегодня 1win site
buying prescription drugs in mexico online: best online pharmacy – mexico drug stores pharmacies
b52
Regards! I value it.
как использовать бонусы казино 1win https://1winoficialnyj.website/ 1вин слоты 1win 1win промокод 2023
https://buydrugsonline.top/# legitimate online pharmacies
I blog quite often and I genuinely appreciate your information.
Your article has truly peaked my interest. I am going to bookmark your website and keep
checking for new information about once a week. I opted in for your RSS feed too.
What’s up everybody, here every one is sharing
these familiarity, thus it’s nice to read this web site, and I used
to visit this website everyday.
buy prescription drugs from india: buy prescription drugs from india – top 10 online pharmacy in india
canadian pharmacies for viagra: online pharmacy no prescription – canadian pharmacy no presciption
I wanted to thank you for this fantastic read!! I certainly enjoyed every little bit of it.
I’ve got you bookmarked to check out new stuff you post…
You definitely made the point!
бк на спорт и промокод для 1win 1win зеркало промокод 1win apk 1win lucky jet скачать
work from home jobs
http://ordermedicationonline.pro/# canadian pharmacy 24hr
Discover http://www.strongbody.uk for an exclusive selection of B2B wholesale healthcare products. Retailers can easily place orders, waiting a smooth manufacturing process. Closing the profitability gap, our robust brands, supported by healthcare media, simplify the selling process for retailers. All StrongBody products boast high quality, unique R&D, rigorous testing, and effective marketing. StrongBody is dedicated to helping you and your customers live longer, younger, and healthier lives.
cheap prescriptions: cheapest online pharmacy – online pharmacy no prescription
Truly a good deal of valuable data.
как поставить бонус в 1win 1win рабочее зеркало 1win casino review
no prior prescription needed: Mail order pharmacy – canadian prescriptions online
I’m gone to tell my little brother, that he should also go to
see this web site on regular basis to get updated from hottest news.
Amazing many of superb info!
1win букмекерская контора зеркало https://1winregistracija.online/ “””1win pthrfkj”””
Aw, tһіs was aаn exceptionally gоod post. Spending sоme
time and actual effort tο prlduce a really
good article… Ьut wһat cann Ι say… I procrastinate ɑ
whole ⅼot and never sem to get nearly anyuthing done.
Feel free to visit my blog :: manfaat pinterest untuk bisnis
canadian drugs online viagra Mail order pharmacy mail order drugs without a prescription
Transportation of Pets around the world
can i order cheap clomid prices: Clomiphene Citrate 50 Mg – order clomid no prescription
Cel mai bun site pentru lucrari de licenta si locul unde poti gasii cel mai bun redactor specializat in redactare lucrare de licenta la comanda fara plagiat
Study in Kenya work in Germany and UK
Mount Kenya University (MKU) is a Chartered MKU and ISO 9001:2015 Quality Management Systems certified University committed to offering holistic education. MKU has embraced the internationalization agenda of higher education. The University, a research institution dedicated to the generation, dissemination and preservation of knowledge; with 8 regional campuses and 6 Open, Distance and E-Learning (ODEL) Centres; is one of the most culturally diverse universities operating in East Africa and beyond. The University Main campus is located in Thika town, Kenya with other Campuses in Nairobi, Parklands, Mombasa, Nakuru, Eldoret, Meru, and Kigali, Rwanda. The University has ODeL Centres located in Malindi, Kisumu, Kitale, Kakamega, Kisii and Kericho and country offices in Kampala in Uganda, Bujumbura in Burundi, Hargeisa in Somaliland and Garowe in Puntland.
MKU is a progressive, ground-breaking university that serves the needs of aspiring students and a devoted top-tier faculty who share a commitment to the promise of accessible education and the imperative of social justice and civic engagement-doing good and giving back. The University’s coupling of health sciences, liberal arts and research actualizes opportunities for personal enrichment, professional preparedness and scholarly advancement
Sun52
Sun52
Thank you! Good information!
1win 2023 зарегистрироваться 1win 1win обзор
https://gabapentin.life/# neurontin cap 300mg price
how to get neurontin: canada where to buy neurontin – neurontin 1800 mg
You actually stated that terrifically.
бонус по free spins 1win как использовать https://1winvhod.online/ 1win промокод россия
slot gacor minimal deposit 5rb
https://paxlovid.club/# п»їpaxlovid
slot gacor gampang menang fe412cb
Slot Gacor telah menciptakan fenomena baru dalam dunia slot online, tidak sekadar menjadi istilah biasa, melainkan sebuah jaminan meraih kemenangan dengan menawarkan pengalaman permainan slot yang memikat dengan minimal deposit 5rb.
Bermain di situs slot gacor yang dapat dijamin amanah bukan hanya memberikan hiburan semata, tetapi juga membuka peluang meraih jackpot terbesar yang sebelumnya mungkin sulit dicapai atau bahkan tidak pernah terwujud.
Pengalaman Game Slot Gacor: Lebih Dari Sekadar Hiburan
Slot Gacor bukanlah sekadar permainan slot biasa. Ia menciptakan atmosfer yang berbeda, memanjakan pemain dengan sensasi bermain yang luar biasa dan menawarkan harapan kemenangan yang lebih tinggi. Dengan desain yang menarik dan fitur-fitur inovatif, setiap putaran menjadi pengalaman yang tak terlupakan.
Strategi Bermain untuk Meningkatkan Peluang Kemenangan
Meskipun slot gacor dikenal dapat meningkatkan peluang kemenangan, penting bagi pemain memiliki beberapa strategi untuk memaksimalkan potensi kemenangan mereka. Beberapa strategi yang dapat diadopsi antara lain:
1. Pemilihan Provider Game yang Tepat
Pemilihan provider game slot online yang tepat menjadi langkah awal yang krusial. Pastikan memilih provider yang memiliki reputasi baik dan menawarkan variasi game slot gacor terbaik.
2. Pahami Return to Player (RTP) Tertinggi
Mengetahui tingkat Return to Player (RTP) tertinggi pada setiap permainan slot dapat menjadi kunci kesuksesan. Pilihlah game dengan RTP tinggi untuk meningkatkan peluang meraih kemenangan.
Slot Gacor Malam Ini: Temukan Keberuntungan Anda
Setiap malam, dunia slot gacor menyajikan kejutan-kejutan baru. Untuk menjadi bagian dari aksi malam ini, pastikan untuk mengikuti bocoran pola slot gacor yang telah disiapkan. Ini dapat menjadi kunci untuk membuka pintu ke sesuatu yang lebih besar dan meraih kemenangan yang menarik.
Jadi, jangan ragu untuk bergabung dan bermain di slot gacor hari ini. Saksikan sendiri bagaimana pengalaman bermain dapat menjadi lebih dari sekadar hiburan, melainkan sebuah peluang untuk meraih kemenangan besar. Selamat bermain dan semoga keberuntungan selalu berada di pihak Anda!
Hi mates, how is all, and what you desire to say concerning this piece of writing, in my
view its really amazing designed for me.
https://www.philadelphia.edu.jo/library/directors-message-library
You actually stated this perfectly.
1win букмекерская 1win официальный бк 1win 1win официальное зеркало
neurontin 500 mg tablet: cheap gabapentin – how much is neurontin pills
Truly plenty of beneficial facts!
как использовать бонус на спорт в 1win официальный сайт конторы 1win bonus casino 1win
https://gabapentin.life/# generic gabapentin
kantorbola
Kantorbola adalah situs slot gacor terbaik di indonesia , kunjungi situs RTP kantor bola untuk mendapatkan informasi akurat slot dengan rtp diatas 95% . Kunjungi juga link alternatif kami di kantorbola77 dan kantorbola99
paxlovid india http://paxlovid.club/# paxlovid for sale
Jago Slot
Jagoslot adalah situs slot gacor terlengkap, terbesar & terpercaya yang menjadi situs slot online paling gacor di indonesia. Jago slot menyediakan semua permaina slot gacor dan judi online mudah menang seperti slot online, live casino, judi bola, togel online, tembak ikan, sabung ayam, arcade dll.
generic clomid tablets: Buy Clomid Online – how to buy clomid for sale
Nicely put. Regards.
актуальное зеркало бк 1win 1win казино 1win es seguro
Thank you! I enjoy this!
1win ci bonus casino 1win 1win бонус за установку приложения
Excellent Blog! I would like to thank for the efforts you have made in writing this post. I am hoping the same best work from you in the future as well. I wanted to thank you for this websites! Thanks for sharing. Great websites!
https://gabapentin.life/# neurontin generic
wellbutrin xl 150: Buy Wellbutrin XL 300 mg online – wellbutrin generic online
Sun52
You definitely made your point.
1win скачать на андроид бесплатно 1win онлайн 1win на спорт
http://claritin.icu/# no prescription ventolin hfa
You have made your stand quite nicely!.
бк 1win скачать на андроид 1win bet 1win как ставить бонусы
Al-Ahliyya Amman University
AAU Started providing academic services in 1990, Al-Ahliyya Amman University (AAU) was the first private university and pioneer of private education in Jordan. AAU has been accorded institutional and programmatic accreditation. It is a member of the International Association of Universities, Federation of the Universities of the Islamic World, Union of Arab Universities and Association of Arab Private Institutions of Higher Education. AAU always seeks distinction by upgrading learning outcomes through the adoption of methods and strategies that depend on a system of quality control and effective follow-up at all its faculties, departments, centers and administrative units. The overall aim is to become a flagship university not only at the Hashemite Kingdom of Jordan level but also at the Arab World level. In this vein, AAU has adopted Information Technology as an essential ingredient in its activities, especially e-learning, and it has incorporated it in its educational processes in all fields of specialization to become the first such university to do so.
https://www.ammanu.edu.jo/
b52
can you buy ventolin over the counter in uk: buy Ventolin inhaler – ventolin for sale uk
Thank you very much for sharing, I learned a lot from your article. Very cool. Thanks. nimabi
https://clomid.club/# where can i buy cheap clomid no prescription
ветеринарный паспорт международного образца
Kudos, I appreciate this.
“””1win скачать на android””” 1win app store 1win официальный сайт вход
Kudos, Lots of write ups.
1win code promo 1win casino как пополнить баланс на 1win
farmacie online autorizzate elenco: kamagra gold – migliori farmacie online 2023
http://sildenafilit.bid/# viagra generico sandoz
b52 club
Tiêu đề: “B52 Club – Trải nghiệm Game Đánh Bài Trực Tuyến Tuyệt Vời”
B52 Club là một cổng game phổ biến trong cộng đồng trực tuyến, đưa người chơi vào thế giới hấp dẫn với nhiều yếu tố quan trọng đã giúp trò chơi trở nên nổi tiếng và thu hút đông đảo người tham gia.
1. Bảo mật và An toàn
B52 Club đặt sự bảo mật và an toàn lên hàng đầu. Trang web đảm bảo bảo vệ thông tin người dùng, tiền tệ và dữ liệu cá nhân bằng cách sử dụng biện pháp bảo mật mạnh mẽ. Chứng chỉ SSL đảm bảo việc mã hóa thông tin, cùng với việc được cấp phép bởi các tổ chức uy tín, tạo nên một môi trường chơi game đáng tin cậy.
2. Đa dạng về Trò chơi
B52 Play nổi tiếng với sự đa dạng trong danh mục trò chơi. Người chơi có thể thưởng thức nhiều trò chơi đánh bài phổ biến như baccarat, blackjack, poker, và nhiều trò chơi đánh bài cá nhân khác. Điều này tạo ra sự đa dạng và hứng thú cho mọi người chơi.
3. Hỗ trợ Khách hàng Chuyên Nghiệp
B52 Club tự hào với đội ngũ hỗ trợ khách hàng chuyên nghiệp, tận tâm và hiệu quả. Người chơi có thể liên hệ thông qua các kênh như chat trực tuyến, email, điện thoại, hoặc mạng xã hội. Vấn đề kỹ thuật, tài khoản hay bất kỳ thắc mắc nào đều được giải quyết nhanh chóng.
4. Phương Thức Thanh Toán An Toàn
B52 Club cung cấp nhiều phương thức thanh toán để đảm bảo người chơi có thể dễ dàng nạp và rút tiền một cách an toàn và thuận tiện. Quy trình thanh toán được thiết kế để mang lại trải nghiệm đơn giản và hiệu quả cho người chơi.
5. Chính Sách Thưởng và Ưu Đãi Hấp Dẫn
Khi đánh giá một cổng game B52, chính sách thưởng và ưu đãi luôn được chú ý. B52 Club không chỉ mang đến những chính sách thưởng hấp dẫn mà còn cam kết đối xử công bằng và minh bạch đối với người chơi. Điều này giúp thu hút và giữ chân người chơi trên thương trường game đánh bài trực tuyến.
Hướng Dẫn Tải và Cài Đặt
Để tham gia vào B52 Club, người chơi có thể tải file APK cho hệ điều hành Android hoặc iOS theo hướng dẫn chi tiết trên trang web. Quy trình đơn giản và thuận tiện giúp người chơi nhanh chóng trải nghiệm trò chơi.
Với những ưu điểm vượt trội như vậy, B52 Club không chỉ là nơi giải trí tuyệt vời mà còn là điểm đến lý tưởng cho những người yêu thích thách thức và may mắn.
migliori farmacie online 2023: kamagra gel prezzo – farmacie online sicure
farmacie online autorizzate elenco farmacia online acquistare farmaci senza ricetta
farmacia online migliore: cialis generico – comprare farmaci online con ricetta
Tips effectively regarded!!
1win скачать приложение официального сайта бонусы казино 1win 1win история ставок
Pretty nice post. I just stumbled սpon yoᥙr blog
andd wanred tto say tһat Ι have really enjoyed surfing around yоur boog
posts. After ɑll I ԝill be subscribing tоo your feed
and I hope ʏou write aցain soon!
my blog post :: beli backlink berkualitas
п»їfarmacia online migliore: Avanafil farmaco – acquisto farmaci con ricetta
farmacia online più conveniente: farmacia online più conveniente – farmacie online affidabili
b52 club
Amazing loads of awesome knowledge.
1win как пользоваться бонусами 1win казино реальный бонусы 1win 2024 казино промокод 1win на сегодня
farmacia online senza ricetta: farmacia online spedizione gratuita – farmacia online
http://tadalafilit.store/# farmacia online migliore
farmacia online migliore: kamagra – farmaci senza ricetta elenco
Woah! I’m really digging the template/theme of this website.
It’s simple, yet effective. A lot of times it’s difficult to
get that “perfect balance” between usability and appearance.
I must say that you’ve done a very good job with this. In addition, the blog loads super fast for me on Opera.
Outstanding Blog!
acquisto farmaci con ricetta Tadalafil generico farmacie online autorizzate elenco
farmacia online migliore: farmacia online spedizione gratuita – farmacia online senza ricetta
What’s up mates, its fantastic post regarding cultureand fully explained, keep it up all the time.
comprare farmaci online con ricetta: avanafil prezzo in farmacia – top farmacia online
slot gacor gampang menang
In recent years, the landscape of digital entertainment and online gaming has expanded, with ‘nhà cái’ (betting houses or bookmakers) becoming a significant part. Among these, ‘nhà cái RG’ has emerged as a notable player. It’s essential to understand what these entities are and how they operate in the modern digital world.
A ‘nhà cái’ essentially refers to an organization or an online platform that offers betting services. These can range from sports betting to other forms of wagering. The growth of internet connectivity and mobile technology has made these services more accessible than ever before.
Among the myriad of options, ‘nhà cái RG’ has been mentioned frequently. It appears to be one of the numerous online betting platforms. The ‘RG’ could be an abbreviation or a part of the brand’s name. As with any online betting platform, it’s crucial for users to understand the terms, conditions, and the legalities involved in their country or region.
The phrase ‘RG nhà cái’ could be interpreted as emphasizing the specific brand ‘RG’ within the broader category of bookmakers. This kind of focus suggests a discussion or analysis specific to that brand, possibly about its services, user experience, or its standing in the market.
Finally, ‘Nhà cái Uy tín’ is a term that people often look for. ‘Uy tín’ translates to ‘reputable’ or ‘trustworthy.’ In the context of online betting, it’s a crucial aspect. Users typically seek platforms that are reliable, have transparent operations, and offer fair play. Trustworthiness also encompasses aspects like customer service, the security of transactions, and the protection of user data.
In conclusion, understanding the dynamics of ‘nhà cái,’ such as ‘nhà cái RG,’ and the importance of ‘Uy tín’ is vital for anyone interested in or participating in online betting. It’s a world that offers entertainment and opportunities but also requires a high level of awareness and responsibility.
comprare farmaci online con ricetta: Cialis senza ricetta – farmacia online miglior prezzo
migliori farmacie online 2023: kamagra gel – comprare farmaci online all’estero
Tiêu đề: “B52 Club – Trải nghiệm Game Đánh Bài Trực Tuyến Tuyệt Vời”
B52 Club là một cổng game phổ biến trong cộng đồng trực tuyến, đưa người chơi vào thế giới hấp dẫn với nhiều yếu tố quan trọng đã giúp trò chơi trở nên nổi tiếng và thu hút đông đảo người tham gia.
1. Bảo mật và An toàn
B52 Club đặt sự bảo mật và an toàn lên hàng đầu. Trang web đảm bảo bảo vệ thông tin người dùng, tiền tệ và dữ liệu cá nhân bằng cách sử dụng biện pháp bảo mật mạnh mẽ. Chứng chỉ SSL đảm bảo việc mã hóa thông tin, cùng với việc được cấp phép bởi các tổ chức uy tín, tạo nên một môi trường chơi game đáng tin cậy.
2. Đa dạng về Trò chơi
B52 Play nổi tiếng với sự đa dạng trong danh mục trò chơi. Người chơi có thể thưởng thức nhiều trò chơi đánh bài phổ biến như baccarat, blackjack, poker, và nhiều trò chơi đánh bài cá nhân khác. Điều này tạo ra sự đa dạng và hứng thú cho mọi người chơi.
3. Hỗ trợ Khách hàng Chuyên Nghiệp
B52 Club tự hào với đội ngũ hỗ trợ khách hàng chuyên nghiệp, tận tâm và hiệu quả. Người chơi có thể liên hệ thông qua các kênh như chat trực tuyến, email, điện thoại, hoặc mạng xã hội. Vấn đề kỹ thuật, tài khoản hay bất kỳ thắc mắc nào đều được giải quyết nhanh chóng.
4. Phương Thức Thanh Toán An Toàn
B52 Club cung cấp nhiều phương thức thanh toán để đảm bảo người chơi có thể dễ dàng nạp và rút tiền một cách an toàn và thuận tiện. Quy trình thanh toán được thiết kế để mang lại trải nghiệm đơn giản và hiệu quả cho người chơi.
5. Chính Sách Thưởng và Ưu Đãi Hấp Dẫn
Khi đánh giá một cổng game B52, chính sách thưởng và ưu đãi luôn được chú ý. B52 Club không chỉ mang đến những chính sách thưởng hấp dẫn mà còn cam kết đối xử công bằng và minh bạch đối với người chơi. Điều này giúp thu hút và giữ chân người chơi trên thương trường game đánh bài trực tuyến.
Hướng Dẫn Tải và Cài Đặt
Để tham gia vào B52 Club, người chơi có thể tải file APK cho hệ điều hành Android hoặc iOS theo hướng dẫn chi tiết trên trang web. Quy trình đơn giản và thuận tiện giúp người chơi nhanh chóng trải nghiệm trò chơi.
Với những ưu điểm vượt trội như vậy, B52 Club không chỉ là nơi giải trí tuyệt vời mà còn là điểm đến lý tưởng cho những người yêu thích thách thức và may mắn.
farmacia online migliore: farmacia online spedizione gratuita – farmacie online affidabili
http://sildenafilit.bid/# viagra ordine telefonico
When some one searches for his necessary thing, so he/she wishes to be available that
in detail, so that thing is maintained over here.
This is really fascinating, You are a very
professional blogger. I’ve joined your rss feed and look forward to
in quest of extra of your wonderful post. Additionally, I have shared your web site in my
social networks
acquistare farmaci senza ricetta: kamagra oral jelly – farmacia online migliore
farmacia online farmacia online miglior prezzo farmacie on line spedizione gratuita
farmacie online autorizzate elenco: farmacia online – farmacie online autorizzate elenco
esiste il viagra generico in farmacia: sildenafil 100mg prezzo – cialis farmacia senza ricetta
farmacia online miglior prezzo: avanafil prezzo in farmacia – farmacia online senza ricetta
farmacia online: avanafil generico prezzo – farmacia online senza ricetta
farmacia online: cialis generico – farmacia online senza ricetta
https://kamagrait.club/# farmacie online sicure
acquistare farmaci senza ricetta: avanafil spedra – comprare farmaci online con ricetta
farmacie online affidabili avanafil prezzo in farmacia migliori farmacie online 2023
viagra ordine telefonico: viagra prezzo – miglior sito dove acquistare viagra
please check streameast
please check ibomma
farmacia online senza ricetta: kamagra gold – farmacia online miglior prezzo
RG nhà cái
In recent years, the landscape of digital entertainment and online gaming has expanded, with ‘nhà cái’ (betting houses or bookmakers) becoming a significant part. Among these, ‘nhà cái RG’ has emerged as a notable player. It’s essential to understand what these entities are and how they operate in the modern digital world.
A ‘nhà cái’ essentially refers to an organization or an online platform that offers betting services. These can range from sports betting to other forms of wagering. The growth of internet connectivity and mobile technology has made these services more accessible than ever before.
Among the myriad of options, ‘nhà cái RG’ has been mentioned frequently. It appears to be one of the numerous online betting platforms. The ‘RG’ could be an abbreviation or a part of the brand’s name. As with any online betting platform, it’s crucial for users to understand the terms, conditions, and the legalities involved in their country or region.
The phrase ‘RG nhà cái’ could be interpreted as emphasizing the specific brand ‘RG’ within the broader category of bookmakers. This kind of focus suggests a discussion or analysis specific to that brand, possibly about its services, user experience, or its standing in the market.
Finally, ‘Nhà cái Uy tín’ is a term that people often look for. ‘Uy tín’ translates to ‘reputable’ or ‘trustworthy.’ In the context of online betting, it’s a crucial aspect. Users typically seek platforms that are reliable, have transparent operations, and offer fair play. Trustworthiness also encompasses aspects like customer service, the security of transactions, and the protection of user data.
In conclusion, understanding the dynamics of ‘nhà cái,’ such as ‘nhà cái RG,’ and the importance of ‘Uy tín’ is vital for anyone interested in or participating in online betting. It’s a world that offers entertainment and opportunities but also requires a high level of awareness and responsibility.
comprare farmaci online con ricetta: farmacia online – farmacia online più conveniente
farmaci senza ricetta elenco: kamagra gel – farmacia online migliore
farmacia online miglior prezzo farmacia online spedizione gratuita comprare farmaci online all’estero
https://tadalafilit.store/# farmaci senza ricetta elenco
acquistare farmaci senza ricetta: avanafil generico prezzo – top farmacia online
c88 login
C88: Elevate Your Gaming Experience with Unrivaled Bonuses and Endless Excitement!
Introduction:
Embark on an extraordinary gaming adventure with C88, a platform that redefines the boundaries of entertainment. Whether you’re a seasoned gamer or a newcomer, C88 promises an immersive experience characterized by thrilling features and exclusive bonuses. Let’s unravel the key elements that position C88 as the ultimate destination for gaming enthusiasts.
1. C88 Fun – Where Entertainment Knows No Bounds!
More than just a gaming platform, C88 Fun is an expedition waiting to be discovered. Boasting an intuitive interface and a diverse range of games, C88 Fun caters to all preferences. From timeless classics to cutting-edge releases, C88 Fun ensures every player finds their gaming sanctuary.
2. JILI & Evo 100% Welcome Bonus – A Warm Welcome for Newcomers!
Embark on your gaming journey with a warm embrace from C88. New members are welcomed with a 100% Welcome Bonus from JILI & Evo, doubling the excitement right from the start. This bonus acts as a catalyst for players to delve into the diverse array of games available on the platform.
3. C88 First Deposit Get 2X Bonus – Doubling the Excitement!
C88 believes in generously rewarding players. With the “First Deposit Get 2X Bonus” offer, players can revel in double the fun on their initial deposit. This promotion enriches the gaming experience, providing more avenues to win big across various games.
4. 20 Spin Times = Get Big Bonus (8,888P) – Spin Your Way to Greatness!
Spin your way to substantial bonuses with the “20 Spin Times” promotion. Accumulate spins and stand a chance to win an impressive bonus of 8,888P. This promotion adds an extra layer of excitement to the gameplay, combining luck and strategy for maximum enjoyment.
5. Daily Check-in = Turnover 5X?! – Daily Rewards Await!
Consistency is key at C88. By simply logging in daily, players not only bask in the thrill of gaming but also stand a chance to multiply their turnovers by 5X. Daily check-ins bring additional perks, making every day a rewarding experience for dedicated players.
6. 7 Day Deposit 300 = Get 1,500P – Unlock Deposit Rewards!
For those craving opportunities, the “7 Day Deposit” promotion is a game-changer. Deposit 300 and receive a generous reward of 1,500P. This promotion encourages players to explore the platform further and maximize their gaming potential.
7. Invite 100 Users = Get 10,000 PESO – Share the Excitement!
C88 believes in the strength of community. Invite friends and fellow gamers to join the excitement, and for every 100 users, receive an incredible reward of 10,000 PESO. Sharing the joy of gaming has never been more rewarding.
8. C88 New Member Get 100% First Deposit Bonus – Exclusive Benefits!
New members are in for a treat with an exclusive 100% First Deposit Bonus. C88 ensures that everyone kicks off their gaming journey with a boost, setting the stage for an exhilarating experience filled with opportunities to win.
9. All Pass Get C88 Extra Big Bonus 1000 PESO – Unlock Unlimited Rewards!
For avid players exploring every nook and cranny of C88, the “All Pass Get C88 Extra Big Bonus” offers an additional 1000 PESO. This promotion rewards those who embrace the full spectrum of games and features available on the platform.
Ready to immerse yourself in the excitement? Visit C88 now and unlock a world of gaming like never before. Don’t miss out on the excitement, bonuses, and wins that await you at C88. Join the community today and let the games begin! #c88 #c88login #c88bet #c88bonus #c88win
farmacie online sicure: farmacia online spedizione gratuita – acquistare farmaci senza ricetta
farmacia online Avanafil farmaco farmacie online autorizzate elenco
comprare farmaci online con ricetta: dove acquistare cialis online sicuro – farmaci senza ricetta elenco
https://kamagrait.club/# farmacie on line spedizione gratuita
farmaci senza ricetta elenco: avanafil spedra – farmacia online
c88 bet
1. C88 Fun – Boundless Entertainment Awaits!
C88 Fun is more than a gaming platform; it’s an expedition waiting to be embraced. Featuring an intuitive interface and a diverse array of games, C88 Fun caters to all tastes. From timeless classics to cutting-edge releases, C88 Fun ensures every player discovers their gaming haven.
2. JILI & Evo 100% Welcome Bonus – A Grand Welcome Awaits Newcomers!
Embark on your gaming journey with a grand welcome from C88. New members are greeted with a 100% Welcome Bonus from JILI & Evo, doubling the excitement right from the beginning. This bonus acts as a catalyst for players to explore the diverse array of games available on the platform.
3. C88 First Deposit Get 2X Bonus – Double the Excitement!
At C88, generosity towards players is a fundamental principle. With the “First Deposit Get 2X Bonus” offer, players can revel in double the fun on their initial deposit. This promotion enhances the gaming experience, providing more avenues to win big across various games.
4. 20 Spin Times = Get Big Bonus (8,888P) – Spin Your Way to Greatness!
Spin your way to substantial bonuses with the “20 Spin Times” promotion. Accumulate spins and stand a chance to win an impressive bonus of 8,888P. This promotion adds an extra layer of excitement to the gameplay, combining luck and strategy for maximum enjoyment.
5. Daily Check-in = Turnover 5X?! – Daily Rewards Await!
Consistency is paramount at C88. By simply logging in daily, players not only bask in the thrill of gaming but also stand a chance to multiply their turnovers by 5X. Daily check-ins bring additional perks, making every day a rewarding experience for dedicated players.
6. 7 Day Deposit 300 = Get 1,500P – Unlock Deposit Rewards!
For those eager to seize opportunities, the “7 Day Deposit” promotion is a game-changer. Deposit 300 and receive a generous reward of 1,500P. This promotion encourages players to explore the platform further and maximize their gaming potential.
7. Invite 100 Users = Get 10,000 PESO – Share the Excitement!
C88 believes in the strength of community. Invite friends and fellow gamers to join the excitement, and for every 100 users, receive an incredible reward of 10,000 PESO. Sharing the joy of gaming has never been more rewarding.
8. C88 New Member Get 100% First Deposit Bonus – Exclusive Benefits!
New members are in for a treat with an exclusive 100% First Deposit Bonus. C88 ensures that everyone kicks off their gaming journey with a boost, setting the stage for an exhilarating experience filled with opportunities to win.
9. All Pass Get C88 Extra Big Bonus 1000 PESO – Unlock Unlimited Rewards!
For avid players exploring every nook and cranny of C88, the “All Pass Get C88 Extra Big Bonus” offers an additional 1000 PESO. This promotion rewards those who embrace the full spectrum of games and features available on the platform.
Ready to immerse yourself in the excitement? Visit C88 now and unlock a world of gaming like never before. Don’t miss out on the excitement, bonuses, and wins that await you at C88. Join the community today, and let the games begin! #c88 #c88login #c88bet #c88bonus #c88win
http://vardenafilo.icu/# farmacia online envÃo gratis
https://vardenafilo.icu/# farmacia 24h
https://vardenafilo.icu/# farmacias online baratas
http://tadalafilo.pro/# farmacias baratas online envÃo gratis
farmacia online 24 horas: farmacia online envio gratis valencia – farmacias baratas online envГo gratis
https://farmacia.best/# farmacias online baratas
sildenafilo 50 mg precio sin receta comprar viagra en espana viagra para hombre precio farmacias
https://vardenafilo.icu/# farmacia online barata
http://tadalafilo.pro/# п»їfarmacia online
http://sildenafilo.store/# viagra online cerca de toledo
http://tadalafilo.pro/# farmacia online internacional
farmacias online seguras: comprar kamagra – farmacia online madrid
https://sildenafilo.store/# se puede comprar sildenafil sin receta
http://farmacia.best/# farmacia online barata
farmacia online barata Levitra 20 mg precio farmacia online envГo gratis
http://kamagraes.site/# farmacia online 24 horas
https://kamagraes.site/# farmacia online barata
C88: Where Gaming Dreams Come True – Explore Unmatched Bonuses and Unleash the Fun!
Introduction:
Embark on a thrilling gaming escapade with C88, your passport to a world where excitement meets unprecedented rewards. Designed for both gaming aficionados and novices, C88 guarantees an immersive journey filled with captivating features and exclusive bonuses. Let’s unravel the essence that makes C88 the quintessential destination for gaming enthusiasts.
1. C88 Fun – Your Gateway to Infinite Entertainment!
C88 Fun is not just a gaming platform; it’s a playground of possibilities waiting to be discovered. With its user-friendly interface and a diverse range of games, C88 Fun caters to all tastes. From classic favorites to cutting-edge releases, C88 Fun ensures every player finds their gaming sanctuary.
2. JILI & Evo 100% Welcome Bonus – A Grand Introduction to Gaming!
Embark on your gaming voyage with a grand welcome from C88. New members are embraced with a 100% Welcome Bonus from JILI & Evo, doubling the thrill right from the start. This bonus serves as a launching pad for players to explore the plethora of games available on the platform.
3. C88 First Deposit Get 2X Bonus – Double the Excitement!
Generosity is a hallmark at C88. With the “First Deposit Get 2X Bonus” offer, players can revel in double the fun on their initial deposit. This promotion enriches the gaming experience, providing more avenues to win big across various games.
4. 20 Spin Times = Get Big Bonus (8,888P) – Spin Your Way to Glory!
Spin your way to substantial bonuses with the “20 Spin Times” promotion. Accumulate spins and stand a chance to win an impressive bonus of 8,888P. This promotion adds an extra layer of excitement to the gameplay, combining luck and strategy for maximum enjoyment.
5. Daily Check-in = Turnover 5X?! – Daily Rewards Await!
Consistency reigns supreme at C88. By simply logging in daily, players not only soak in the thrill of gaming but also stand a chance to multiply their turnovers by 5X. Daily check-ins bring additional perks, making every day a rewarding experience for dedicated players.
6. 7 Day Deposit 300 = Get 1,500P – Unlock Deposit Rewards!
For those hungry for opportunities, the “7 Day Deposit” promotion is a game-changer. Deposit 300 and receive a generous reward of 1,500P. This promotion encourages players to explore the platform further and maximize their gaming potential.
7. Invite 100 Users = Get 10,000 PESO – Spread the Excitement!
C88 believes in the strength of community. Invite friends and fellow gamers to join the excitement, and for every 100 users, receive an incredible reward of 10,000 PESO. Sharing the joy of gaming has never been more rewarding.
8. C88 New Member Get 100% First Deposit Bonus – Exclusive Benefits!
New members are in for a treat with an exclusive 100% First Deposit Bonus. C88 ensures that everyone kicks off their gaming journey with a boost, setting the stage for an exhilarating experience filled with opportunities to win.
9. All Pass Get C88 Extra Big Bonus 1000 PESO – Unlock Unlimited Rewards!
For avid players exploring every nook and cranny of C88, the “All Pass Get C88 Extra Big Bonus” offers an additional 1000 PESO. This promotion rewards those who embrace the full spectrum of games and features available on the platform.
Ready to immerse yourself in the excitement? Visit C88 now and unlock a world of gaming like never before. Don’t miss out on the excitement, bonuses, and wins that await you at C88. Join the community today, and let the games begin! #c88 #c88login #c88bet #c88bonus #c88win
tombak118
farmacia online internacional: cialis 20 mg precio farmacia – farmacias online seguras en espaГ±a
nha cai RG
In recent years, the landscape of digital entertainment and online gaming has expanded, with ‘nha cai’ (betting houses or bookmakers) becoming a significant part. Among these, ‘nha cai RG’ has emerged as a notable player. It’s essential to understand what these entities are and how they operate in the modern digital world.
A ‘nha cai’ essentially refers to an organization or an online platform that offers betting services. These can range from sports betting to other forms of wagering. The growth of internet connectivity and mobile technology has made these services more accessible than ever before.
Among the myriad of options, ‘nha cai RG’ has been mentioned frequently. It appears to be one of the numerous online betting platforms. The ‘RG’ could be an abbreviation or a part of the brand’s name. As with any online betting platform, it’s crucial for users to understand the terms, conditions, and the legalities involved in their country or region.
The phrase ‘RG nha cai’ could be interpreted as emphasizing the specific brand ‘RG’ within the broader category of bookmakers. This kind of focus suggests a discussion or analysis specific to that brand, possibly about its services, user experience, or its standing in the market.
Finally, ‘Nha cai Uy tin’ is a term that people often look for. ‘Uy tin’ translates to ‘reputable’ or ‘trustworthy.’ In the context of online betting, it’s a crucial aspect. Users typically seek platforms that are reliable, have transparent operations, and offer fair play. Trustworthiness also encompasses aspects like customer service, the security of transactions, and the protection of user data.
In conclusion, understanding the dynamics of ‘nha cai,’ such as ‘nha cai RG,’ and the importance of ‘Uy tin’ is vital for anyone interested in or participating in online betting. It’s a world that offers entertainment and opportunities but also requires a high level of awareness and responsibility.
https://farmacia.best/# farmacia online madrid
farmacias online baratas Levitra 20 mg precio farmacia online envГo gratis
https://kamagraes.site/# farmacias online seguras en españa
https://vardenafilo.icu/# farmacias online seguras en espaГ±a
http://sildenafilo.store/# viagra 100 mg precio en farmacias
farmacia online 24 horas: Levitra 20 mg precio – farmacia envГos internacionales
http://sildenafilo.store/# sildenafilo sandoz 100 mg precio
http://kamagraes.site/# farmacia online
http://farmacia.best/# farmacias online seguras en españa
http://kamagraes.site/# farmacia online envГo gratis
http://vardenafilo.icu/# farmacia online internacional
http://sildenafilo.store/# sildenafilo cinfa sin receta
You should be a part of a contest for one of the best websites on the web.
I am going to highly recommend this blog!
cartier replica
http://tadalafilo.pro/# farmacias baratas online envÃo gratis
https://kamagraes.site/# farmacia online madrid
https://farmacia.best/# farmacia online internacional
http://farmacia.best/# farmacia online 24 horas
farmacias online seguras en espaГ±a: п»їfarmacia online – farmacia 24h
https://vardenafilo.icu/# farmacia online 24 horas
Simply desire to say your article is as astonishing. The clearness in your post is
just nice and i could assume you’re an expert on this subject.
Well with your permission allow me to grab your feed to keep updated with
forthcoming post. Thanks a million and please continue the
gratifying work.
http://tadalafilo.pro/# farmacia online barata
http://tadalafilo.pro/# farmacia envÃos internacionales
http://tadalafilo.pro/# farmacias online seguras
farmacia online 24 horas kamagra jelly farmacias online seguras
https://kamagraes.site/# farmacia online internacional
I truly like you’re composing style, incredible data, thankyou for posting.
https://vardenafilo.icu/# farmacias online seguras en españa
farmacia online madrid Levitra precio farmacia barata
You really make it appear really easy along with your presentation however I
to find this matter to be actually something that I think I would by no means understand.
It sort of feels too complex and very wide
for me. I am having a look forward to your next
post, I’ll try to get the cling of it!
http://kamagraes.site/# farmacia online
п»їfarmacia online: cialis 20 mg precio farmacia – farmacia barata
Porn videos
https://sildenafilo.store/# venta de viagra a domicilio
http://vardenafilo.icu/# farmacia online
https://kamagraes.site/# farmacia online 24 horas
http://farmacia.best/# farmacias online seguras
https://kamagraes.site/# farmacias baratas online envÃo gratis
viagra para hombre precio farmacias similares viagra generico viagra online cerca de zaragoza
farmacias online seguras en espaГ±a: cialis en Espana sin receta contrareembolso – farmacias online seguras en espaГ±a
http://tadalafilo.pro/# farmacia online envÃo gratis
https://viagrasansordonnance.store/# Viagra en france livraison rapide
19dewa
Viagra sans ordonnance 24h suisse: Meilleur Viagra sans ordonnance 24h – Meilleur Viagra sans ordonnance 24h
https://kamagrafr.icu/# pharmacie en ligne
бриллкс
https://brillx-kazino.com
Играть онлайн бесплатно в игровые аппараты стало еще проще с нашим интуитивно понятным интерфейсом. Просто выберите свой любимый слот и погрузитесь в мир ярких красок и захватывающих приключений. Наши разнообразные бонусы и акции добавят нотку удивительности к вашей игре. К тому же, для тех, кто желает ощутить настоящий азарт, у нас есть возможность играть на деньги. Это шанс попытать удачу и ощутить адреналин, который ищет настоящий игрок.Так что не упустите свой шанс — зайдите на официальный сайт Brillx Казино прямо сейчас, и погрузитесь в захватывающий мир азартных игр вместе с нами! Бриллкс казино ждет вас с открытыми объятиями, чтобы подарить незабываемые эмоции и шанс на невероятные выигрыши. Сделайте свою игру еще ярче и удачливее — играйте на Brillx Казино!
https://kamagrafr.icu/# Pharmacie en ligne fiable
farmacia online envГo gratis: kamagra jelly – п»їfarmacia online
Pharmacie en ligne pas cher kamagra en ligne acheter medicament a l etranger sans ordonnance
http://levitrafr.life/# acheter medicament a l etranger sans ordonnance
login hoki1881
pharmacie ouverte 24/24: achat kamagra – Pharmacie en ligne livraison rapide
http://kamagrafr.icu/# Pharmacie en ligne sans ordonnance
We absolutely love your blog and find many of your
post’s to be just what I’m looking for. Do you offer guest
writers to write content available for you? I wouldn’t mind composing a post
or elaborating on many of the subjects you write about here.
Again, awesome web log!
https://pharmacieenligne.guru/# Pharmacie en ligne fiable
http://levitrafr.life/# Pharmacie en ligne France
Pharmacie en ligne livraison gratuite cialis prix Pharmacie en ligne sans ordonnance
Does your blog have a contact page? I’m having a tough time locating it but,
I’d like to shoot you an email. I’ve got some recommendations for your blog you might be interested
in hearing. Either way, great website and I look forward to seeing it improve over time.
https://viagrasansordonnance.store/# Viagra Pfizer sans ordonnance
Pharmacie en ligne livraison rapide: levitra generique sites surs – Pharmacie en ligne livraison 24h
http://cialissansordonnance.pro/# Pharmacie en ligne livraison 24h
hoki 1881
http://levitrafr.life/# Pharmacies en ligne certifiées
farmacia online internacional: farmacia online envio gratis murcia – farmacia 24h
https://viagrasansordonnance.store/# Viagra pas cher inde
https://pharmacieenligne.guru/# Acheter médicaments sans ordonnance sur internet
Pharmacie en ligne livraison 24h Levitra pharmacie en ligne pharmacie ouverte 24/24
http://kamagrafr.icu/# Pharmacie en ligne fiable
https://viagrasansordonnance.store/# Sildénafil 100mg pharmacie en ligne
acheter medicament a l etranger sans ordonnance: levitra generique sites surs – pharmacie ouverte
Thanks for one’s marvelous posting! I seriously enjoyed reading it, you will be a great author.
I will always bookmark your blog and will eventually come back someday.
I want to encourage you continue your great posts, have
a nice evening!
http://levitrafr.life/# Pharmacie en ligne livraison rapide
farmacias online baratas: farmacias online seguras en espaГ±a – farmacia 24h
http://pharmacieenligne.guru/# Pharmacie en ligne pas cher
http://pharmacieenligne.guru/# Pharmacie en ligne pas cher
http://cialissansordonnance.pro/# Pharmacie en ligne livraison gratuite
Pharmacie en ligne livraison rapide Pharmacie en ligne France Pharmacie en ligne France
http://cialiskaufen.pro/# versandapotheke
п»їonline apotheke online apotheke preisvergleich online apotheke preisvergleich
Hello I am so delighted I found your website, I really found you by mistake, while I
was researching on Digg for something else, Anyhow
I am here now and would just like to say thanks a lot for a marvelous post and a all round entertaining blog (I also love
the theme/design), I don’t have time to look over it all at the minute but
I have bookmarked it and also added in your RSS feeds, so when I have time I will be back to read much more, Please do keep up the great b.
http://apotheke.company/# versandapotheke versandkostenfrei
http://apotheke.company/# versandapotheke versandkostenfrei
19dewa daftar
Hmm it looks like your blog ate my first comment (it was extremely
long) so I guess I’ll just sum it up what I submitted and say,
I’m thoroughly enjoying your blog. I too am an aspiring blog writer but I’m still new to everything.
Do you have any recommendations for novice blog writers?
I’d really appreciate it.
http://kamagrakaufen.top/# gГјnstige online apotheke
online apotheke deutschland cialis rezeptfreie kaufen п»їonline apotheke
gГјnstige online apotheke: potenzmittel manner – online apotheke deutschland
http://kamagrakaufen.top/# versandapotheke
Hey there! I’ve been reading your web site for a long time now and finally got the
courage to go ahead and give you a shout out from Dallas Texas!
Just wanted to tell you keep up the great job!
http://apotheke.company/# gГјnstige online apotheke
versandapotheke Cialis Generika 20mg preisvergleich internet apotheke
1881hoki
https://apotheke.company/# internet apotheke
online-apotheken Potenzmittel fur Manner online apotheke preisvergleich
Great site you have got here.. It’s difficult to find excellent writing like yours nowadays.
I truly appreciate people like you! Take care!!
Hey there exceptional website! Does running a blog like this require
a lot of work? I’ve very little expertise in coding but I had been hoping to start my own blog soon.
Anyhow, if you have any ideas or techniques for new blog owners please share.
I understand this is off subject nevertheless I just had to ask.
Thanks!
https://apotheke.company/# online apotheke deutschland
You are so interesting! I do not believe I’ve read anything like that before.
So great to discover someone with some original thoughts
on this topic. Really.. thanks for starting this up. This site is one thing that’s needed on the internet,
someone with some originality!
mexico pharmacy mexican border pharmacies shipping to usa mexican online pharmacies prescription drugs
https://mexicanpharmacy.cheap/# mexican pharmaceuticals online
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me. https://www.binance.com/bg/register?ref=GJY4VW8W
It’s in reality a nice and helpful piece of info.
I’m happy that you shared this useful info with us.
Please stay us informed like this. Thank you for sharing.
pharmacies in mexico that ship to usa mexican drugstore online mexico pharmacy
pharmacies in mexico that ship to usa mexico drug stores pharmacies purple pharmacy mexico price list
mexican rx online best online pharmacies in mexico mexico pharmacies prescription drugs
buying from online mexican pharmacy mexican online pharmacies prescription drugs buying prescription drugs in mexico
I do not even know how I ended up here, but I thought this post was great.
I do not know who you are but definitely you are going to a famous blogger if you
are not already 😉 Cheers!
mexican online pharmacies prescription drugs buying from online mexican pharmacy purple pharmacy mexico price list
Spot on with this write-up, I actually think this website needs much more
attention. I’ll probably be back again to read through more, thanks for the information!
https://mexicanpharmacy.cheap/# mexican border pharmacies shipping to usa
buying prescription drugs in mexico online mexico pharmacies prescription drugs buying from online mexican pharmacy
mexican mail order pharmacies mexican border pharmacies shipping to usa mexico drug stores pharmacies
reputable mexican pharmacies online best online pharmacies in mexico buying prescription drugs in mexico
https://mexicanpharmacy.cheap/# mexican mail order pharmacies
It’s impressive that you are getting thoughts from this article
as well as from our dialogue made at this time.
п»їbest mexican online pharmacies mexican rx online mexican mail order pharmacies
best mexican online pharmacies mexico drug stores pharmacies mexican rx online
pharmacies in mexico that ship to usa mexico drug stores pharmacies pharmacies in mexico that ship to usa
https://mexicanpharmacy.cheap/# medicine in mexico pharmacies
medication from mexico pharmacy medication from mexico pharmacy mexico pharmacies prescription drugs
https://mexicanpharmacy.cheap/# mexican border pharmacies shipping to usa
Nhà Cái
mexican pharmaceuticals online mexican pharmaceuticals online mexico pharmacy
This is my first time pay a quick visit at here and i am genuinely impressed to read everthing at one place.
purple pharmacy mexico price list mexican online pharmacies prescription drugs п»їbest mexican online pharmacies
mexico drug stores pharmacies buying from online mexican pharmacy best online pharmacies in mexico
mexico pharmacy mexico pharmacies prescription drugs mexico pharmacy
http://mexicanpharmacy.cheap/# mexican rx online
mexican rx online mexico drug stores pharmacies buying prescription drugs in mexico online
http://canadapharmacy.guru/# trusted canadian pharmacy canadapharmacy.guru
buy medicines online in india top 10 pharmacies in india cheapest online pharmacy india indiapharmacy.guru
canadian pharmacy 77 canadian pharmacy – canadian compounding pharmacy canadiandrugs.tech
http://canadiandrugs.tech/# canadian medications canadiandrugs.tech
indian pharmacies safe reputable indian online pharmacy – online shopping pharmacy india indiapharmacy.guru
オンラインカジノレビュー
オンラインカジノレビュー:選択の重要性
オンラインカジノの世界への入門
オンラインカジノは、インターネット上で提供される多様な賭博ゲームを通じて、世界中のプレイヤーに無限の娯楽を提供しています。これらのプラットフォームは、スロット、テーブルゲーム、ライブディーラーゲームなど、様々なゲームオプションを提供し、実際のカジノの経験を再現します。
オンラインカジノレビューの重要性
オンラインカジノを選択する際には、オンラインカジノレビューの役割が非常に重要です。レビューは、カジノの信頼性、ゲームの多様性、顧客サービスの質、ボーナスオファー、支払い方法、出金条件など、プレイヤーが知っておくべき重要な情報を提供します。良いレビューは、利用者の実際の体験に基づいており、新規プレイヤーがカジノを選択する際の重要なガイドとなります。
レビューを読む際のポイント
信頼性とライセンス:カジノが適切なライセンスを持ち、公平なゲームプレイを提供しているかどうか。
ゲームの選択:多様なゲームオプションが提供されているかどうか。
ボーナスとプロモーション:魅力的なウェルカムボーナス、リロードボーナス、VIPプログラムがあるかどうか。
顧客サポート:サポートの応答性と有効性。
出金オプション:出金の速度と方法。
プレイヤーの体験
良いオンラインカジノレビューは、実際のプレイヤーの体験に基づいています。これには、ゲームプレイの楽しさ、カスタマーサポートへの対応、そして出金プロセスの簡単さが含まれます。プレイヤーのフィードバックは、カジノの品質を判断するのに役立ちます。
結論
オンラインカジノを選択する際には、詳細なオンラインカジノレビューを参照することが重要です。これらのレビューは、安全で楽しいギャンブル体験を確実にするための信頼できる情報源となります。適切なカジノを選ぶことは、オンラインギャンブルでの成功への第一歩です。
http://edpills.tech/# treatment for ed edpills.tech
Grup seks yapmak erkeklerin vazgeçemediği bir olgudur.
Three are usually cheap Ralph Lauren available for sale each and every time you wish to buy.
https://canadiandrugs.tech/# canadian pharmacy mall canadiandrugs.tech
canadapharmacyonline com reliable canadian pharmacy safe canadian pharmacy canadiandrugs.tech
https://canadiandrugs.tech/# canadian pharmacy oxycodone canadiandrugs.tech
buy prescription drugs from india indian pharmacy – best online pharmacy india indiapharmacy.guru
https://edpills.tech/# ed pills cheap edpills.tech
https://edpills.tech/# non prescription erection pills edpills.tech
http://indiapharmacy.guru/# top 10 pharmacies in india indiapharmacy.guru
top 10 pharmacies in india online pharmacy india – mail order pharmacy india indiapharmacy.guru
canada drugs online best canadian online pharmacy reviews the canadian drugstore canadiandrugs.tech
http://canadiandrugs.tech/# canadian neighbor pharmacy canadiandrugs.tech
It’s an remarkable piece of writing for all the internet viewers; they will take advantage
from it I am sure.
オンラインカジノとオンラインギャンブルの現代的展開
オンラインカジノの世界は、技術の進歩と共に急速に進化しています。これらのプラットフォームは、従来の実際のカジノの体験をデジタル空間に移し、プレイヤーに新しい形式の娯楽を提供しています。オンラインカジノは、スロットマシン、ポーカー、ブラックジャック、ルーレットなど、さまざまなゲームを提供しており、実際のカジノの興奮を維持しながら、アクセスの容易さと利便性を提供します。
一方で、オンラインギャンブルは、より広範な概念であり、スポーツベッティング、宝くじ、バーチャルスポーツ、そしてオンラインカジノゲームまでを含んでいます。インターネットとモバイルテクノロジーの普及により、オンラインギャンブルは世界中で大きな人気を博しています。オンラインプラットフォームは、伝統的な賭博施設に比べて、より多様なゲーム選択、便利なアクセス、そしてしばしば魅力的なボーナスやプロモーションを提供しています。
安全性と規制
オンラインカジノとオンラインギャンブルの世界では、安全性と規制が非常に重要です。多くの国々では、オンラインギャンブルを規制する法律があり、安全なプレイ環境を確保するためのライセンスシステムを設けています。これにより、不正行為や詐欺からプレイヤーを守るとともに、責任ある賭博の促進が図られています。
技術の進歩
最新のテクノロジーは、オンラインカジノとオンラインギャンブルの体験を一層豊かにしています。例えば、仮想現実(VR)技術の使用は、プレイヤーに没入型のギャンブル体験を提供し、実際のカジノにいるかのような感覚を生み出しています。また、ブロックチェーン技術の導入は、より透明で安全な取引を可能にし、プレイヤーの信頼を高めています。
未来への展望
オンラインカジノとオンラインギャンブルは、今後も技術の進歩とともに進化し続けるでしょう。人工知能(AI)の更なる統合、モバイル技術の発展、さらには新しいゲームの創造により、この分野は引き続き成長し、世界中のプレイヤーに新しい娯楽の形を提供し続けることでしょう。
この記事では、オンラインカジノとオンラインギャンブルの現状、安全性、技術の影響、そして将来の展望に焦点を当てています。この分野は、技術革新によって絶えず変化し続ける魅力的な領域です。
https://indiapharmacy.guru/# legitimate online pharmacies india indiapharmacy.guru
Tải Hit Club iOS
Tải Hit Club iOSHIT CLUBHit Club đã sáng tạo ra một giao diện game đẹp mắt và hoàn thiện, lấy cảm hứng từ các cổng casino trực tuyến chất lượng từ cổ điển đến hiện đại. Game mang lại sự cân bằng và sự kết hợp hài hòa giữa phong cách sống động của sòng bạc Las Vegas và phong cách chân thực. Tất cả các trò chơi đều được bố trí tinh tế và hấp dẫn với cách bố trí game khoa học và logic giúp cho người chơi có được trải nghiệm chơi game tốt nhất.
Hit Club – Cổng Game Đổi Thưởng
Trên trang chủ của Hit Club, người chơi dễ dàng tìm thấy các game bài, tính năng hỗ trợ và các thao tác để rút/nạp tiền cùng với cổng trò chuyện trực tiếp để được tư vấn. Giao diện game mang lại cho người chơi cảm giác chân thật và thoải mái nhất, giúp người chơi không bị mỏi mắt khi chơi trong thời gian dài.
Hướng Dẫn Tải Game Hit Club
Bạn có thể trải nghiệm Hit Club với 2 phiên bản: Hit Club APK cho thiết bị Android và Hit Club iOS cho thiết bị như iPhone, iPad.
Tải ứng dụng game:
Click nút tải ứng dụng game ở trên (phiên bản APK/Android hoặc iOS tùy theo thiết bị của bạn).
Chờ cho quá trình tải xuống hoàn tất.
Cài đặt ứng dụng:
Khi quá trình tải xuống hoàn tất, mở tệp APK hoặc iOS và cài đặt ứng dụng trên thiết bị của bạn.
Bắt đầu trải nghiệm:
Mở ứng dụng và bắt đầu trải nghiệm Hit Club.
Với Hit Club, bạn sẽ khám phá thế giới game đỉnh cao với giao diện đẹp mắt và trải nghiệm chơi game tuyệt vời. Hãy tải ngay để tham gia vào cuộc phiêu lưu casino độc đáo và đầy hứng khởi!
https://indiapharmacy.guru/# online shopping pharmacy india indiapharmacy.guru
buy canadian drugs adderall canadian pharmacy – pharmacy canadian canadiandrugs.tech
http://canadiandrugs.tech/# canada drug pharmacy canadiandrugs.tech
https://edpills.tech/# treatments for ed edpills.tech
best ed drug top rated ed pills ed drugs edpills.tech
http://indiapharmacy.guru/# top online pharmacy india indiapharmacy.guru
top 10 online pharmacy in india reputable indian online pharmacy – reputable indian online pharmacy indiapharmacy.guru
http://edpills.tech/# best ed pills online edpills.tech
https://edpills.tech/# best treatment for ed edpills.tech
tai game hitclub
Tải Hit Club iOS
Tải Hit Club iOSHIT CLUBHit Club đã sáng tạo ra một giao diện game đẹp mắt và hoàn thiện, lấy cảm hứng từ các cổng casino trực tuyến chất lượng từ cổ điển đến hiện đại. Game mang lại sự cân bằng và sự kết hợp hài hòa giữa phong cách sống động của sòng bạc Las Vegas và phong cách chân thực. Tất cả các trò chơi đều được bố trí tinh tế và hấp dẫn với cách bố trí game khoa học và logic giúp cho người chơi có được trải nghiệm chơi game tốt nhất.
Hit Club – Cổng Game Đổi Thưởng
Trên trang chủ của Hit Club, người chơi dễ dàng tìm thấy các game bài, tính năng hỗ trợ và các thao tác để rút/nạp tiền cùng với cổng trò chuyện trực tiếp để được tư vấn. Giao diện game mang lại cho người chơi cảm giác chân thật và thoải mái nhất, giúp người chơi không bị mỏi mắt khi chơi trong thời gian dài.
Hướng Dẫn Tải Game Hit Club
Bạn có thể trải nghiệm Hit Club với 2 phiên bản: Hit Club APK cho thiết bị Android và Hit Club iOS cho thiết bị như iPhone, iPad.
Tải ứng dụng game:
Click nút tải ứng dụng game ở trên (phiên bản APK/Android hoặc iOS tùy theo thiết bị của bạn).
Chờ cho quá trình tải xuống hoàn tất.
Cài đặt ứng dụng:
Khi quá trình tải xuống hoàn tất, mở tệp APK hoặc iOS và cài đặt ứng dụng trên thiết bị của bạn.
Bắt đầu trải nghiệm:
Mở ứng dụng và bắt đầu trải nghiệm Hit Club.
Với Hit Club, bạn sẽ khám phá thế giới game đỉnh cao với giao diện đẹp mắt và trải nghiệm chơi game tuyệt vời. Hãy tải ngay để tham gia vào cuộc phiêu lưu casino độc đáo và đầy hứng khởi!
http://canadiandrugs.tech/# canadian pharmacies that deliver to the us canadiandrugs.tech
hit club
Tải Hit Club iOS
Tải Hit Club iOSHIT CLUBHit Club đã sáng tạo ra một giao diện game đẹp mắt và hoàn thiện, lấy cảm hứng từ các cổng casino trực tuyến chất lượng từ cổ điển đến hiện đại. Game mang lại sự cân bằng và sự kết hợp hài hòa giữa phong cách sống động của sòng bạc Las Vegas và phong cách chân thực. Tất cả các trò chơi đều được bố trí tinh tế và hấp dẫn với cách bố trí game khoa học và logic giúp cho người chơi có được trải nghiệm chơi game tốt nhất.
Hit Club – Cổng Game Đổi Thưởng
Trên trang chủ của Hit Club, người chơi dễ dàng tìm thấy các game bài, tính năng hỗ trợ và các thao tác để rút/nạp tiền cùng với cổng trò chuyện trực tiếp để được tư vấn. Giao diện game mang lại cho người chơi cảm giác chân thật và thoải mái nhất, giúp người chơi không bị mỏi mắt khi chơi trong thời gian dài.
Hướng Dẫn Tải Game Hit Club
Bạn có thể trải nghiệm Hit Club với 2 phiên bản: Hit Club APK cho thiết bị Android và Hit Club iOS cho thiết bị như iPhone, iPad.
Tải ứng dụng game:
Click nút tải ứng dụng game ở trên (phiên bản APK/Android hoặc iOS tùy theo thiết bị của bạn).
Chờ cho quá trình tải xuống hoàn tất.
Cài đặt ứng dụng:
Khi quá trình tải xuống hoàn tất, mở tệp APK hoặc iOS và cài đặt ứng dụng trên thiết bị của bạn.
Bắt đầu trải nghiệm:
Mở ứng dụng và bắt đầu trải nghiệm Hit Club.
Với Hit Club, bạn sẽ khám phá thế giới game đỉnh cao với giao diện đẹp mắt và trải nghiệm chơi game tuyệt vời. Hãy tải ngay để tham gia vào cuộc phiêu lưu casino độc đáo và đầy hứng khởi!
http://mexicanpharmacy.company/# buying prescription drugs in mexico mexicanpharmacy.company
erectile dysfunction drugs best ed pills non prescription – ed pills that really work edpills.tech
https://canadiandrugs.tech/# best canadian online pharmacy reviews canadiandrugs.tech
https://edpills.tech/# erectile dysfunction pills edpills.tech
india online pharmacy indian pharmacy – mail order pharmacy india indiapharmacy.guru
https://edpills.tech/# pills erectile dysfunction edpills.tech
http://canadiandrugs.tech/# ed meds online canada canadiandrugs.tech
http://edpills.tech/# mens ed pills edpills.tech
best online canadian pharmacy buying from canadian pharmacies buying drugs from canada canadiandrugs.tech
https://canadiandrugs.tech/# best rated canadian pharmacy canadiandrugs.tech
ed meds medications for ed – ed pill edpills.tech
https://edpills.tech/# erectile dysfunction drugs edpills.tech
Как включить аппаратную виртуализацию
Абузоустойчивый серверов для Хрумера и GSA AMSTERDAM!!!
Оптимальная Настройка: Включение Аппаратной Виртуализации
При обсуждении виртуальных серверов (VPS/VDS) и дедикатед серверов, важно также уделить внимание оптимальной настройке, включая аппаратную виртуализацию. Этот важный аспект может значительно повлиять на производительность вашего сервера.
Высокоскоростной Интернет: До 1000 Мбит/с
https://canadapharmacy.guru/# canadian pharmacy mall canadapharmacy.guru
best rated canadian pharmacy pet meds without vet prescription canada – canadian pharmacy 365 canadiandrugs.tech
http://canadiandrugs.tech/# canadian pharmacy online canadiandrugs.tech
Дедик сервер
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Виртуальные сервера (VPS/VDS) и Дедик Сервер: Оптимальное Решение для Вашего Проекта
В мире современных вычислений виртуальные сервера (VPS/VDS) и дедик сервера становятся ключевыми элементами успешного бизнеса и онлайн-проектов. Выбор оптимальной операционной системы и типа сервера являются решающими шагами в создании надежной и эффективной инфраструктуры. Наши VPS/VDS серверы Windows и Linux, доступные от 13 рублей, а также дедик серверы, предлагают целый ряд преимуществ, делая их неотъемлемыми инструментами для развития вашего проекта.
http://indiapharmacy.guru/# Online medicine home delivery indiapharmacy.guru
Дедикатед Серверы
Абузоустойчивые сервера в Амстердаме, они позволят работать с сайтами которые не открываются в РФ, работая Хрумером и GSA пробив намного выше.
Виртуальные сервера (VPS/VDS) и Дедик Сервер: Оптимальное Решение для Вашего Проекта
В мире современных вычислений виртуальные сервера (VPS/VDS) и дедик сервера становятся ключевыми элементами успешного бизнеса и онлайн-проектов. Выбор оптимальной операционной системы и типа сервера являются решающими шагами в создании надежной и эффективной инфраструктуры. Наши VPS/VDS серверы Windows и Linux, доступные от 13 рублей, а также дедик серверы, предлагают целый ряд преимуществ, делая их неотъемлемыми инструментами для развития вашего проекта.
Высокоскоростной Интернет: До 1000 Мбит/с
http://edpills.tech/# ed dysfunction treatment edpills.tech
indian pharmacies safe indian pharmacy online top 10 pharmacies in india indiapharmacy.guru
http://indiapharmacy.guru/# buy prescription drugs from india indiapharmacy.guru
buy cipro online canada: buy ciprofloxacin over the counter – ciprofloxacin
Paxlovid buy online: paxlovid buy – paxlovid buy
ciprofloxacin generic price: cipro generic – ciprofloxacin generic
ciprofloxacin generic cipro buy ciprofloxacin
http://prednisone.bid/# prednisone 10mg prices
prednisone 2.5 tablet: prednisone price south africa – prednisone buy canada
http://ciprofloxacin.life/# buy generic ciprofloxacin
amoxicillin 50 mg tablets: amoxicillin 500mg capsule cost – medicine amoxicillin 500
prednisone online: where can i order prednisone 20mg – 50 mg prednisone tablet
prednisone 2 mg daily: prednisone prescription online – prednisone for sale in canada
amoxicillin 875 125 mg tab amoxicillin 250 mg amoxicillin tablets in india
Как включить аппаратную виртуализацию
Абузоустойчивый серверов для Хрумера и GSA AMSTERDAM!!!
Высокоскоростной Интернет: До 1000 Мбит/с
Скорость интернет-соединения играет решающую роль в успешной работе вашего проекта. Наши VPS/VDS серверы, поддерживающие Windows и Linux, обеспечивают доступ к интернету со скоростью до 1000 Мбит/с. Это гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Итак, при выборе виртуального выделенного сервера VPS, обеспечьте своему проекту надежность, высокую производительность и защиту от DDoS. Получите доступ к качественной инфраструктуре с поддержкой Windows и Linux уже от 13 рублей
prednisone 20mg cheap: prednisone pills cost – prednisone 10mg tabs
Can you tell us more about this? I’d love to find out more details.
Just want to say your article is as surprising.
The clearness in your post is simply nice and i can assume you
are an expert on this subject. Well with your permission allow me to
grab your RSS feed to keep up to date with forthcoming post.
Thanks a million and please continue the gratifying work.
amoxicillin capsule 500mg price: amoxicillin cost australia – amoxicillin 500mg over the counter
paxlovid india: Paxlovid over the counter – paxlovid generic
https://paxlovid.win/# paxlovid covid
Абузоустойчивые сервера в Амстердаме, они позволят работать с сайтами которые не открываются в РФ, работая Хрумером и GSA пробив намного выше.
Аренда виртуального сервера (VPS): Эффективность, Надежность и Защита от DDoS от 13 рублей
Выбор виртуального сервера – это важный этап в создании успешной инфраструктуры для вашего проекта. Наши VPS серверы предоставляют аренду как под операционные системы Windows, так и Linux, с доступом к накопителям SSD eMLC. Эти накопители гарантируют высокую производительность и надежность, обеспечивая бесперебойную работу ваших приложений независимо от выбранной операционной системы.
prednisone uk: can i buy prednisone online in uk – prednisone 5mg capsules
виртуальный выделенный сервер vps
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Высокоскоростной Интернет: До 1000 Мбит/с
Скорость интернет-соединения играет решающую роль в успешной работе вашего проекта. Наши VPS/VDS серверы, поддерживающие Windows и Linux, обеспечивают доступ к интернету со скоростью до 1000 Мбит/с. Это гарантирует быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Итак, при выборе виртуального выделенного сервера VPS, обеспечьте своему проекту надежность, высокую производительность и защиту от DDoS. Получите доступ к качественной инфраструктуре с поддержкой Windows и Linux уже от 13 рублей
cipro 500mg best prices: cipro 500mg best prices – cipro ciprofloxacin
amoxacillian without a percription amoxicillin generic brand buy amoxicillin 500mg uk
buy paxlovid online: paxlovid india – paxlovid cost without insurance
You can definitely see your enthusiasm in the work you
write. The arena hopes for even more passionate writers such as you who aren’t afraid to
mention how they believe. At all times go after your heart.
Мощный дедик
Аренда мощного дедика (VPS): Абузоустойчивость, Эффективность, Надежность и Защита от DDoS от 13 рублей
Выбор виртуального сервера – это важный этап в создании успешной инфраструктуры для вашего проекта. Наши VPS серверы предоставляют аренду как под операционные системы Windows, так и Linux, с доступом к накопителям SSD eMLC. Эти накопители гарантируют высокую производительность и надежность, обеспечивая бесперебойную работу ваших приложений независимо от выбранной операционной системы.
Remarkable things here. I am very satisfied to see your
article. Thank you so much and I am having a look ahead to touch you.
Will you kindly drop me a e-mail?
выбрать сервер
Абузоустойчивый сервер для работы с Хрумером, GSA и всевозможными скриптами!
Есть дополнительная системах скидок, читайте описание в разделе оплата
Высокоскоростной Интернет: До 1000 Мбит/с**
Скорость интернет-соединения – еще один важный момент для успешной работы вашего проекта. Наши VPS серверы, арендуемые под Windows и Linux, предоставляют доступ к интернету со скоростью до 1000 Мбит/с, обеспечивая быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
buy cipro online: buy ciprofloxacin – buy cipro cheap
2024總統大選投票資格
can i order clomid without prescription: where to buy generic clomid without prescription – can i buy generic clomid
GTA777
how to buy amoxycillin: amoxicillin 500 mg cost – buy amoxicillin 500mg uk
https://ciprofloxacin.life/# cipro for sale
Paxlovid buy online: paxlovid – paxlovid cost without insurance
amoxicillin canada price buy amoxicillin 500mg usa amoxicillin 500
paxlovid for sale: Paxlovid over the counter – paxlovid pill
https://clomid.site/# can i get cheap clomid without insurance
z8ghSAWZZy8
clomid for sale: where buy clomid prices – can i get clomid without prescription
cost of generic clomid tablets: can i order cheap clomid pill – where to buy clomid
buy amoxicillin 500mg usa order amoxicillin 500mg buy amoxicillin online without prescription
purchase amoxicillin online: amoxicillin 500mg without prescription – buy amoxicillin canada
https://ciprofloxacin.life/# purchase cipro
Your style is unique compared to other folks I’ve read stuff from.
I appreciate you for posting when you have the opportunity,
Guess I’ll just bookmark this blog.
апостиль в новосибирске
paxlovid generic п»їpaxlovid paxlovid pill
RG trang chủ
amoxicillin without prescription: over the counter amoxicillin canada – where can you get amoxicillin
http://paxlovid.win/# paxlovid pharmacy
This post is invaluable. When can I find out more?
amoxicillin 750 mg price: amoxicillin online no prescription – amoxicillin 500 mg brand name
ciprofloxacin 500mg buy online: buy generic ciprofloxacin – purchase cipro
amoxicillin 500mg capsules order amoxicillin 500mg buying amoxicillin online
https://clomid.site/# can you buy generic clomid price
Excellent blog here! Also your web site loads up very
fast! What host are you using? Can I get your affiliate link to
your host? I wish my website loaded up as quickly as yours lol
Посоветуйте VPS
Поставщик предоставляет основное управление виртуальными серверами (VPS), предлагая клиентам разнообразие операционных систем для выбора (Windows Server, Linux CentOS, Debian).
Yes! Finally something about Beasiswa Unggulan di Kampus Surabaya.
how to get clomid no prescription: buying cheap clomid without insurance – where can i buy cheap clomid without prescription
https://ciprofloxacin.life/# cipro ciprofloxacin
https://amoxil.icu/# buy amoxicillin 500mg uk
I really enjoy reading and also appreciate your work.
safe erectile dysfunction pills how to treat ed
I constantly spent my half an hour to read this weblog’s content
daily along with a mug of coffee.
vigor vita cbd gummies vigor vita reviews
If you want to take much from this paragraph then you have
to apply these strategies to your won web site.
free robux pc robux codes
lso thank you for allowing me to comment!.
generic ed drugs ed drugs from india
levitra versus viagra how much does vardenafil cost
cost cenforce 100mg order cenforce 50mg online cheap
ed drugs e d prescriptions
最新的民調顯示,2024年台灣總統大選的競爭格局已逐漸明朗。根據不同來源的數據,目前民進黨的賴清德與民眾黨的柯文哲、國民黨的侯友宜正處於激烈的競爭中。
一項民調指出,賴清德的支持度平均約34.78%,侯友宜為29.55%,而柯文哲則為23.42%。
另一家媒體的民調顯示,賴清德的支持率為32%,侯友宜為27%,柯文哲則為21%。
台灣民意基金會的最新民調則顯示,賴清德以36.5%的支持率領先,柯文哲以29.1%緊隨其後,侯友宜則以20.4%位列第三。
綜合這些數據,可以看出賴清德在目前的民調中處於領先地位,但其他候選人的支持度也不容小覷,競爭十分激烈。這些民調結果反映了選民的當前看法,但選情仍有可能隨著選舉日的臨近而變化。
generic ed drugs cost male enhancement
This site really has all the information I wanted about this subject and didn’t know who to ask.
side effects of levitra levitra website
Your means of describing the whole thing in this paragraph
is really good, all be able to without difficulty be aware of it, Thanks a lot.
cheap erectile dysfunction pill buying ed pills online
I simply couldn’t depart your web site prior to suggesting that I extremely loved the usual information an individual provide to your visitors?
Is gonna be again incessantly to check out new
posts
what is the best ed drug cheap erectile dysfunction pill
民意調查
free robux pc free robux generator no verification
總統民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
https://nolvadex.fun/# tamoxifen and osteoporosis
online canadian pharmacy with prescription ed pills for sale
I see some amazingly important and kept up to length of your strength searching for in your on the site
buy misoprostol over the counter: buy cytotec online – Cytotec 200mcg price
zithromax 500mg over the counter: zithromax price south africa – where can i buy zithromax in canada
cytotec abortion pill: purchase cytotec – cytotec pills buy online
lisinopril 10 mg canada cost lisinopril capsule lisinopril 30
https://doxycyclinebestprice.pro/# buy doxycycline 100mg
mostbet peru mostbet deposit
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to more added agreeable from you!
However, how can we communicate?
Great info. Lucky me I found your website by accident (stumbleupon).
I have book-marked it for later!
buy ed pills pills for ed
https://doxycyclinebestprice.pro/# buy doxycycline
best ed treatment natural ed medications
can you buy zithromax online: zithromax capsules 250mg – zithromax capsules australia
https://lisinoprilbestprice.store/# lisinopril 40 mg no prescription
cytotec abortion pill: buy cytotec pills – buy cytotec over the counter
ed pills online india top ed pills
https://zithromaxbestprice.icu/# generic zithromax azithromycin
tamoxifen dose: tamoxifen menopause – tamoxifen generic
generic lisinopril 5 mg lisinopril pills for sale lisinopril 40mg
카지노사이트
온카마켓은 카지노와 관련된 정보를 공유하고 토론하는 커뮤니티입니다. 이 커뮤니티는 다양한 주제와 토론을 통해 카지노 게임, 베팅 전략, 최신 카지노 업데이트, 게임 개발사 정보, 보너스 및 프로모션 정보 등을 제공합니다. 여기에서 다른 카지노 애호가들과 의견을 나누고 유용한 정보를 얻을 수 있습니다.
온카마켓은 회원 간의 소통과 공유를 촉진하며, 카지노와 관련된 다양한 주제에 대한 토론을 즐길 수 있는 플랫폼입니다. 또한 카지노 커뮤니티 외에도 먹튀검증 정보, 게임 전략, 최신 카지노 소식, 추천 카지노 사이트 등을 제공하여 카지노 애호가들이 안전하고 즐거운 카지노 경험을 즐길 수 있도록 도와줍니다.
온카마켓은 카지노와 관련된 정보와 소식을 한눈에 확인하고 다른 플레이어들과 소통하는 좋은 장소입니다. 카지노와 베팅에 관심이 있는 분들에게 유용한 정보와 커뮤니티를 제공하는 온카마켓을 즐겨보세요.
카지노 커뮤니티 온카마켓은 온라인 카지노와 관련된 정보를 공유하고 소통하는 커뮤니티입니다. 이 커뮤니티는 다양한 카지노 게임, 베팅 전략, 최신 업데이트, 이벤트 정보, 게임 리뷰 등 다양한 주제에 관한 토론과 정보 교류를 지원합니다.
온카마켓에서는 카지노 게임에 관심 있는 플레이어들이 모여서 자유롭게 의견을 나누고 경험을 공유할 수 있습니다. 또한, 다양한 카지노 사이트의 정보와 신뢰성을 검증하는 역할을 하며, 회원들이 안전하게 카지노 게임을 즐길 수 있도록 정보를 제공합니다.
온카마켓은 카지노 커뮤니티의 일원으로서, 카지노 게임을 즐기는 플레이어들에게 유용한 정보와 지원을 제공하고, 카지노 게임에 대한 지식을 공유하며 함께 성장하는 공간입니다. 카지노에 관심이 있는 분들에게는 유용한 커뮤니티로서 온카마켓을 소개합니다
http://nolvadex.fun/# femara vs tamoxifen
new ed drugs best ed pills non prescription cheap ed drugs online
民調
cheap doxycycline online: generic for doxycycline – doxycycline 150 mg
doxycycline 100mg: buy doxycycline online uk – doxycycline tablets
總統民調
cheap ed drugs buy erection pills best ed treatment
http://lisinoprilbestprice.store/# prescription medicine lisinopril
buy doxycycline without prescription uk: doxy 200 – buy doxycycline 100mg
民調
最新的民調顯示,2024年台灣總統大選的競爭格局已逐漸明朗。根據不同來源的數據,目前民進黨的賴清德與民眾黨的柯文哲、國民黨的侯友宜正處於激烈的競爭中。
一項總統民調指出,賴清德的支持度平均約34.78%,侯友宜為29.55%,而柯文哲則為23.42%。
另一家媒體的民調顯示,賴清德的支持率為32%,侯友宜為27%,柯文哲則為21%。
台灣民意基金會的最新民調則顯示,賴清德以36.5%的支持率領先,柯文哲以29.1%緊隨其後,侯友宜則以20.4%位列第三。
綜合這些數據,可以看出賴清德在目前的民調中處於領先地位,但其他候選人的支持度也不容小覷,競爭十分激烈。這些民調結果反映了選民的當前看法,但選情仍有可能隨著選舉日的臨近而變化。
buy generic zithromax online generic zithromax 500mg india zithromax antibiotic without prescription
https://doxycyclinebestprice.pro/# doxycycline generic
I know this if off topic but I’m looking into starting my own blog and was wondering
what all is needed to get set up? I’m assuming having a blog like yours would cost a pretty penny?
I’m not very internet smart so I’m not 100% certain. Any tips or
advice would be greatly appreciated. Kudos
民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
2024總統大選民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
lisinopril 5 mg: lisinopril sale – lisinopril 40 mg tablet
nolvadex pills: tamoxifen lawsuit – arimidex vs tamoxifen bodybuilding
http://lisinoprilbestprice.store/# lisinopril pills 10 mg
апостиль в новосибирске
民意調查
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
doxycycline pills: online doxycycline – doxy
buy lisinopril 20 mg online united states: zestril 10 mg online – buy lisinopril uk
I think this is one of the such a lot important info for
me. And i am satisfied reading your article. But should remark on some common issues,
The website style is wonderful, the articles is in reality great : D.
Just right activity, cheers
https://lisinoprilbestprice.store/# buy zestoretic
best ed medicine in india medicine for erectile best drugs for ed
can you buy zithromax online zithromax 250mg where can i buy zithromax capsules
http://mexicopharm.com/# best mexican online pharmacies mexicopharm.com
online casino australia real money fast payout online casino australia paypal online casino live roulette australia
buy medicines online in india: indian pharmacy to usa – pharmacy website india indiapharm.llc
global pharmacy canada Cheapest drug prices Canada safe reliable canadian pharmacy canadapharm.life
canadian drugs online: Pharmacies in Canada that ship to the US – canada drugs online review canadapharm.life
mail order pharmacy india: India Post sending medicines to USA – reputable indian online pharmacy indiapharm.llc
cheap viagra generic viagra 100 mg cost viagra pills
For most recent information you have to pay a quick visit internet and on world-wide-web I found this web page
as a finest site for latest updates.
sildenafil 50 mg price sildenafil citrate tablets cenforce 200 usa
indian pharmacy: India Post sending medicines to USA – Online medicine order indiapharm.llc
http://indiapharm.llc/# indian pharmacy indiapharm.llc
民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
viagra online canada viagra online cheap sildenafil 50 mg tablets
ban ca xeng
Có đa dạng loại game bắn cá, mỗi thể loại mang theo những quy tắc và phong cách chơi độc đáo. Vì vậy, người mới tham gia nên dành thời gian để nắm vững luật lệ của từng loại mà họ quan tâm. Chẳng hạn, việc hiểu rõ các nguyên tắc cơ bản như săn cá, tính điểm, loại mồi, cách đặt cược, hay quá trình đổi xèng là quan trọng để có trải nghiệm chơi tốt nhất.
Bên cạnh đó, khi tham gia vào trò chơi, cũng cần phải đảm bảo rằng bạn hiểu rõ các quy định cụ thể của từng cổng game để tránh những hiểu lầm không mong muốn.
Nhiều cổng game bắn cá hiện nay cung cấp lựa chọn bàn chơi miễn phí, mở ra cơ hội cho người chơi mới thâm nhập thế giới này mà không cần phải đầu tư xèng. Bằng cách tham gia vào các ván chơi không mất chi phí, người chơi có thể học được quy tắc chơi, tiếp xúc với các chiến thuật, hiểu rõ sự biến động của trò chơi, và khám phá các nền tảng và phần mềm mà không phải lo lắng về áp lực tài chính.
Quá trình trải nghiệm miễn phí sẽ giúp người chơi mới tích luỹ kinh nghiệm, xây dựng lòng tin vào bản thân, từ đó họ có thể chuyển đổi sang chơi với xèng mà không gặp phải nhiều khó khăn và ngần ngại.
Hiểu rõ về ý nghĩa của vị trí trong bàn săn cá là vô cùng quan trọng. Ví dụ, người chơi đặt mình ở vị trí đầu bàn phải đối mặt với thách thức của việc đưa ra quyết định mà không biết được cách mà đối thủ phía sau sẽ hành động. Ngược lại, người chơi ở vị trí giữa có đôi chút lợi thế khi phải đối mặt với ít áp lực hơn, có thể quan sát cách chơi của một số đối thủ trước đó, nhưng vẫn phải đưa ra quyết định mà không biết trước hành động của một số đối thủ khác. Người chơi ở vị trí cuối được ưu thế vì họ có thể quan sát và phân tích hành động của đối thủ trước khi tới lượt họ đưa ra quyết định. Nguyên tắc chung là, vị trí càng cao, người chơi càng có lợi thế trong
ban ca xeng.
medication from mexico pharmacy: mexican pharmacy – buying from online mexican pharmacy mexicopharm.com
viagra tablet viagra soft tabs sildenafil
перевод на русский
https://indiapharm.llc/# top 10 pharmacies in india indiapharm.llc
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
mexican drugstore online: Mexico pharmacy online – mexican border pharmacies shipping to usa mexicopharm.com
民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
pharmacy com canada Canada pharmacy online reputable canadian online pharmacy canadapharm.life
mexican online pharmacies prescription drugs: mexican online pharmacies prescription drugs – buying prescription drugs in mexico online mexicopharm.com
http://indiapharm.llc/# buy medicines online in india indiapharm.llc
總統民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
online canadian pharmacy review: Cheapest drug prices Canada – canada drugstore pharmacy rx canadapharm.life
XAIGATE is a secure and user-friendly crypto payment gateway that allows businesses to accept cryptocurrency payments from customers around the world. With XAIGATE, businesses can easily integrate cryptocurrency payments into their existing websites or online stores. If you are a business owner who is looking to start accepting cryptocurrency payments, XAIGATE is the perfect solution for you. Sign up for a free trial today and start experiencing the benefits of cryptocurrency payments firsthand
https://indiapharm.llc/# cheapest online pharmacy india indiapharm.llc
最新民調
民意調查是什麼?民調什麼意思?
民意調查又稱為輿論調查或民意測驗,簡稱民調。一般而言,民調是一種為了解公眾對某些政治、社會問題與政策的意見和態度,由專業民調公司或媒體進行的調查方法。
目的在於通過網路、電話、或書面等媒介,對大量樣本的問卷調查抽樣,利用統計學的抽樣理論來推斷較為客觀,且能較為精確地推論社會輿論或民意動向的一種方法。
以下是民意調查的一些基本特點和重要性:
抽樣:由於不可能向每一個人詢問意見,所以調查者會選擇一個代表性的樣本進行調查。這樣本的大小和抽樣方法都會影響調查的準確性和可靠性。
問卷設計:為了確保獲得可靠的結果,問卷必須經過精心設計,問題要清晰、不帶偏見,且易於理解。
數據分析:收集到的數據將被分析以得出結論。這可能包括計算百分比、平均值、標準差等,以及更複雜的統計分析。
多種用途:民意調查可以用於各種目的,包括政策制定、選舉預測、市場研究、社會科學研究等。
限制:雖然民意調查是一個有價值的工具,但它也有其限制。例如,樣本可能不完全代表目標人群,或者問卷的設計可能導致偏見。
影響決策:民意調查的結果常常被政府、企業和其他組織用來影響其決策。
透明度和誠實:為了維護調查的可信度,調查組織應該提供其調查方法、樣本大小、抽樣方法和可能的誤差範圍等詳細資訊。
民調是怎麼調查的?
民意調查(輿論調查)的意義是指為瞭解大多數民眾的看法、意見、利益與需求,以科學、系統與公正的資料,蒐集可以代表全部群眾(母體)的部分群眾(抽樣),設計問卷題目後,以人工或電腦詢問部分民眾對特定議題的看法與評價,利用抽樣出來部分民眾的意見與看法,來推論目前全部民眾的意見與看法,藉以衡量社會與政治的狀態。
以下是進行民調調查的基本步驟:
定義目標和目的:首先,調查者需要明確調查的目的。是要了解公眾對某個政策的看法?還是要評估某個政治候選人的支持率?
設計問卷:根據調查目的,研究者會設計一份問卷。問卷應該包含清晰、不帶偏見的問題,並避免導向性的語言。
選擇樣本:因為通常不可能調查所有人,所以會選擇一部分人作為代表。這部分人被稱為“樣本”。最理想的情況是使用隨機抽樣,以確保每個人都有被選中的機會。
收集數據:有多種方法可以收集數據,如面對面訪問、電話訪問、郵件調查或在線調查。
數據分析:一旦數據被收集,研究者會使用統計工具和技術進行分析,得出結論或洞見。
報告結果:分析完數據後,研究者會編寫報告或發布結果。報告通常會提供調查方法、樣本大小、誤差範圍和主要發現。
解釋誤差範圍:多數民調報告都會提供誤差範圍,例如“±3%”。這表示實際的結果有可能在報告結果的3%範圍內上下浮動。
民調調查的質量和可信度很大程度上取決於其設計和實施的方法。若是由專業和無偏見的組織進行,且使用科學的方法,那麼民調結果往往較為可靠。但即使是最高質量的民調也會有一定的誤差,因此解讀時應保持批判性思考。
為什麼要做民調?
民調提供了一種系統性的方式來了解大眾的意見、態度和信念。進行民調的原因多種多樣,以下是一些主要的動機:
政策制定和評估:政府和政策制定者進行民調,以了解公眾對某一議題或政策的看法。這有助於制定或調整政策,以反映大眾的需求和意見。
選舉和政治活動:政黨和候選人通常使用民調來評估自己在選舉中的地位,了解哪些議題對選民最重要,以及如何調整策略以吸引更多支持。
市場研究:企業和組織進行民調以了解消費者對產品、服務或品牌的態度,從而制定或調整市場策略。
社會科學研究:學者和研究者使用民調來了解人們的社會、文化和心理特征,以及其與行為的關係。
公眾與媒體的期望:民調提供了一種方式,使公眾、政府和企業得以了解社會的整體趨勢和態度。媒體也經常報導民調結果,提供公眾對當前議題的見解。
提供反饋和評估:無論是企業還是政府,都可以透過民調了解其表現、服務或政策的效果,並根據反饋進行改進。
預測和趨勢分析:民調可以幫助預測某些趨勢或行為的未來發展,如選舉結果、市場需求等。
教育和提高公眾意識:通過進行和公布民調,可以促使公眾對某一議題或問題有更深入的了解和討論。
民調可信嗎?
民意調查的結果數據隨處可見,尤其是政治性民調結果幾乎可說是天天在新聞上放送,對總統的滿意度下降了多少百分比,然而大家又信多少?
在景美市場的訪問中,我們了解到民眾對民調有一些普遍的觀點。大多數受訪者表示,他們對民調的可信度存有疑慮,主要原因是他們擔心政府可能會在調查中進行操控,以符合特定政治目標。
受訪者還提到,民意調查的結果通常不會對他們的投票意願產生影響。換句話說,他們的選擇通常受到更多因素的影響,例如候選人的政策立場和政府做事的認真與否,而不是單純依賴民調結果。
從訪問中我們可以得出的結論是,大多數民眾對民調持謹慎態度,並認為它們對他們的投票決策影響有限。
vidalista 20 how to use sildenafil citrate tablets vidalista 60 online cheap
https://indiapharm.llc/# online shopping pharmacy india indiapharm.llc
canadian pharmacy review: Cheapest drug prices Canada – buy drugs from canada canadapharm.life
sildenafil citrate tablets 100 mg viagra 100 mg viagra pills from canada
mexican pharmacy: buying prescription drugs in mexico – mexican online pharmacies prescription drugs mexicopharm.com
buy ed medicines online mens erection pills generic drugs for ed
indian pharmacy: India Post sending medicines to USA – top 10 pharmacies in india indiapharm.llc
male erection pills best ed drugs for women natural ed remedies
mexican border pharmacies shipping to usa: Best pharmacy in Mexico – mexico pharmacies prescription drugs mexicopharm.com
online shopping pharmacy india India pharmacy of the world online shopping pharmacy india indiapharm.llc
https://indiapharm.llc/# cheapest online pharmacy india indiapharm.llc
strongest ed medication pills for ed best ed drugs for seniors
https://indiapharm.llc/# buy prescription drugs from india indiapharm.llc
pharmacies in mexico that ship to usa: Mexico pharmacy online – mexican pharmaceuticals online mexicopharm.com
reputable mexican pharmacies online: Best pharmacy in Mexico – mexican online pharmacies prescription drugs mexicopharm.com
https://indiapharm.llc/# mail order pharmacy india indiapharm.llc
Thanks for such a great post and the review, I am totally impressed! Keep stuff like this coming.
top ed pills buy erection pills best ed non prescription pill
ed drug prices treatments for ed what is the best ed pill
https://kamagradelivery.pro/# kamagra
Vardenafil price: Levitra online – Buy Levitra 20mg online
best ed pills non prescription cheap erectile dysfunction pill ed dysfunction treatment
buy tadalafil from india Buy tadalafil online 5mg tadalafil generic
tadalafil 5 mg coupon: Tadalafil 20mg price in Canada – 20 mg tadalafil cost
http://kamagradelivery.pro/# super kamagra
http://edpillsdelivery.pro/# mens erection pills
Just desire to say your article is as astounding.
The clarity in your post is simply spectacular and i can assume you are an expert on this subject.
Well with your permission let me to grab your feed to keep
up to date with forthcoming post. Thanks a million and please continue the enjoyable work.
generic ed drugs fda approved ed drugs list generic ed drugs canada
百樂達斯
Levitra 10 mg buy online: Buy generic Levitra online – Vardenafil buy online
mostbet tГјrkiye giriЕџ mostbet app mostbet twitter
https://tadalafildelivery.pro/# cheap tadalafil online
Wow, wonderful blog format! How lengthy have you been blogging for?
you make running a blog look easy. The total look of your website
is excellent, as smartly as the content!
robux generator free free rbx robux
п»їLevitra price: Vardenafil buy online – Levitra 10 mg best price
https://edpillsdelivery.pro/# cure ed
super kamagra cheap kamagra buy kamagra online usa
I wanted to thank you for this great read!! I definitely enjoying every little bit of it I have you bookmarked to check out new stuff you post.
where can i buy sildenafil over the counter: Sildenafil price – generic sildenafil citrate 100mg
https://tadalafildelivery.pro/# buy tadalafil 20mg price
erectile dysfunction drug: pills for erection – ed drugs list
http://levitradelivery.pro/# Levitra 20 mg for sale
These are really fantastic ideas in regarding blogging.
You have touched some fastidious points here. Any way keep up wrinting.
apps for free robux roblox gift card get free robux
Peculiar article, totally what I needed.
canadian online pharmacy sildenafil: Sildenafil price – sildenafil gel india
ed treatment meds generic ed pills from india what is the best non prescription erectile dysfunction
http://tadalafildelivery.pro/# tadalafil 20mg pills
more than ten times as large as the Rab-bit, and
Hey theгe would you mind letting mme know whіch web host
үou’re woгking wіth? I’ve loaded youг bog in 3 completely dіfferent web browsers ɑnd I must sаy this blog loadss ɑ lot quicker tһen most.
Ϲan you recommend a g᧐od internet hosting provider аt a reasonable price?
Cheers, I appreciate it!
Also isit mү blog post :: jasa pbn terbaik
very satisfying in terms of information thank you very much. <a href="https://balashover.ru/ads/www/delivery/ck.php?ct=1
Vardenafil price: Levitra 10 mg buy online – buy Levitra over the counter
non prescription erection pills best ed drugs for seniors pills used for erectile dysfunction
pills for ed non prescription ed pills most popular ed medication
http://sildenafildelivery.pro/# sildenafil 50 mg cost
Бизнес в Интернете
the best ed pills: cheapest ed pills – erectile dysfunction drug
cheap ed pills: ed pills delivery – ed medication online
ed drugs available in canada best ed drugs for women top erection pills
cheap erectile dysfunction pill buy ed drugs online new ed pills
http://tadalafildelivery.pro/# tadalafil mexico price
http://tadalafildelivery.pro/# generic tadalafil india
buy sildenafil generic: Cheapest Sildenafil online – best sildenafil coupon
best non prescription erection pills ed meds buy erection pills
where to get prednisone: cheapest prednisone – 100 mg prednisone daily
cheap erectile dysfunction pill top ed pills erectile dysfunction drugs
https://paxlovid.guru/# buy paxlovid online
natural ed medications what erectile dysfunction pill is the Best ed drugs canada
https://paxlovid.guru/# paxlovid india
Paxlovid over the counter paxlovid best price buy paxlovid online
https://prednisone.auction/# prednisone 20mg for sale
over the counter drugs for ed ed drugs online from india cheapest ed pills online
What’s up everybody, here every person is sharing these kinds of familiarity,
so it’s good to read this weblog, and I used to visit this
webpage everyday.
http://amoxil.guru/# generic amoxicillin over the counter
If you are going for most excellent contents like myself, simply go to see this
website everyday because it gives quality
contents, thanks
My brother recommended I might like this blog. He was entirely right.
This post truly made my day. You cann’t imagine just how
much time I had spent for this information! Thanks!
tablets to increase female libido cheap erectile dysfunction pill Generic Ed Drugs Fda Approved
best ed drugs over counter strongest medications for erectile dysfunction erectile dysfunction drugs
canadian pharmacy amoxicillin: Amoxicillin 500mg buy online – amoxicillin 500 mg where to buy
I got thіs website frⲟm my buddy who shared ᴡith me regarding
tһis site and ɑt the momеnt this time I am browsing
this web paɡe ɑnd reading ѵery informative articles аt
this timе.
My webb blog: backlink judi
http://prednisone.auction/# prednisone 10mg tabs
https://amoxil.guru/# buy amoxil
new ed drugs ed pills india non prescription erection pills
Wow, wonderful blog layout! How long have you been blogging for?
you make blogging look easy. The overall look of your site is excellent, as well
as the content!
paxlovid generic Paxlovid buy online paxlovid generic
http://clomid.auction/# buying generic clomid without a prescription
Great article.
ed drugs online best ed drugs for seniors best prescription ed drugs
I’ve been surfing online more than three hours today, yet I never found any interesting article like yours.
It is pretty worth enough for me. In my opinion, if all webmasters and bloggers made good content as you did, the net
will be much more useful than ever before.
http://prednisone.auction/# non prescription prednisone 20mg
non prescription erection pills generic ed pills from india cheap ed pills near me
https://prednisone.auction/# prednisone daily use
Hi this is kinda of off topic but I was wondering if blogs use
WYSIWYG editors or if you have to manually code with
HTML. I’m starting a blog soon but have no coding experience
so I wanted to get advice from someone with experience.
Any help would be enormously appreciated!
This is a topic that is close to my heart… Many thanks!
Where are your contact details though?
buy generic clomid without rx: cheapest clomid – can you buy clomid for sale
As the admin of this website is working, no hesitation very soon it will be
famous, due to its feature contents.
hellspin canada hellspin review hellspin casino no deposit
Quality articles or reviews is the crucial to be a focus for the people to go to see the web site, that’s what this web
page is providing.
SkyCrown bonus code SkyCrown Sky Crown casino login
Very good website you have here but I was curious
about if you knew of any community forums that cover the
same topics discussed in this article? I’d really love
to be a part of online community where I can get responses from other
experienced people that share the same interest. If you have any recommendations, please let me know.
Appreciate it!
https://paxlovid.guru/# paxlovid price
King Billy bonus code King Billy casino King Billy review
http://paxlovid.guru/# paxlovid for sale
z8ghSAWZZy8
http://amoxil.guru/# cost of amoxicillin 875 mg
buy paxlovid online Buy Paxlovid privately paxlovid pharmacy
paxlovid india: paxlovid generic – paxlovid pill
Fair Go casino no deposit FairGo casino real money Fair Go casino
Great Article it its really informative and innovative keep us posted with new updates. its was really valuable. thanks a lot.
RocketPlay bonus code RocketPlay casino no deposit bonus RocketPlay sign in
https://finasteride.men/# buy cheap propecia without insurance
get cheap propecia without insurance: cost of cheap propecia now – order generic propecia no prescription
娛樂城
http://misoprostol.shop/# buy cytotec over the counter
Bizzo casino australia Bizzo bonus code Bizzo casino login
buy cytotec over the counter: cheap cytotec – Abortion pills online
Woo sign up Woo review Woo
best bio health cbd gummies scam best reviewed cbd gummies cbd gummies shark tank
where can i get zithromax: cheap zithromax pills – zithromax price south africa
https://lisinopril.fun/# lisinopril sale
dr oz super cbd gummies dr oz cbd gummies reviews consumer reports dr oz cbd gummies
z8ghSAWZZy8
If you want to take a good deal from this paragraph then you have to apply these techniques
to your won website.
lasix 40 mg Buy Furosemide lasix 100 mg
At this time I am going to do my breakfast, afterward having my breakfast coming again to read other news.
zithromax z-pak: zithromax 250 – zithromax for sale 500 mg
http://misoprostol.shop/# cytotec abortion pill
http://finasteride.men/# cost propecia without a prescription
cost of generic propecia: Buy finasteride 1mg – buying cheap propecia without insurance
lisinopril pills: cheapest lisinopril – 60 lisinopril cost
https://misoprostol.shop/# buy cytotec over the counter
Misoprostol 200 mg buy online: Buy Abortion Pills Online – buy cytotec over the counter
Cytotec 200mcg price cheap cytotec buy misoprostol over the counter
best ed drugs for seniors ed treatment meds buying ed pills
generic ed medication from india ed treatments generic ed pills from india cheap
http://furosemide.pro/# lasix
Abortion pills online: Misoprostol best price in pharmacy – cytotec pills buy online
https://azithromycin.store/# zithromax azithromycin
I’ll immediately grab your rss feed as I can’t find your e-mail subscription link or e-newsletter service.
Do you have any? Please let me realize in order that I may just subscribe.
Thanks.
treatment for ed mens erection pills generic ed pills from india cheap
https://azithromycin.store/# can you buy zithromax over the counter in canada
viagra pills sildenafil 50mg sildenafil citrate for sale
Your article helped me a lot, is there any more related content? Thanks! https://www.binance.com/lv/join?ref=RQUR4BEO
buying generic propecia price: Best place to buy propecia – buying cheap propecia
zithromax 1000 mg pills: buy zithromax over the counter – zithromax online paypal
sildenafil citrate 20 mg suhagra online cheap sildenafil online uk
http://finasteride.men/# propecia generics
order propecia for sale buy cheap propecia for sale cost of generic propecia price
sildenafil tablet priligy 30mg sildenafil 50 mg tablet price in india
purchase cytotec: Misoprostol best price in pharmacy – Cytotec 200mcg price
z8ghSAWZZy8
http://misoprostol.shop/# buy cytotec in usa
order propecia without dr prescription: cost generic propecia without rx – buy propecia no prescription
http://azithromycin.store/# can you buy zithromax over the counter in mexico
https://misoprostol.shop/# cytotec abortion pill
https://misoprostol.shop/# buy cytotec pills
п»їcytotec pills online: buy cytotec online – buy cytotec in usa
lisinopril 40 mg mexico: over the counter lisinopril – prinivil 20 mg tablet
lasix for sale Buy Furosemide furosemide 100 mg
buy lasix online: Buy Lasix – furosemide 40mg
https://azithromycin.store/# buy zithromax
was standing. He wore an old brown hunting suit, so
know, this sort of life! When I used to read fair-y
lasix generic: Buy Furosemide – furosemide 100mg
https://misoprostol.shop/# buy cytotec online fast delivery
get generic propecia without dr prescription buy propecia cheap propecia for sale
It’s going to be finish of mine day, but before ending I am reading this fantastic
post to improve my knowledge.
cytotec online: Misoprostol best price in pharmacy – buy cytotec in usa
zithromax for sale cheap: buy zithromax z-pak online – buy zithromax 1000mg online
https://azithromycin.store/# zithromax online pharmacy canada
what to say, the cook took the pot from the fire,
https://azithromycin.store/# zithromax cost canada
https://misoprostol.shop/# buy cytotec
fetch me a pair of gloves and a fan! Quick, now!”
comprare farmaci online all’estero: kamagra oral jelly – farmacia online senza ricetta
farmaci senza ricetta elenco: avanafil prezzo – comprare farmaci online all’estero
farmacie online affidabili kamagra gel prezzo acquistare farmaci senza ricetta
http://avanafilitalia.online/# farmacia online
such a dear thing,” Al-ice went on half to her-self as
top farmacia online: cialis generico – farmaci senza ricetta elenco
Hey there just wanted to give you a quick heads
up. The words in your post seem to be running off the screen in Ie.
I’m not sure if this is a format issue or something to do with internet browser compatibility but I
figured I’d post to let you know. The style and design look great
though! Hope you get the problem fixed soon. Kudos
Way cool! Some extremely valid points! I appreciate you writing this article plus the rest of the site
is really good.
Right away I am ready to do my breakfast, after having my breakfast coming yet
again to read other news.
Hello There. I found your blog the usage of msn. This is
a really well written article. I’ll make sure to bookmark it
and come back to read more of your useful information. Thank you for the
post. I will certainly return.
http://kamagraitalia.shop/# farmacie online sicure
with its arms fold-ed, smok-ing a queer pipe with
If some one needs expert view regarding running a blog afterward
i recommend him/her to visit this weblog, Keep up the
nice job.
farmacie online autorizzate elenco: cialis generico – farmacie online affidabili
http://sildenafilitalia.men/# gel per erezione in farmacia
Right here is the right webpage for anyone who wishes to find out about this topic.
You know a whole lot its almost tough to argue with you
(not that I actually would want to…HaHa). You definitely put a fresh
spin on a subject that’s been written about for many years.
Excellent stuff, just wonderful!
https://kamagraitalia.shop/# farmacie online autorizzate elenco
2024娛樂城
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
and knocked at the door with his fist. A foot-man
п»їfarmacia online migliore: Avanafil farmaco – farmacia online
http://sildenafilitalia.men/# esiste il viagra generico in farmacia
farmacie online autorizzate elenco avanafil generico comprare farmaci online con ricetta
https://www.xn—–7kccgclceaf3d0apdeeefre0dt2w.xn--p1ai/
migliori farmacie online 2023: kamagra oral jelly consegna 24 ore – farmacie online sicure
Dick looked doubtful, for their time was not
farmacie on line spedizione gratuita: farmacia online miglior prezzo – comprare farmaci online con ricetta
if—if I’d been the right size to do it! Oh dear!
miglior sito dove acquistare viagra: viagra generico – viagra prezzo farmacia 2023
There is certainly a great deal to learn about this subject.
I really like all the points you have made.
http://tadalafilitalia.pro/# acquistare farmaci senza ricetta
https://kamagraitalia.shop/# farmacia online piГ№ conveniente
farmacia online migliore kamagra oral jelly migliori farmacie online 2023
п»їfarmacia online migliore: Avanafil farmaco – п»їfarmacia online migliore
http://sildenafilitalia.men/# gel per erezione in farmacia
three weeks!”
http://sildenafilitalia.men/# viagra online spedizione gratuita
to think how she was to get out. At last she came to
farmacia online: farmacia online piГ№ conveniente – farmacia online migliore
I am not sure where you are getting your info, but good topic.
I needs to spend some time learning much more or understanding more.
Thanks for great info I was looking for this information for my
mission.
http://kamagraitalia.shop/# farmacia online miglior prezzo
farmacie online autorizzate elenco: Farmacie che vendono Cialis senza ricetta – farmacie online affidabili
farmacia online migliore: farmacia online migliore – farmacie online autorizzate elenco
http://kamagraitalia.shop/# farmacie online affidabili
acquisto farmaci con ricetta avanafil generico п»їfarmacia online migliore
http://avanafilitalia.online/# acquistare farmaci senza ricetta
that she was, she set out to hunt for them, but they
http://mexicanpharm.store/# best online pharmacies in mexico
reputable indian online pharmacy: indian pharmacies safe – best india pharmacy
keto + acv gummies reviews keto gummies do they really work is keto gummies safe
best online pharmacies in mexico: best online pharmacies in mexico – mexican rx online
МЕЗОНЕКТАР -сова -отзыв
http://indiapharm.life/# india pharmacy mail order
india pharmacy: top 10 online pharmacy in india – top 10 pharmacies in india
my canadian pharmacy canada pharmacy world canadian pharmacy drugs online
pharmacies in mexico that ship to usa: mexican online pharmacies prescription drugs – mexican border pharmacies shipping to usa
http://canadapharm.shop/# canada rx pharmacy world
http://indiapharm.life/# cheapest online pharmacy india
top online pharmacy india: best india pharmacy – india online pharmacy
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
http://indiapharm.life/# pharmacy website india
canadian drugs online: canadian pharmacy victoza – online canadian pharmacy review
mail order pharmacy india: india online pharmacy – п»їlegitimate online pharmacies india
https://indiapharm.life/# Online medicine home delivery
娛樂城
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
canadian neighbor pharmacy: reputable canadian pharmacy – reputable canadian pharmacy
pharmacy canadian: legit canadian pharmacy – is canadian pharmacy legit
mexican online pharmacies prescription drugs purple pharmacy mexico price list reputable mexican pharmacies online
http://canadapharm.shop/# best canadian pharmacy to buy from
http://mexicanpharm.store/# buying prescription drugs in mexico online
pharmacy website india: Online medicine home delivery – indian pharmacy
娛樂城
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
http://mexicanpharm.store/# mexico pharmacies prescription drugs
3a娛樂城
fair means or foul. And, indeed, the tactics employed
Online medicine home delivery: cheapest online pharmacy india – Online medicine home delivery
娛樂城
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
canadian pharmacy: canadian pharmacy reviews – best rated canadian pharmacy
http://indiapharm.life/# indian pharmacy online
best online pharmacies in mexico: medicine in mexico pharmacies – mexico pharmacy
canadadrugpharmacy com: canadian pharmacy ratings – canadian pharmacy 24
http://canadapharm.shop/# canadian pharmacy 24
https://mexicanpharm.store/# mexico drug stores pharmacies
purple pharmacy mexico price list buying prescription drugs in mexico best online pharmacies in mexico
fildena in the usa cenforce 100mg price in india sildenafil tablets
https://mexicanpharm.store/# best online pharmacies in mexico
best canadian pharmacy online: canadapharmacyonline com – canadian pharmacy 24
перевод документов
best online pharmacies in mexico: mexican drugstore online – pharmacies in mexico that ship to usa
vidalista 40 mg online sildenafil 100mg for sale viagra price per pill
http://indiapharm.life/# cheapest online pharmacy india
indian pharmacy paypal: indian pharmacy paypal – world pharmacy india
mexico drug stores pharmacies: reputable mexican pharmacies online – mexico drug stores pharmacies
https://canadapharm.shop/# canadian drug pharmacy
best online pharmacy india: top online pharmacy india – india pharmacy mail order
https://canadapharm.shop/# canadianpharmacyworld
Whoa! This blog looks exactly like my old one! It’s on a entirely different topic but it
has pretty much the same page layout and design. Wonderful
choice of colors!
http://mexicanpharm.store/# mexican border pharmacies shipping to usa
http://prednisonepharm.store/# buy prednisone without prescription
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
Excellent beat ! I wish to apprentice while you amend your
web site, how could i subscribe for a weblog site?
The account aided me a applicable deal. I had been tiny bit acquainted of this your broadcast provided vibrant transparent
concept
long term car rental Dubai
Dubai, a city known for its opulence and modernity, demands a mode of transportation that reflects its grandeur. For those seeking a cost-effective and reliable long-term solution, Somonion Rent Car LLC emerges as the premier choice for monthly car rentals in Dubai. With a diverse fleet ranging from compact cars to premium vehicles, the company promises an unmatched blend of affordability, flexibility, and personalized service.
Favorable Rental Conditions:
Understanding the potential financial strain of long-term car rentals, Somonion Rent Car LLC aims to make your journey more economical. The company offers flexible rental terms coupled with exclusive discounts for loyal customers. This commitment to affordability extends beyond the rental cost, as additional services such as insurance, maintenance, and repair ensure your safety and peace of mind throughout the duration of your rental.
A Plethora of Options:
Somonion Rent Car LLC boasts an extensive selection of vehicles to cater to diverse preferences and budgets. Whether you’re in the market for a sleek sedan or a spacious crossover, the company has the perfect car to complement your needs. The transparency in pricing, coupled with the ease of booking through their online platform, makes Somonion Rent Car LLC a hassle-free solution for those embarking on a long-term adventure in Dubai.
Car Rental Services Tailored for You:
Somonion Rent Car LLC doesn’t just offer cars; it provides a comprehensive range of rental services tailored to suit various occasions. From daily and weekly rentals to airport transfers and business travel, the company ensures that your stay in Dubai is not only comfortable but also exudes prestige. The fleet includes popular models such as the Nissan Altima 2018, KIA Forte 2018, Hyundai Elantra 2018, and the Toyota Camry Sport Edition 2020, all available for monthly rentals at competitive rates.
Featured Deals and Specials:
Somonion Rent Car LLC constantly updates its offerings to provide customers with the best deals. Featured cars like the Hyundai Sonata 2018 and Hyundai Santa Fe 2018 add a touch of luxury to your rental experience, with daily rates starting as low as AED 100. The company’s commitment to affordable luxury is further emphasized by the online booking system, allowing customers to secure the best deals in real-time through their website or by contacting the experts via phone or WhatsApp.
Conclusion:
Whether you’re a tourist looking to explore Dubai at your pace or a business traveler in need of a reliable and prestigious mode of transportation, Somonion Rent Car LLC stands as the go-to choice for monthly car rentals in Dubai. Unlock the ultimate mobility experience with Somonion, where affordability meets excellence, ensuring your journey through Dubai is as seamless and luxurious as the city itself. Contact Somonion Rent Car LLC today and embark on a journey where every mile is a testament to comfort, style, and unmatched service.
My brother suggested I might like this web site.
He used to be entirely right. This publish truly made my day.
You can not imagine just how so much time I had spent for this
information! Thank you!
Their global distribution network is top-tier https://nolvadex.pro/# nolvadex generic
https://nolvadex.pro/# how to prevent hair loss while on tamoxifen
Asking questions are in fact good thing if you are not understanding anything totally, except this
post gives good understanding yet.
http://cytotec.directory/# Misoprostol 200 mg buy online
prednisone 50 mg coupon: where to get prednisone – buy prednisone tablets uk
It was all right to say “Drink me,” but Al-ice was too
monthly car rental in dubai
Dubai, a city of grandeur and innovation, demands a transportation solution that matches its dynamic pace. Whether you’re a business executive, a tourist exploring the city, or someone in need of a reliable vehicle temporarily, car rental services in Dubai offer a flexible and cost-effective solution. In this guide, we’ll explore the popular car rental options in Dubai, catering to diverse needs and preferences.
Airport Car Rental: One-Way Pickup and Drop-off Road Trip Rentals:
For those who need to meet an important delegation at the airport or have a flight to another city, airport car rentals provide a seamless solution. Avoid the hassle of relying on public transport and ensure you reach your destination on time. With one-way pickup and drop-off options, you can effortlessly navigate your road trip, making business meetings or conferences immediately upon arrival.
Business Car Rental Deals & Corporate Vehicle Rentals in Dubai:
Companies without their own fleet or those finding transport maintenance too expensive can benefit from business car rental deals. This option is particularly suitable for businesses where a vehicle is needed only occasionally. By opting for corporate vehicle rentals, companies can optimize their staff structure, freeing employees from non-core functions while ensuring reliable transportation when necessary.
Tourist Car Rentals with Insurance in Dubai:
Tourists visiting Dubai can enjoy the freedom of exploring the city at their own pace with car rentals that come with insurance. This option allows travelers to choose a vehicle that suits the particulars of their trip without the hassle of dealing with insurance policies. Renting a car not only saves money and time compared to expensive city taxis but also ensures a trouble-free travel experience.
Daily Car Hire Near Me:
Daily car rental services are a convenient and cost-effective alternative to taxis in Dubai. Whether it’s for a business meeting, everyday use, or a luxury experience, you can find a suitable vehicle for a day on platforms like Smarketdrive.com. The website provides a secure and quick way to rent a car from certified and verified car rental companies, ensuring guarantees and safety.
Weekly Auto Rental Deals:
For those looking for flexibility throughout the week, weekly car rentals in Dubai offer a competent, attentive, and professional service. Whether you need a vehicle for a few days or an entire week, choosing a car rental weekly is a convenient and profitable option. The certified and tested car rental companies listed on Smarketdrive.com ensure a reliable and comfortable experience.
Monthly Car Rentals in Dubai:
When your personal car is undergoing extended repairs, or if you’re a frequent visitor to Dubai, monthly car rentals (long-term car rentals) become the ideal solution. Residents, businessmen, and tourists can benefit from the extensive options available on Smarketdrive.com, ensuring mobility and convenience throughout their stay in Dubai.
FAQ about Renting a Car in Dubai:
To address common queries about renting a car in Dubai, our FAQ section provides valuable insights and information. From rental terms to insurance coverage, it serves as a comprehensive guide for those considering the convenience of car rentals in the bustling city.
Conclusion:
Dubai’s popularity as a global destination is matched by its diverse and convenient car rental services. Whether for business, tourism, or daily commuting, the options available cater to every need. With reliable platforms like Smarketdrive.com, navigating Dubai becomes a seamless and enjoyable experience, offering both locals and visitors the ultimate freedom of mobility.
55five slot gacor Indonesia 2024
They bridge the gap between countries with their service https://prednisonepharm.store/# where to buy prednisone without prescription
and the long fall was o-ver.
Dubai, a city known for its opulence and modernity, demands a mode of transportation that reflects its grandeur. For those seeking a cost-effective and reliable long-term solution, Somonion Rent Car LLC emerges as the premier choice for monthly car rentals in Dubai. With a diverse fleet ranging from compact cars to premium vehicles, the company promises an unmatched blend of affordability, flexibility, and personalized service.
Favorable Rental Conditions:
Understanding the potential financial strain of long-term car rentals, Somonion Rent Car LLC aims to make your journey more economical. The company offers flexible rental terms coupled with exclusive discounts for loyal customers. This commitment to affordability extends beyond the rental cost, as additional services such as insurance, maintenance, and repair ensure your safety and peace of mind throughout the duration of your rental.
A Plethora of Options:
Somonion Rent Car LLC boasts an extensive selection of vehicles to cater to diverse preferences and budgets. Whether you’re in the market for a sleek sedan or a spacious crossover, the company has the perfect car to complement your needs. The transparency in pricing, coupled with the ease of booking through their online platform, makes Somonion Rent Car LLC a hassle-free solution for those embarking on a long-term adventure in Dubai.
Car Rental Services Tailored for You:
Somonion Rent Car LLC doesn’t just offer cars; it provides a comprehensive range of rental services tailored to suit various occasions. From daily and weekly rentals to airport transfers and business travel, the company ensures that your stay in Dubai is not only comfortable but also exudes prestige. The fleet includes popular models such as the Nissan Altima 2018, KIA Forte 2018, Hyundai Elantra 2018, and the Toyota Camry Sport Edition 2020, all available for monthly rentals at competitive rates.
Featured Deals and Specials:
Somonion Rent Car LLC constantly updates its offerings to provide customers with the best deals. Featured cars like the Hyundai Sonata 2018 and Hyundai Santa Fe 2018 add a touch of luxury to your rental experience, with daily rates starting as low as AED 100. The company’s commitment to affordable luxury is further emphasized by the online booking system, allowing customers to secure the best deals in real-time through their website or by contacting the experts via phone or WhatsApp.
Conclusion:
Whether you’re a tourist looking to explore Dubai at your pace or a business traveler in need of a reliable and prestigious mode of transportation, Somonion Rent Car LLC stands as the go-to choice for monthly car rentals in Dubai. Unlock the ultimate mobility experience with Somonion, where affordability meets excellence, ensuring your journey through Dubai is as seamless and luxurious as the city itself. Contact Somonion Rent Car LLC today and embark on a journey where every mile is a testament to comfort, style, and unmatched service.
buy zithromax online with mastercard can you buy zithromax online zithromax prescription online
http://clomidpharm.shop/# where to get clomid price
prednisone: prednisone no rx – buy prednisone 10mg online
sounds there were in plenty. The soft gurgling
Been relying on them for years, and they never disappoint https://cytotec.directory/# buy cytotec pills online cheap
https://cytotec.directory/# buy cytotec pills online cheap
Their international health advisories are invaluable https://nolvadex.pro/# should i take tamoxifen
zithromax azithromycin: can you buy zithromax over the counter – buy zithromax 1000mg online
https://clomidpharm.shop/# how to get clomid without prescription
http://cytotec.directory/# buy cytotec over the counter
A pharmacy that genuinely cares about community well-being https://clomidpharm.shop/# generic clomid no prescription
how to buy generic clomid without prescription: where can i get clomid prices – get cheap clomid pills
can i buy clomid for sale where to get clomid pills how to get cheap clomid
Good day! This is kind of off topic but I need some guidance
from an established blog. Is it very difficult to
set up your own blog? I’m not very techincal but I can figure things out pretty quick.
I’m thinking about making my own but I’m not sure where to start.
Do you have any ideas or suggestions? Appreciate it
http://clomidpharm.shop/# where buy cheap clomid no prescription
Their health awareness campaigns are so informative https://cytotec.directory/# п»їcytotec pills online
cytotec buy online usa: purchase cytotec – buy misoprostol over the counter
Every visit reaffirms why I choose this pharmacy https://nolvadex.pro/# tamoxifen
https://prednisonepharm.store/# 50 mg prednisone canada pharmacy
娛樂城
2024娛樂城的創新趨勢
隨著2024年的到來,娛樂城業界正經歷著一場革命性的變遷。這一年,娛樂城不僅僅是賭博和娛樂的代名詞,更成為了科技創新和用戶體驗的集大成者。
首先,2024年的娛樂城極大地融合了最新的技術。增強現實(AR)和虛擬現實(VR)技術的引入,為玩家提供了沉浸式的賭博體驗。這種全新的遊戲方式不僅帶來視覺上的震撼,還為玩家創造了一種置身於真實賭場的感覺,而實際上他們可能只是坐在家中的沙發上。
其次,人工智能(AI)在娛樂城中的應用也達到了新高度。AI技術不僅用於增強遊戲的公平性和透明度,還在個性化玩家體驗方面發揮著重要作用。從個性化遊戲推薦到智能客服,AI的應用使得娛樂城更能滿足玩家的個別需求。
此外,線上娛樂城的安全性和隱私保護也獲得了顯著加強。隨著技術的進步,更加先進的加密技術和安全措施被用來保護玩家的資料和交易,從而確保一個安全可靠的遊戲環境。
2024年的娛樂城還強調負責任的賭博。許多平台採用了各種工具和資源來幫助玩家控制他們的賭博行為,如設置賭注限制、自我排除措施等,體現了對可持續賭博的承諾。
總之,2024年的娛樂城呈現出一個高度融合了技術、安全和負責任賭博的行業新面貌,為玩家提供了前所未有的娛樂體驗。隨著這些趨勢的持續發展,我們可以預見,娛樂城將不斷地創新和進步,為玩家帶來更多精彩和安全的娛樂選擇。
Dubai, a city known for its opulence and modernity, demands a mode of transportation that reflects its grandeur. For those seeking a cost-effective and reliable long-term solution, Somonion Rent Car LLC emerges as the premier choice for monthly car rentals in Dubai. With a diverse fleet ranging from compact cars to premium vehicles, the company promises an unmatched blend of affordability, flexibility, and personalized service.
Favorable Rental Conditions:
Understanding the potential financial strain of long-term car rentals, Somonion Rent Car LLC aims to make your journey more economical. The company offers flexible rental terms coupled with exclusive discounts for loyal customers. This commitment to affordability extends beyond the rental cost, as additional services such as insurance, maintenance, and repair ensure your safety and peace of mind throughout the duration of your rental.
A Plethora of Options:
Somonion Rent Car LLC boasts an extensive selection of vehicles to cater to diverse preferences and budgets. Whether you’re in the market for a sleek sedan or a spacious crossover, the company has the perfect car to complement your needs. The transparency in pricing, coupled with the ease of booking through their online platform, makes Somonion Rent Car LLC a hassle-free solution for those embarking on a long-term adventure in Dubai.
Car Rental Services Tailored for You:
Somonion Rent Car LLC doesn’t just offer cars; it provides a comprehensive range of rental services tailored to suit various occasions. From daily and weekly rentals to airport transfers and business travel, the company ensures that your stay in Dubai is not only comfortable but also exudes prestige. The fleet includes popular models such as the Nissan Altima 2018, KIA Forte 2018, Hyundai Elantra 2018, and the Toyota Camry Sport Edition 2020, all available for monthly rentals at competitive rates.
Featured Deals and Specials:
Somonion Rent Car LLC constantly updates its offerings to provide customers with the best deals. Featured cars like the Hyundai Sonata 2018 and Hyundai Santa Fe 2018 add a touch of luxury to your rental experience, with daily rates starting as low as AED 100. The company’s commitment to affordable luxury is further emphasized by the online booking system, allowing customers to secure the best deals in real-time through their website or by contacting the experts via phone or WhatsApp.
Conclusion:
Whether you’re a tourist looking to explore Dubai at your pace or a business traveler in need of a reliable and prestigious mode of transportation, Somonion Rent Car LLC stands as the go-to choice for monthly car rentals in Dubai. Unlock the ultimate mobility experience with Somonion, where affordability meets excellence, ensuring your journey through Dubai is as seamless and luxurious as the city itself. Contact Somonion Rent Car LLC today and embark on a journey where every mile is a testament to comfort, style, and unmatched service.
sildenafil 100 mg tablets sildenafil citrate 100mg levitra 20mg
prednisone 30 mg: buy prednisone online australia – prednisone pill 20 mg
The pharmacists are always updated with the latest in medicine https://nolvadex.pro/# where to buy nolvadex
https://zithromaxpharm.online/# zithromax for sale us
https://clomidpharm.shop/# where to get clomid no prescription
ToԀay, while I was at work, my sister stⲟle my apple
ipad and tested to sеe іif it can survive a forty foot drop, јust so
shе can bbe a youtube sensation. My iPad is now broken and she haаs 83 views.
I know this is completeⅼy off topic but I had too share
it with someone!
buy prednisone 10mg prednisone 2 mg daily generic prednisone tablets
zithromax prescription in canada: where to buy zithromax in canada – how much is zithromax 250 mg
A pharmacy that feels like family http://zithromaxpharm.online/# where can i buy zithromax uk
http://nolvadex.pro/# tamoxifen for sale
canada drugs without perscription reputable canadian pharmacy online online pharmacy with no prescription
https://reputablepharmacies.online/# nabp canadian pharmacy
haste. A large bird had flown in-to her face,
https://reputablepharmacies.online/# canada pharmacy online no script
ed pills for sale: mens ed pills – new ed pills
Thanks for sharing. I read many of your blog posts, cool, your blog is very good. https://www.binance.info/fr/join?ref=V2H9AFPY
levitra without a doctor prescription real viagra without a doctor prescription cialis without a doctor’s prescription
https://edpills.bid/# pills for ed
Watches World
Watches World: Elevating Luxury and Style with Exquisite Timepieces
Introduction:
Jewelry has always been a timeless expression of elegance, and nothing complements one’s style better than a luxurious timepiece. At Watches World, we bring you an exclusive collection of coveted luxury watches that not only tell time but also serve as a testament to your refined taste. Explore our curated selection featuring iconic brands like Rolex, Hublot, Omega, Cartier, and more, as we redefine the art of accessorizing.
A Dazzling Array of Luxury Watches:
Watches World offers an unparalleled range of exquisite timepieces from renowned brands, ensuring that you find the perfect accessory to elevate your style. Whether you’re drawn to the classic sophistication of Rolex, the avant-garde designs of Hublot, or the precision engineering of Patek Philippe, our collection caters to diverse preferences.
Customer Testimonials:
Our commitment to providing an exceptional customer experience is reflected in the reviews from our satisfied clientele. O.M. commends our excellent communication and flawless packaging, while Richard Houtman appreciates the helpfulness and courtesy of our team. These testimonials highlight our dedication to transparency, communication, and customer satisfaction.
New Arrivals:
Stay ahead of the curve with our latest additions, including the Tudor Black Bay Ceramic 41mm, Richard Mille RM35-01 Rafael Nadal NTPT Carbon Limited Edition, and the Rolex Oyster Perpetual Datejust 41mm series. These new arrivals showcase cutting-edge designs and impeccable craftsmanship, ensuring you stay on the forefront of luxury watch fashion.
Best Sellers:
Discover our best-selling watches, such as the Bulgari Serpenti Tubogas 35mm and the Cartier Panthere Medium Model. These timeless pieces combine elegance with precision, making them a staple in any sophisticated wardrobe.
Expert’s Selection:
Our experts have carefully curated a selection of watches, including the Cartier Panthere Small Model, Omega Speedmaster Moonwatch 44.25 mm, and Rolex Oyster Perpetual Cosmograph Daytona 40mm. These choices exemplify the epitome of watchmaking excellence and style.
Secured and Tracked Delivery:
At Watches World, we prioritize the safety of your purchase. Our secured and tracked delivery ensures that your exquisite timepiece reaches you in perfect condition, giving you peace of mind with every order.
Passionate Experts at Your Service:
Our team of passionate watch experts is dedicated to providing personalized service. From assisting you in choosing the perfect timepiece to addressing any inquiries, we are here to make your watch-buying experience seamless and enjoyable.
Global Presence:
With a presence in key cities around the world, including Dubai, Geneva, Hong Kong, London, Miami, Paris, Prague, Dublin, Singapore, and Sao Paulo, Watches World brings luxury timepieces to enthusiasts globally.
Conclusion:
Watches World goes beyond being an online platform for luxury watches; it is a destination where expertise, trust, and satisfaction converge. Explore our collection, and let our timeless timepieces become an integral part of your style narrative. Join us in redefining luxury, one exquisite watch at a time.
Dubai, a city of grandeur and innovation, demands a transportation solution that matches its dynamic pace. Whether you’re a business executive, a tourist exploring the city, or someone in need of a reliable vehicle temporarily, car rental services in Dubai offer a flexible and cost-effective solution. In this guide, we’ll explore the popular car rental options in Dubai, catering to diverse needs and preferences.
Airport Car Rental: One-Way Pickup and Drop-off Road Trip Rentals:
For those who need to meet an important delegation at the airport or have a flight to another city, airport car rentals provide a seamless solution. Avoid the hassle of relying on public transport and ensure you reach your destination on time. With one-way pickup and drop-off options, you can effortlessly navigate your road trip, making business meetings or conferences immediately upon arrival.
Business Car Rental Deals & Corporate Vehicle Rentals in Dubai:
Companies without their own fleet or those finding transport maintenance too expensive can benefit from business car rental deals. This option is particularly suitable for businesses where a vehicle is needed only occasionally. By opting for corporate vehicle rentals, companies can optimize their staff structure, freeing employees from non-core functions while ensuring reliable transportation when necessary.
Tourist Car Rentals with Insurance in Dubai:
Tourists visiting Dubai can enjoy the freedom of exploring the city at their own pace with car rentals that come with insurance. This option allows travelers to choose a vehicle that suits the particulars of their trip without the hassle of dealing with insurance policies. Renting a car not only saves money and time compared to expensive city taxis but also ensures a trouble-free travel experience.
Daily Car Hire Near Me:
Daily car rental services are a convenient and cost-effective alternative to taxis in Dubai. Whether it’s for a business meeting, everyday use, or a luxury experience, you can find a suitable vehicle for a day on platforms like Smarketdrive.com. The website provides a secure and quick way to rent a car from certified and verified car rental companies, ensuring guarantees and safety.
Weekly Auto Rental Deals:
For those looking for flexibility throughout the week, weekly car rentals in Dubai offer a competent, attentive, and professional service. Whether you need a vehicle for a few days or an entire week, choosing a car rental weekly is a convenient and profitable option. The certified and tested car rental companies listed on Smarketdrive.com ensure a reliable and comfortable experience.
Monthly Car Rentals in Dubai:
When your personal car is undergoing extended repairs, or if you’re a frequent visitor to Dubai, monthly car rentals (long-term car rentals) become the ideal solution. Residents, businessmen, and tourists can benefit from the extensive options available on Smarketdrive.com, ensuring mobility and convenience throughout their stay in Dubai.
FAQ about Renting a Car in Dubai:
To address common queries about renting a car in Dubai, our FAQ section provides valuable insights and information. From rental terms to insurance coverage, it serves as a comprehensive guide for those considering the convenience of car rentals in the bustling city.
Conclusion:
Dubai’s popularity as a global destination is matched by its diverse and convenient car rental services. Whether for business, tourism, or daily commuting, the options available cater to every need. With reliable platforms like Smarketdrive.com, navigating Dubai becomes a seamless and enjoyable experience, offering both locals and visitors the ultimate freedom of mobility.
discount prescription drugs: buy prescription drugs from india – best non prescription ed pills
discount drugs online http://edpills.bid/# men’s ed pills
cheapest viagra canadian pharmacy
canadian world pharmacy buy medicine canada certified online canadian pharmacies
Dubai, a city known for its opulence and modernity, demands a mode of transportation that reflects its grandeur. For those seeking a cost-effective and reliable long-term solution, Somonion Rent Car LLC emerges as the premier choice for monthly car rentals in Dubai. With a diverse fleet ranging from compact cars to premium vehicles, the company promises an unmatched blend of affordability, flexibility, and personalized service.
Favorable Rental Conditions:
Understanding the potential financial strain of long-term car rentals, Somonion Rent Car LLC aims to make your journey more economical. The company offers flexible rental terms coupled with exclusive discounts for loyal customers. This commitment to affordability extends beyond the rental cost, as additional services such as insurance, maintenance, and repair ensure your safety and peace of mind throughout the duration of your rental.
A Plethora of Options:
Somonion Rent Car LLC boasts an extensive selection of vehicles to cater to diverse preferences and budgets. Whether you’re in the market for a sleek sedan or a spacious crossover, the company has the perfect car to complement your needs. The transparency in pricing, coupled with the ease of booking through their online platform, makes Somonion Rent Car LLC a hassle-free solution for those embarking on a long-term adventure in Dubai.
Car Rental Services Tailored for You:
Somonion Rent Car LLC doesn’t just offer cars; it provides a comprehensive range of rental services tailored to suit various occasions. From daily and weekly rentals to airport transfers and business travel, the company ensures that your stay in Dubai is not only comfortable but also exudes prestige. The fleet includes popular models such as the Nissan Altima 2018, KIA Forte 2018, Hyundai Elantra 2018, and the Toyota Camry Sport Edition 2020, all available for monthly rentals at competitive rates.
Featured Deals and Specials:
Somonion Rent Car LLC constantly updates its offerings to provide customers with the best deals. Featured cars like the Hyundai Sonata 2018 and Hyundai Santa Fe 2018 add a touch of luxury to your rental experience, with daily rates starting as low as AED 100. The company’s commitment to affordable luxury is further emphasized by the online booking system, allowing customers to secure the best deals in real-time through their website or by contacting the experts via phone or WhatsApp.
Conclusion:
Whether you’re a tourist looking to explore Dubai at your pace or a business traveler in need of a reliable and prestigious mode of transportation, Somonion Rent Car LLC stands as the go-to choice for monthly car rentals in Dubai. Unlock the ultimate mobility experience with Somonion, where affordability meets excellence, ensuring your journey through Dubai is as seamless and luxurious as the city itself. Contact Somonion Rent Car LLC today and embark on a journey where every mile is a testament to comfort, style, and unmatched service.
canada prescription: non prescription – trust online pharmacies
Thanks , I have recently been looking for information approximately this topic for a while and yours is
the best I have found out so far. However, what concerning the bottom line?
Are you sure concerning the supply?
When some one searches for his necessary thing, therefore he/she needs to be available that in detail, thus that thing is maintained over here.
Watches World: Elevating Luxury and Style with Exquisite Timepieces
Introduction:
Jewelry has always been a timeless expression of elegance, and nothing complements one’s style better than a luxurious timepiece. At Watches World, we bring you an exclusive collection of coveted luxury watches that not only tell time but also serve as a testament to your refined taste. Explore our curated selection featuring iconic brands like Rolex, Hublot, Omega, Cartier, and more, as we redefine the art of accessorizing.
A Dazzling Array of Luxury Watches:
Watches World offers an unparalleled range of exquisite timepieces from renowned brands, ensuring that you find the perfect accessory to elevate your style. Whether you’re drawn to the classic sophistication of Rolex, the avant-garde designs of Hublot, or the precision engineering of Patek Philippe, our collection caters to diverse preferences.
Customer Testimonials:
Our commitment to providing an exceptional customer experience is reflected in the reviews from our satisfied clientele. O.M. commends our excellent communication and flawless packaging, while Richard Houtman appreciates the helpfulness and courtesy of our team. These testimonials highlight our dedication to transparency, communication, and customer satisfaction.
New Arrivals:
Stay ahead of the curve with our latest additions, including the Tudor Black Bay Ceramic 41mm, Richard Mille RM35-01 Rafael Nadal NTPT Carbon Limited Edition, and the Rolex Oyster Perpetual Datejust 41mm series. These new arrivals showcase cutting-edge designs and impeccable craftsmanship, ensuring you stay on the forefront of luxury watch fashion.
Best Sellers:
Discover our best-selling watches, such as the Bulgari Serpenti Tubogas 35mm and the Cartier Panthere Medium Model. These timeless pieces combine elegance with precision, making them a staple in any sophisticated wardrobe.
Expert’s Selection:
Our experts have carefully curated a selection of watches, including the Cartier Panthere Small Model, Omega Speedmaster Moonwatch 44.25 mm, and Rolex Oyster Perpetual Cosmograph Daytona 40mm. These choices exemplify the epitome of watchmaking excellence and style.
Secured and Tracked Delivery:
At Watches World, we prioritize the safety of your purchase. Our secured and tracked delivery ensures that your exquisite timepiece reaches you in perfect condition, giving you peace of mind with every order.
Passionate Experts at Your Service:
Our team of passionate watch experts is dedicated to providing personalized service. From assisting you in choosing the perfect timepiece to addressing any inquiries, we are here to make your watch-buying experience seamless and enjoyable.
Global Presence:
With a presence in key cities around the world, including Dubai, Geneva, Hong Kong, London, Miami, Paris, Prague, Dublin, Singapore, and Sao Paulo, Watches World brings luxury timepieces to enthusiasts globally.
Conclusion:
Watches World goes beyond being an online platform for luxury watches; it is a destination where expertise, trust, and satisfaction converge. Explore our collection, and let our timeless timepieces become an integral part of your style narrative. Join us in redefining luxury, one exquisite watch at a time.
Its like you read my mind! You appear to know so much about this, like you
wrote the book in it or something. I think that you could do with a few pics to drive the message home a little bit,
but instead of that, this is magnificent blog. A fantastic read.
I will certainly be back.
Hello there I am so glad I found your website, I really found you
by accident, while I was researching on Digg for something else, Anyways I am
here now and would just like to say thanks a lot for a tremendous post and a all round interesting
blog (I also love the theme/design), I don’t have time to
read it all at the minute but I have book-marked it and also
included your RSS feeds, so when I have time I will be back to read a lot more, Please do keep up
the excellent job.
Inplay casino
I think the admin of this website is genuinely working hard in favor of his website, since here every stuff is quality based information.
Good article. I absolutely appreciate this site. Stick
with it!
Hi great website! Does running a blog similar to this require a lot of work?
I’ve virtually no expertise in programming however I had been hoping to start my
own blog soon. Anyway, should you have any ideas or
techniques for new blog owners please share.
I know this is off subject nevertheless I simply wanted to ask.
Cheers!
Excellent post. Keep writing such kind of information on your page.
Im really impressed by your site.
Hello there, You’ve performed a fantastic job. I will definitely digg it and individually
recommend to my friends. I am confident they will be benefited from this site.
https://edwithoutdoctorprescription.store/# ed meds online without doctor prescription
My brother suggested I might like this website. He was once entirely right.
This put up truly made my day. You cann’t believe
simply how a lot time I had spent for this information! Thank you!
cures for ed: medicine for erectile – ed drugs
canada rx pharmacy legitimate mexican pharmacy online best online pharmacies without prescription
https://edwithoutdoctorprescription.store/# cialis without doctor prescription
medicine for impotence erectile dysfunction drug cheap erectile dysfunction pill
http://reputablepharmacies.online/# cheap medications
non prescription ed pills: natural remedies for ed – ed pills otc
reliable mexican pharmacies https://edpills.bid/# cheapest ed pills
canada pharmacy estrogen without prescription
generic ed pills ed dysfunction treatment treatment for ed
ed treatment drugs: erection pills that work – cheap erectile dysfunction pills online
http://edwithoutdoctorprescription.store/# ed meds online without doctor prescription
online pharmacy no prescriptions: mexican pharmacies that ship – non prescription
cheap erectile dysfunction pills ed dysfunction treatment otc ed pills
Heey There. I founbd your blog using msn. Thhis is an extremely well written article.
I’ll make sure to bookmark iit and cme back to read more
of your usefl info. Thanks for the post. I will certainly comeback.
best ed pills non prescription: tadalafil without a doctor’s prescription – prescription drugs online without
sildenafil citrate tablets
http://reputablepharmacies.online/# canadian pharmacy no prescription needed
Valuable info. Fortunate me I discovered your website by chance, and I’m stunned why this coincidence didn’t happened in advance!
I bookmarked it.
buy cheap prescription drugs online viagra without doctor prescription amazon prescription drugs without prior prescription
http://reputablepharmacies.online/# trust pharmacy
I’m really enjoying the design and layout of your website. It’s a very
easy on the eyes which makes it much more enjoyable
for me to come here and visit more often. Did you hire out a developer to create your theme?
Excellent work!
I’m not sure why but this website is loading extremely slow for me.
Is anyone else having this problem or is it a issue on my end?
I’ll check back later and see if the problem still exists.
I do not even know how I stopped up right here, however I assumed this put up used to be good.
I don’t recognize who you are however certainly you are going to a well-known blogger if you happen to are not already.
Cheers!
Thank you, I’ve just been looking for info about this subject for ages and
yours is the greatest I have came upon till now.
But, what in regards to the conclusion? Are you certain concerning
the supply?
Nice post. I learn something new and challenging on blogs I stumbleupon every day.
It’s always interesting to read through articles from other writers and practice a little
something from other websites.
Currently it looks like Drupal is the best blogging platform available right now.
(from what I’ve read) Is that what you’re using on your blog?
real viagra without a doctor prescription usa: buy prescription drugs from canada – non prescription ed drugs
most reputable canadian pharmacies online pharmacies reviews canadian drug mart pharmacy
Pingback: 39 Greatest Cam Websites Of 2022 Adult Cam Girl Shows On-line
https://edwithoutdoctorprescription.store/# prescription drugs without doctor approval
prescription without a doctor’s prescription: buy cheap prescription drugs online – legal to buy prescription drugs from canada
indian pharmacy paypal Order medicine from India to USA pharmacy website india indianpharmacy.shop
mzpro register
mzpro login
mzpro daftar
buat duit online
buat duit guna handphone
mzpro trusted 2024
https://mexicanpharmacy.win/# buying from online mexican pharmacy mexicanpharmacy.win
https://canadianpharmacy.pro/# recommended canadian pharmacies canadianpharmacy.pro
canadian pharmacy 365: Canada Pharmacy – best canadian pharmacy online canadianpharmacy.pro
https://canadianpharmacy.pro/# canada drug pharmacy canadianpharmacy.pro
prescription drugs without doctor
india pharmacy mail order Order medicine from India to USA online shopping pharmacy india indianpharmacy.shop
Pingback: child porn
https://mexicanpharmacy.win/# buying prescription drugs in mexico mexicanpharmacy.win
buying prescription drugs in mexico: online mexican pharmacy – mexico pharmacy mexicanpharmacy.win
canadian pharmacy price checker Canadian pharmacy online canadianpharmacyworld canadianpharmacy.pro
Keep on working, great job!
This piece of writing will help the internet people for
setting up new web site or even a blog from start to end.
Oh my goodness! Impressive article dude! Many thanks, However I am going
through problems with your RSS. I don’t know why I can’t subscribe
to it. Is there anybody getting identical RSS problems?
Anyone that knows the answer will you kindly respond? Thanks!!
This is the right web site for everyone who would like to find out
about this topic. You understand so much its
almost hard to argue with you (not that I really would want to…HaHa).
You definitely put a brand new spin on a topic that’s been written about for years.
Great stuff, just excellent!
Nice post. I was checking constantly this blog and I am impressed!
Extremely useful info particularly the last part 🙂 I care for such info much.
I was seeking this particular information for a very
long time. Thank you and good luck.
https://indianpharmacy.shop/# world pharmacy india indianpharmacy.shop
mexican border pharmacies shipping to usa: Medicines Mexico – mexican drugstore online mexicanpharmacy.win
buying drugs from canada Canada Pharmacy pharmacy canadian superstore canadianpharmacy.pro
https://canadianpharmacy.pro/# canadian pharmacy canadianpharmacy.pro
https://mexicanpharmacy.win/# medicine in mexico pharmacies mexicanpharmacy.win
canadian drug pharmacy
http://mexicanpharmacy.win/# mexico drug stores pharmacies mexicanpharmacy.win
buy medicines online in india international medicine delivery from india india online pharmacy indianpharmacy.shop
http://canadianpharmacy.pro/# pet meds without vet prescription canada canadianpharmacy.pro
п»їbest mexican online pharmacies mexican pharmacy online mexico drug stores pharmacies mexicanpharmacy.win
tadalafil 60mg
https://indianpharmacy.shop/# reputable indian pharmacies indianpharmacy.shop
cheapest online pharmacy india
https://mexicanpharmacy.win/# buying prescription drugs in mexico mexicanpharmacy.win
mexican mail order pharmacies mexican pharmacy online п»їbest mexican online pharmacies mexicanpharmacy.win
戰神賽特老虎機
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
2024娛樂城No.1 – 富遊娛樂城介紹
2024 年 1 月 5 日
|
娛樂城, 現金版娛樂城
富遊娛樂城是無論老手、新手,都非常推薦的線上博奕,在2024娛樂城當中扮演著多年來最來勢洶洶的一匹黑馬,『人性化且精緻的介面,遊戲種類眾多,超級多的娛樂城優惠,擁有眾多與會員交流遊戲的群組』是一大特色。
富遊娛樂城擁有歐洲馬爾他(MGA)和菲律賓政府競猜委員會(PAGCOR)頒發的合法執照。
註冊於英屬維爾京群島,受國際行業協會認可的合法公司。
我們的中心思想就是能夠帶領玩家遠詐騙黑網,讓大家安心放心的暢玩線上博弈,娛樂城也受各大部落客、IG網紅、PTT論壇,推薦討論,富遊娛樂城沒有之一,絕對是線上賭場玩家的第一首選!
富遊娛樂城介面 / 2024娛樂城NO.1
富遊娛樂城簡介
品牌名稱 : 富遊RG
創立時間 : 2019年
存款速度 : 平均15秒
提款速度 : 平均5分
單筆提款金額 : 最低1000-100萬
遊戲對象 : 18歲以上男女老少皆可
合作廠商 : 22家遊戲平台商
支付平台 : 各大銀行、各大便利超商
支援配備 : 手機網頁、電腦網頁、IOS、安卓(Android)
富遊娛樂城遊戲品牌
真人百家 — 歐博真人、DG真人、亞博真人、SA真人、OG真人
體育投注 — SUPER體育、鑫寶體育、亞博體育
電競遊戲 — 泛亞電競
彩票遊戲 — 富遊彩票、WIN 539
電子遊戲 —ZG電子、BNG電子、BWIN電子、RSG電子、好路GR電子
棋牌遊戲 —ZG棋牌、亞博棋牌、好路棋牌、博亞棋牌
捕魚遊戲 —ZG捕魚、RSG捕魚、好路GR捕魚、亞博捕魚
富遊娛樂城優惠活動
每日任務簽到金666
富遊VIP全面啟動
復酬金活動10%優惠
日日返水
新會員好禮五選一
首存禮1000送1000
免費體驗金$168
富遊娛樂城APP
步驟1 : 開啟網頁版【富遊娛樂城官網】
步驟2 : 點選上方(下載app),會跳出下載與複製連結選項,點選後跳轉。
步驟3 : 跳轉後點選(安裝),並點選(允許)操作下載描述檔,跳出下載描述檔後點選關閉。
步驟4 : 到手機設置>一般>裝置管理>設定描述檔(富遊)安裝,即可完成安裝。
富遊娛樂城常見問題FAQ
富遊娛樂城詐騙?
黑網詐騙可細分兩種,小出大不出及純詐騙黑網,我們可從品牌知名度經營和網站架設畫面分辨來簡單分辨。
富遊娛樂城會出金嗎?
如上面提到,富遊是在做一個品牌,為的是能夠保證出金,和帶領玩家遠離黑網,而且還有DUKER娛樂城出金認證,所以各位能夠放心富遊娛樂城為正出金娛樂城。
富遊娛樂城出金延遲怎麼辦?
基本上只要是公司系統問提造成富遊娛樂城會員無法在30分鐘成功提款,富遊娛樂城會即刻派送補償金,表達誠摯的歉意。
富遊娛樂城結論
富遊娛樂城安心玩,評價4.5顆星。如果還想看其他娛樂城推薦的,可以來娛樂城推薦尋找喔。
It’s going to be ending of mine day, except before end I am reading this impressive piece of writing
to increase my experience.
http://indianpharmacy.shop/# reputable indian online pharmacy indianpharmacy.shop
ATG戰神賽特
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
https://indianpharmacy.shop/# reputable indian pharmacies indianpharmacy.shop
best india pharmacy
http://mexicanpharmacy.win/# mexico pharmacies prescription drugs mexicanpharmacy.win
india pharmacy mail order india online pharmacy cheapest online pharmacy india indianpharmacy.shop
https://canadianpharmacy.pro/# canadapharmacyonline legit canadianpharmacy.pro
canadian prescription filled in the us
http://indianpharmacy.shop/# india online pharmacy indianpharmacy.shop
online shopping pharmacy india
reputable indian pharmacies indian pharmacy to usa top 10 pharmacies in india indianpharmacy.shop
https://mexicanpharmacy.win/# reputable mexican pharmacies online mexicanpharmacy.win
india pharmacy
https://indianpharmacy.shop/# buy medicines online in india indianpharmacy.shop
mail order drug store
https://mexicanpharmacy.win/# mexican pharmaceuticals online mexicanpharmacy.win
http://indianpharmacy.shop/# pharmacy website india indianpharmacy.shop
mexican pharmaceuticals online Mexico pharmacy mexican rx online mexicanpharmacy.win
Very quickly this site will be famous among all blog visitors,
due to it’s nice articles
https://canadianpharmacy.pro/# canadian pharmacy world canadianpharmacy.pro
indian pharmacies safe
http://canadianpharmacy.pro/# canadian pharmacy online canadianpharmacy.pro
the canadian pharmacy Pharmacies in Canada that ship to the US my canadian pharmacy canadianpharmacy.pro
2024娛樂城
2024娛樂城No.1 – 富遊娛樂城介紹
2024 年 1 月 5 日
|
娛樂城, 現金版娛樂城
富遊娛樂城是無論老手、新手,都非常推薦的線上博奕,在2024娛樂城當中扮演著多年來最來勢洶洶的一匹黑馬,『人性化且精緻的介面,遊戲種類眾多,超級多的娛樂城優惠,擁有眾多與會員交流遊戲的群組』是一大特色。
富遊娛樂城擁有歐洲馬爾他(MGA)和菲律賓政府競猜委員會(PAGCOR)頒發的合法執照。
註冊於英屬維爾京群島,受國際行業協會認可的合法公司。
我們的中心思想就是能夠帶領玩家遠詐騙黑網,讓大家安心放心的暢玩線上博弈,娛樂城也受各大部落客、IG網紅、PTT論壇,推薦討論,富遊娛樂城沒有之一,絕對是線上賭場玩家的第一首選!
富遊娛樂城介面 / 2024娛樂城NO.1
富遊娛樂城簡介
品牌名稱 : 富遊RG
創立時間 : 2019年
存款速度 : 平均15秒
提款速度 : 平均5分
單筆提款金額 : 最低1000-100萬
遊戲對象 : 18歲以上男女老少皆可
合作廠商 : 22家遊戲平台商
支付平台 : 各大銀行、各大便利超商
支援配備 : 手機網頁、電腦網頁、IOS、安卓(Android)
富遊娛樂城遊戲品牌
真人百家 — 歐博真人、DG真人、亞博真人、SA真人、OG真人
體育投注 — SUPER體育、鑫寶體育、亞博體育
電競遊戲 — 泛亞電競
彩票遊戲 — 富遊彩票、WIN 539
電子遊戲 —ZG電子、BNG電子、BWIN電子、RSG電子、好路GR電子
棋牌遊戲 —ZG棋牌、亞博棋牌、好路棋牌、博亞棋牌
捕魚遊戲 —ZG捕魚、RSG捕魚、好路GR捕魚、亞博捕魚
富遊娛樂城優惠活動
每日任務簽到金666
富遊VIP全面啟動
復酬金活動10%優惠
日日返水
新會員好禮五選一
首存禮1000送1000
免費體驗金$168
富遊娛樂城APP
步驟1 : 開啟網頁版【富遊娛樂城官網】
步驟2 : 點選上方(下載app),會跳出下載與複製連結選項,點選後跳轉。
步驟3 : 跳轉後點選(安裝),並點選(允許)操作下載描述檔,跳出下載描述檔後點選關閉。
步驟4 : 到手機設置>一般>裝置管理>設定描述檔(富遊)安裝,即可完成安裝。
富遊娛樂城常見問題FAQ
富遊娛樂城詐騙?
黑網詐騙可細分兩種,小出大不出及純詐騙黑網,我們可從品牌知名度經營和網站架設畫面分辨來簡單分辨。
富遊娛樂城會出金嗎?
如上面提到,富遊是在做一個品牌,為的是能夠保證出金,和帶領玩家遠離黑網,而且還有DUKER娛樂城出金認證,所以各位能夠放心富遊娛樂城為正出金娛樂城。
富遊娛樂城出金延遲怎麼辦?
基本上只要是公司系統問提造成富遊娛樂城會員無法在30分鐘成功提款,富遊娛樂城會即刻派送補償金,表達誠摯的歉意。
富遊娛樂城結論
富遊娛樂城安心玩,評價4.5顆星。如果還想看其他娛樂城推薦的,可以來娛樂城推薦尋找喔。
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
https://canadianpharmacy.pro/# onlinecanadianpharmacy 24 canadianpharmacy.pro
india pharmacy mail order
https://mexicanpharmacy.win/# mexico pharmacy mexicanpharmacy.win
reputable indian pharmacies indian pharmacy to usa indian pharmacy paypal indianpharmacy.shop
Helpful material. Cheers.
ШЇШ§Щ†Щ„Щ€ШЇ bc game bc game crash predictor bc rutgers game
Pharmacie en ligne sans ordonnance Pharmacie en ligne livraison gratuite Pharmacies en ligne certifiГ©es
п»їpharmacie en ligne: acheterkamagra.pro – Pharmacies en ligne certifiГ©es
http://acheterkamagra.pro/# pharmacie ouverte 24/24
Appreciate the recommendation. Let me try it out.
https://rg8888.org/atg/
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
It’s going to be end of mine day, except before finish I am reading this great article
to increase my knowledge.
п»їpharmacie en ligne cialissansordonnance.shop Pharmacie en ligne sans ordonnance
pharmacie ouverte: Levitra acheter – п»їpharmacie en ligne
https://viagrasansordonnance.pro/# SildГ©nafil 100 mg prix en pharmacie en France
Pharmacie en ligne livraison 24h
http://cialissansordonnance.shop/# pharmacie ouverte
Pingback: child porn
Acheter mГ©dicaments sans ordonnance sur internet: levitra generique – pharmacie ouverte 24/24
Viagra vente libre pays viagra sans ordonnance Viagra homme prix en pharmacie sans ordonnance
SildГ©nafil 100 mg sans ordonnance: Viagra generique en pharmacie – SildГ©nafil 100 mg sans ordonnance
https://acheterkamagra.pro/# pharmacie ouverte 24/24
acheter medicament a l etranger sans ordonnance: kamagra 100mg prix – Pharmacie en ligne pas cher
https://viagrasansordonnance.pro/# Viagra prix pharmacie paris
Thank you for another informative web site. Where else may I am getting that kind
of info written in such a perfect means? I have a undertaking that I’m simply
now running on, and I’ve been at the glance out for such info.
Pharmacies en ligne certifiГ©es: cialissansordonnance.shop – pharmacie ouverte
https://levitrasansordonnance.pro/# Pharmacie en ligne fiable
Pharmacie en ligne sans ordonnance
https://viagrasansordonnance.pro/# Viagra sans ordonnance 24h
Viagra sans ordonnance livraison 24h: Acheter du Viagra sans ordonnance – Viagra homme prix en pharmacie sans ordonnance
Pharmacie en ligne livraison rapide: levitra generique – acheter medicament a l etranger sans ordonnance
Pharmacie en ligne livraison rapide cialis prix Acheter mГ©dicaments sans ordonnance sur internet
http://acheterkamagra.pro/# Pharmacie en ligne pas cher
Дома АВС – Ваш уютный уголок
Мы строим не просто дома, мы создаем пространство, где каждый уголок будет наполнен комфортом и радостью жизни. Наш приоритет – не просто предоставить место для проживания, а создать настоящий дом, где вы будете чувствовать себя счастливыми и уютно.
В нашем информационном разделе “ПРОЕКТЫ” вы всегда найдете вдохновение и новые идеи для строительства вашего будущего дома. Мы постоянно работаем над тем, чтобы предложить вам самые инновационные и стильные проекты.
Мы убеждены, что основа хорошего дома – это его дизайн. Поэтому мы предоставляем услуги опытных дизайнеров-архитекторов, которые помогут вам воплотить все ваши идеи в жизнь. Наши архитекторы и персональные консультанты всегда готовы поделиться своим опытом и предложить функциональные и комфортные решения для вашего будущего дома.
Мы стремимся сделать весь процесс строительства максимально комфортным для вас. Наша команда предоставляет детализированные сметы, разрабатывает четкие этапы строительства и осуществляет контроль качества на каждом этапе.
Для тех, кто ценит экологичность и близость к природе, мы предлагаем деревянные дома премиум-класса. Используя клееный брус и оцилиндрованное бревно, мы создаем уникальные и здоровые условия для вашего проживания.
Тем, кто предпочитает надежность и многообразие форм, мы предлагаем дома из камня, блоков и кирпичной кладки.
Для практичных и ценящих свое время людей у нас есть быстровозводимые каркасные дома и эконом-класса. Эти решения обеспечат вас комфортным проживанием в кратчайшие сроки.
С Домами АВС создайте свой уютный уголок, где каждый момент жизни будет наполнен радостью и удовлетворением
pharmacie ouverte 24/24: levitra generique sites surs – Pharmacie en ligne fiable
Pharmacie en ligne livraison gratuite Levitra pharmacie en ligne Pharmacie en ligne France
Local Insider information
https://viagrasansordonnance.pro/# Viagra homme prix en pharmacie sans ordonnance
戰神賽特
2024全新上線❰戰神賽特老虎機❱ – ATG賽特玩法說明介紹
❰戰神賽特老虎機❱是由ATG電子獨家開發的古埃及風格線上老虎機,在傳說中戰神賽特是「力量之神」與奈芙蒂斯女神結成連理,共同守護古埃及的奇幻秘寶,只有被選中的冒險者才能進入探險。
❰戰神賽特老虎機❱ – ATG賽特介紹
2024最新老虎機【戰神塞特】- ATG電子 X 富遊娛樂城
❰戰神賽特老虎機❱ – ATG電子
線上老虎機系統 : ATG電子
發行年分 : 2024年1月
最大倍數 : 51000倍
返還率 : 95.89%
支付方式 : 全盤倍數、消除掉落
最低投注金額 : 0.4元
最高投注金額 : 2000元
可否選台 : 是
可選台台數 : 350台
免費遊戲 : 選轉觸發+購買特色
❰戰神賽特老虎機❱ 賠率說明
戰神塞特老虎機賠率算法非常簡單,玩家們只需要不斷的轉動老虎機,成功消除物件即可贏分,得分賠率依賠率表計算。
當盤面上沒有物件可以消除時,倍數符號將會相加形成總倍數!該次旋轉的總贏分即為 : 贏分 X 總倍數。
積分方式如下 :
贏分=(單次押注額/20) X 物件賠率
EX : 單次押注額為1,盤面獲得12個戰神賽特倍數符號法老魔眼
贏分= (1/20) X 1000=50
以下為各個得分符號數量之獎金賠率 :
得分符號 獎金倍數 得分符號 獎金倍數
戰神賽特倍數符號聖甲蟲 6 2000
5 100
4 60 戰神賽特倍數符號黃寶石 12+ 200
10-11 30
8-9 20
戰神賽特倍數符號荷魯斯之眼 12+ 1000
10-11 500
8-9 200 戰神賽特倍數符號紅寶石 12+ 160
10-11 24
8-9 16
戰神賽特倍數符號眼鏡蛇 12+ 500
10-11 200
8-9 50 戰神賽特倍數符號紫鑽石 12+ 100
10-11 20
8-9 10
戰神賽特倍數符號神箭 12+ 300
10-11 100
8-9 40 戰神賽特倍數符號藍寶石 12+ 80
10-11 18
8-9 8
戰神賽特倍數符號屠鐮刀 12+ 240
10-11 40
8-9 30 戰神賽特倍數符號綠寶石 12+ 40
10-11 15
8-9 5
❰戰神賽特老虎機❱ 賠率說明(橘色數值為獲得數量、黑色數值為得分賠率)
ATG賽特 – 特色說明
ATG賽特 – 倍數符號獎金加乘
玩家們在看到盤面上出現倍數符號時,務必把握機會加速轉動ATG賽特老虎機,倍數符號會隨機出現2到500倍的隨機倍數。
當盤面無法在消除時,這些倍數總和會相加,乘上當時累積之獎金,即為最後得分總額。
倍數符號會出現在主遊戲和免費遊戲當中,玩家們千萬別錯過這個可以瞬間將得獎金額拉高的好機會!
ATG賽特 – 倍數符號獎金加乘
ATG賽特 – 倍數符號圖示
ATG賽特 – 進入神秘金字塔開啟免費遊戲
戰神賽特倍數符號聖甲蟲
❰戰神賽特老虎機❱ 免費遊戲符號
在古埃及神話中,聖甲蟲又稱為「死亡之蟲」,它被當成了天球及重生的象徵,守護古埃及的奇幻秘寶。
當玩家在盤面上,看見越來越多的聖甲蟲時,千萬不要膽怯,只需在牌面上斬殺4~6個ATG賽特免費遊戲符號,就可以進入15場免費遊戲!
在免費遊戲中若轉出3~6個聖甲蟲免費遊戲符號,可額外獲得5次免費遊戲,最高可達100次。
當玩家的累積贏分且盤面有倍數物件時,盤面上的所有倍數將會加入總倍數!
ATG賽特 – 選台模式贏在起跑線
為避免神聖的寶物被盜墓者奪走,富有智慧的法老王將金子塔內佈滿迷宮,有的設滿機關讓盜墓者寸步難行,有的暗藏機關可以直接前往存放神秘寶物的暗房。
ATG賽特老虎機設有350個機檯供玩家選擇,這是連魔龍老虎機、忍老虎機都給不出的機台數量,為的就是讓玩家,可以隨時進入神秘的古埃及的寶藏聖域,挖掘長眠已久的神祕寶藏。
【戰神塞特老虎機】選台模式
❰戰神賽特老虎機❱ 選台模式
ATG賽特 – 購買免費遊戲挖掘秘寶
玩家們可以使用當前投注額的100倍購買免費遊戲!進入免費遊戲再也不是虛幻。獎勵與一般遊戲相同,且購買後遊戲將自動開始,直到場次和獎金發放完畢為止。
有購買免費遊戲需求的玩家們,立即點擊「開始」,啟動神秘金字塔裡的古埃及祕寶吧!
【戰神塞特老虎機】購買特色
❰戰神賽特老虎機❱ 購買特色
戰神賽特試玩推薦
看完了❰戰神賽特老虎機❱介紹之後,玩家們是否也蓄勢待發要進入古埃及的世界,一探神奇秘寶探險之旅。
本次ATG賽特與線上娛樂城推薦第一名的富遊娛樂城合作,只需要加入會員,即可領取到168體驗金,免費試玩420轉!
Hey There. I found your blog using msn. This is an extremely well written article.
I’ll be sure to bookmark it and return to read more of
your useful information. Thanks for the post. I will certainly return.
can you buy zithromax over the counter: where can i buy zithromax uk – where can i buy zithromax uk
hbo max watch party is a browser extension that lets you watch HBO with friends & family even if you’re far apart. It syncs video playback, group chat, and even video and audio call features. It’s your go-to for long-distance movie nights with loved ones.
Add to chrome:- hbo max watch party
can i get cheap clomid without insurance: cost clomid without rx – buying clomid
https://azithromycin.bid/# zithromax online
zithromax antibiotic without prescription buy zithromax online cheap generic zithromax 500mg india
Excellent post. I used to be checking constantly this weblog and
I’m impressed! Extremely useful information specially the last phase 🙂
I take care of such info much. I was looking for this
certain information for a long time. Thank you and good luck.
Thank you for the good writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you! By the way,
how can we communicate?
Pingback: child porn
can you buy cheap clomid now: where to buy cheap clomid online – how can i get cheap clomid without dr prescription
http://amoxicillin.bid/# amoxicillin 500mg capsules
1250 mg prednisone drug prices prednisone prednisone 10 mg brand name
http://clomiphene.icu/# can you get clomid pills
purchase ivermectin: ivermectin 5 mg – ivermectin 2ml
where can i get generic clomid no prescription: where to buy generic clomid without rx – order cheap clomid now
http://amoxicillin.bid/# where can i buy amoxicillin over the counter uk
where buy cheap clomid without prescription clomid tablet how to buy generic clomid online
ivermectin 4 tablets price: stromectol cvs – stromectol 12mg online
http://ivermectin.store/# ivermectin 8000
how to buy cheap clomid price can i order generic clomid now order clomid without rx
buying generic clomid no prescription: can i buy cheap clomid no prescription – where to buy clomid no prescription
http://clomiphene.icu/# can you get generic clomid prices
where can you buy zithromax: zithromax antibiotic – zithromax 500 mg lowest price drugstore online
https://azithromycin.bid/# zithromax canadian pharmacy
amoxicillin 500 mg capsule: ampicillin amoxicillin – amoxicillin price without insurance
ivermectin 50ml stromectol lotion ivermectin new zealand
XXX videos
https://clomiphene.icu/# where to buy generic clomid without a prescription
amoxicillin discount: amoxicillin generic – amoxicillin cost australia
Cryptocurrency Payment gateway
перевод документов
ivermectin price canada price of ivermectin liquid ivermectin tablets order
https://clomiphene.icu/# can i buy clomid
prednisone for cheap: 10mg prednisone daily – prednisone over the counter south africa
prednisone without a prescription: generic prednisone online – prednisone daily use
where can i buy zithromax medicine zithromax purchase online zithromax tablets for sale
https://ivermectin.store/# stromectol ivermectin
amoxicillin 500mg over the counter: amoxicillin online purchase – can i buy amoxicillin over the counter
http://prednisonetablets.shop/# 20 mg prednisone tablet
Each post you publish is a masterclass in its own right. Thanks for the insights!
I enjoy, lead to I found just what I was taking a look for.
You have ended my four day lengthy hunt! God Bless you man.
Have a great day. Bye
viagra online uk
The visuals you add to your posts make the concepts so much clearer. Great job!
Деревянные дома под ключ
Дома АВС – Ваш уютный уголок
Мы строим не просто дома, мы создаем пространство, где каждый уголок будет наполнен комфортом и радостью жизни. Наш приоритет – не просто предоставить место для проживания, а создать настоящий дом, где вы будете чувствовать себя счастливыми и уютно.
В нашем информационном разделе “ПРОЕКТЫ” вы всегда найдете вдохновение и новые идеи для строительства вашего будущего дома. Мы постоянно работаем над тем, чтобы предложить вам самые инновационные и стильные проекты.
Мы убеждены, что основа хорошего дома – это его дизайн. Поэтому мы предоставляем услуги опытных дизайнеров-архитекторов, которые помогут вам воплотить все ваши идеи в жизнь. Наши архитекторы и персональные консультанты всегда готовы поделиться своим опытом и предложить функциональные и комфортные решения для вашего будущего дома.
Мы стремимся сделать весь процесс строительства максимально комфортным для вас. Наша команда предоставляет детализированные сметы, разрабатывает четкие этапы строительства и осуществляет контроль качества на каждом этапе.
Для тех, кто ценит экологичность и близость к природе, мы предлагаем деревянные дома премиум-класса. Используя клееный брус и оцилиндрованное бревно, мы создаем уникальные и здоровые условия для вашего проживания.
Тем, кто предпочитает надежность и многообразие форм, мы предлагаем дома из камня, блоков и кирпичной кладки.
Для практичных и ценящих свое время людей у нас есть быстровозводимые каркасные дома и эконом-класса. Эти решения обеспечат вас комфортным проживанием в кратчайшие сроки.
С Домами АВС создайте свой уютный уголок, где каждый момент жизни будет наполнен радостью и удовлетворением
mexican mail order pharmacies: Online Pharmacies in Mexico – medicine in mexico pharmacies mexicanpharm.shop
indian pharmacy paypal: buy medicines online in india – Online medicine order indianpharm.store
https://mexicanpharm.shop/# mexican border pharmacies shipping to usa mexicanpharm.shop
mexican border pharmacies shipping to usa Online Mexican pharmacy pharmacies in mexico that ship to usa mexicanpharm.shop
sildenafil 100mg
fantastic points altogether, you just won a new reader.
What would you suggest about your put up that you just made a few days in the
past? Any certain?
levitra 60mg
canadian pharmacy online reviews: canadian pharmacy ltd – pharmacy in canada canadianpharm.store
cheap canadian pharmacy: Certified Online Pharmacy Canada – cheapest pharmacy canada canadianpharm.store
http://canadianpharm.store/# ordering drugs from canada canadianpharm.store
india online pharmacy top 10 online pharmacy in india india pharmacy mail order indianpharm.store
Rastreador de celular – Aplicativo de rastreamento oculto que registra localização, SMS, áudio de chamadas, WhatsApp, Facebook, foto, câmera, atividade de internet. Melhor para controle dos pais e monitoramento de funcionários. Rastrear Telefone Celular Grátis – Programa de Monitoramento Online.
This article was a refreshing change from your usual style, and I really enjoyed it!
The true adblocker chrome extension is an essential browser enhancement that transforms your online experience by effectively removing all unwanted ads and empowers you to take control of your browsing domain which provides a clean and distraction-free online journey.
buying from online mexican pharmacy: reputable mexican pharmacies online – mexican rx online mexicanpharm.shop
http://canadianpharm.store/# legit canadian pharmacy online canadianpharm.store
http://canadianpharm.store/# ordering drugs from canada canadianpharm.store
reliable canadian pharmacy Certified Online Pharmacy Canada my canadian pharmacy review canadianpharm.store
sildenafil from india
online caverta
mexican drugstore online: mexican drugstore online – buying from online mexican pharmacy mexicanpharm.shop
mexico pharmacies prescription drugs: Certified Pharmacy from Mexico – medicine in mexico pharmacies mexicanpharm.shop
sildenafil citrate 20mg tablets
https://canadianpharm.store/# buying drugs from canada canadianpharm.store
mexican drugstore online: Online Pharmacies in Mexico – mexican drugstore online mexicanpharm.shop
viagra australia
mexico drug stores pharmacies Online Pharmacies in Mexico mexican online pharmacies prescription drugs mexicanpharm.shop
buy prescription drugs from india: order medicine from india to usa – world pharmacy india indianpharm.store
sildenafil 100mg uk cheapest
http://indianpharm.store/# world pharmacy india indianpharm.store
suhagra 50 mg online
Thanks designed for sharing such a pleasant idea, paragraph
is pleasant, thats why i have read it fully
buy prescription drugs from india: order medicine from india to usa – best online pharmacy india indianpharm.store
canada drug pharmacy Licensed Online Pharmacy certified canadian international pharmacy canadianpharm.store
http://indianpharm.store/# reputable indian online pharmacy indianpharm.store
mexican border pharmacies shipping to usa: Online Pharmacies in Mexico – mexican border pharmacies shipping to usa mexicanpharm.shop
indian pharmacies safe: international medicine delivery from india – п»їlegitimate online pharmacies india indianpharm.store
http://mexicanpharm.shop/# mexican online pharmacies prescription drugs mexicanpharm.shop
viagra pill
certified canadian pharmacy Licensed Online Pharmacy vipps approved canadian online pharmacy canadianpharm.store
https://canadianpharm.store/# legitimate canadian pharmacy online canadianpharm.store
top online pharmacy india: Indian pharmacy to USA – indianpharmacy com indianpharm.store
Даркнет, сокращение от “даркнетворк” (dark network), представляет собой часть интернета, недоступную для обычных поисковых систем. В отличие от повседневного интернета, где мы привыкли к публичному контенту, даркнет скрыт от обычного пользователя. Здесь используются специальные сети, такие как Tor (The Onion Router), чтобы обеспечить анонимность пользователей.
canadian pharmacy: Certified Online Pharmacy Canada – canada pharmacy canadianpharm.store
You bring fresh and innovative ideas to your readers with each post.
cheap viagra generic
Each blog post is a journey into knowledge and understanding.
http://canadianpharm.store/# my canadian pharmacy rx canadianpharm.store
top online pharmacy india: Indian pharmacy to USA – india online pharmacy indianpharm.store
mexico drug stores pharmacies mexican pharmaceuticals online buying from online mexican pharmacy mexicanpharm.shop
online sildenafil
The way you connect with your readers is exceptional.
Wow, this piece of writing is good, my younger sister is analyzing these things, therefore
I am going to let know her.
Your commitment to quality and depth in your writing is clear.
sildenafil 100mg
Your insights are always groundbreaking and enlightening.
http://indianpharm.store/# reputable indian pharmacies indianpharm.store
The authenticity and passion in your writing are evident.
mexico pharmacy: Online Mexican pharmacy – medicine in mexico pharmacies mexicanpharm.shop
vipps approved canadian online pharmacy: Certified Online Pharmacy Canada – medication canadian pharmacy canadianpharm.store
Your writing is a wonderful mix of informative and compelling.
buying prescription drugs in mexico medicine in mexico pharmacies mexican border pharmacies shipping to usa mexicanpharm.shop
sildenafil 50 mg tablet price in india
https://indianpharm.store/# indian pharmacy paypal indianpharm.store
http://mexicanpharm.shop/# mexican drugstore online mexicanpharm.shop
top 10 pharmacies in india: Online medicine order – Online medicine order indianpharm.store
adderall canadian pharmacy: Canadian International Pharmacy – reputable canadian pharmacy canadianpharm.store
vidalista online
purple pharmacy mexico price list Online Pharmacies in Mexico medication from mexico pharmacy mexicanpharm.shop
Each article is a testament to your commitment to excellence.
viagra 100mg online uk
Your writing is a wonderful mix of informative and compelling.
http://indianpharm.store/# indian pharmacies safe indianpharm.store
onlinepharmaciescanada com: Canada Pharmacy online – canadian pharmacies compare canadianpharm.store
Your commitment to quality and depth in your writing is clear.
Your blog provides a unique blend of insights and practical advice.
sildenafil 20 mg
Your dedication to providing valuable content shines through every post.
canada pharmacy reviews: Canadian International Pharmacy – drugs from canada canadianpharm.store
buy medicines online in india international medicine delivery from india top 10 pharmacies in india indianpharm.store
https://mexicanpharm.shop/# best online pharmacies in mexico mexicanpharm.shop
pharmacies in canada that ship to the us: Licensed Online Pharmacy – canadian drug stores canadianpharm.store
rg777
sildenafil 100mg tablets price
http://mexicanpharm.shop/# mexico drug stores pharmacies mexicanpharm.shop
viagra
I’d like to find out more? I’d like to find out more details.
sildenafil 50 mg tablet price in india
http://canadadrugs.pro/# mexican border pharmacies shipping to usa
my mexican drugstore canadian mail order pharmacies best canadian pharmacies
online meds: canadian pharmacy worldwide – legitimate canadian pharmacy online
viagra generic
prescription price checker: canada mail pharmacy – legitimate canadian pharmacy online
**娛樂城與線上賭場:現代娛樂的轉型與未來**
在當今數位化的時代,”娛樂城”和”線上賭場”已成為現代娛樂和休閒生活的重要組成部分。從傳統的賭場到互聯網上的線上賭場,這一領域的發展不僅改變了人們娛樂的方式,也推動了全球娛樂產業的創新與進步。
**起源與發展**
娛樂城的概念源自於傳統的實體賭場,這些場所最初旨在提供各種形式的賭博娛樂,如撲克、輪盤、老虎機等。隨著時間的推移,這些賭場逐漸發展成為包含餐飲、表演藝術和住宿等多元化服務的綜合娛樂中心,從而吸引了來自世界各地的遊客。
隨著互聯網技術的飛速發展,線上賭場應運而生。這種新型態的賭博平台讓使用者可以在家中或任何有互聯網連接的地方,享受賭博遊戲的樂趣。線上賭場的出現不僅為賭博愛好者提供了更多便利與選擇,也大大擴展了賭博產業的市場範圍。
**特點與魅力**
娛樂城和線上賭場的主要魅力在於它們能提供多樣化的娛樂選項和高度的可訪問性。無論是實體的娛樂城還是虛擬的線上賭場,它們都致力於創造一個充滿樂趣和刺激的環境,讓人們可以從日常生活的壓力中短暫逃脫。
此外,線上賭場通過提供豐富的遊戲選擇、吸引人的獎金方案以及便捷的支付系統,成功地吸引了全球範圍內的用戶。這些平台通常具有高度的互動性和社交性,使玩家不僅能享受遊戲本身,還能與來自世界各地的其他玩家交流。
**未來趨勢**
隨著技術的不斷進步和用戶需求的不斷演變,娛樂城和線上賭場的未來發展呈現出多元化的趨勢。一方面,虛
擬現實(VR)和擴增現實(AR)技術的應用,有望為線上賭場帶來更加沉浸式和互動式的遊戲體驗。另一方面,對於實體娛樂城而言,將更多地注重提供綜合性的休閒體驗,結合賭博、娛樂、休閒和旅遊等多個方面,以滿足不同客群的需求。
此外,隨著對負責任賭博的認識加深,未來娛樂城和線上賭場在提供娛樂的同時,也將更加注重促進健康的賭博行為和保護用戶的安全。
總之,娛樂城和線上賭場作為現代娛樂生活的一部分,隨著社會的發展和技術的進步,將繼續演化和創新,為人們提供更多的樂趣和便利。這一領域的未來發展無疑充滿了無限的可能性和機遇。
sildenafil citrate 25mg
best online pharmacy without prescriptions: canadian mail order pharmacy – cheap meds no prescription
http://canadadrugs.pro/# canadian online pharmacy reviews
the generics pharmacy online delivery prescription meds without the prescription canadian drug company
non prescription canadian pharmacies: canadian pharmacy reviews – best online drugstore
sildenafil citrate tablets
discount online canadian pharmacy: non prescription canadian pharmacy – canadian drugstore
http://canadadrugs.pro/# order canadian drugs
canadian pharmacies no prescription needed canadian pharmacy testosterone gel online drugstore reviews
cialis 10mg
certified canadian international pharmacy: trusted online pharmacy – trusted canadian online pharmacy
pharmacy: canadian drug store viagra – prescription drugs without prescription
https://canadadrugs.pro/# get canadian drugs
sildenafil
pharmacy cost comparison order prescriptions discount drugs canada
線上賭場
canadian pharmacy prices: cheapest canadian online pharmacy – list of 24 hour pharmacies
https://canadadrugs.pro/# canadian pharmacy prednisone
buy mexican drugs online: canadian rx – canadian pharmacy drugstore
reliable canadian online pharmacy: mexican border pharmacies shipping to usa – perscription drugs without prescription
viagra price in usa
http://canadadrugs.pro/# highest discount on medicines online
buy prescriptions online: price drugs – usa online pharmacy
viagra tablet
trusted online pharmacy: canadian drugs online pharmacy – aarp canadian pharmacy
http://canadadrugs.pro/# online pharmacies canada reviews
drugs canada: legitimate canadian mail order pharmacy – cheapest canadian pharmacy
sildenafil 100mg uk cheapest
sildenafil sandoz
http://canadadrugs.pro/# canadian pharmacy no prescription
ed drugs online: synthroid canadian pharmacy – pharmacy drugstore online pharmacy
extra super viagra
sildenafil for women
generic viagra online canadian pharmacy
https://canadadrugs.pro/# mexican pharmacy online medications
canadian trust pharmacy: synthroid canadian pharmacy – best canadian mail order pharmacies
cheap viagra online canadian pharmacy: trusted online canadian pharmacy – ed meds online
Sildenafil 200mg
Hello there, I do think your website might be having internet browser compatibility problems.
Whenever I take a look at your site in Safari, it looks fine but when opening in IE, it’s got
some overlapping issues. I merely wanted to provide you with a quick heads up!
Aside from that, fantastic blog!
viagra coupons
non prescription viagra
viagra coupons
canadian internet pharmacies: canada pharmaceutical online ordering – prescription prices comparison
canadian pharmacy no rx needed: no 1 canadian pharcharmy online – non perscription online pharmacies
http://canadadrugs.pro/# safe reliable canadian pharmacy
Brand Viagra 50mg
sildenafil sandoz
I’m in awe of the way you handle topics with both grace and authority.
viagra from canadian pharmacy
sildenafil prescription
canadian viagra sales
sildenafil oral jelly
https://canadadrugs.pro/# online pharmacies canadian
womens viagra pill
can you buy viagra online
get paid $1 per click
Understanding the processes and protocols within a Professional Tenure Committee (PTC) is crucial for faculty members. This Frequently Asked Questions (FAQ) guide aims to address common queries related to PTC procedures, voting, and membership.
1. Why should members of the PTC fill out vote justification forms explaining their votes?
Vote justification forms provide transparency in decision-making. Members articulate their reasoning, fostering a culture of openness and ensuring that decisions are well-founded and understood by the academic community.
2. How can absentee ballots be cast?
To accommodate absentee voting, PTCs may implement secure electronic methods or designated proxy voters. This ensures that faculty members who cannot physically attend meetings can still contribute to decision-making processes.
3. How will additional members of PTCs be elected in departments with fewer than four tenured faculty members?
In smaller departments, creative solutions like rotating roles or involving faculty from related disciplines can be explored. Flexibility in election procedures ensures representation even in departments with fewer tenured faculty members.
4. Can a faculty member on OCSA or FML serve on a PTC?
Faculty members involved in other committees like the Organization of Committee on Student Affairs (OCSA) or Family and Medical Leave (FML) can serve on a PTC, but potential conflicts of interest should be carefully considered and managed.
5. Can an abstention vote be cast at a PTC meeting?
Yes, PTC members have the option to abstain from voting if they feel unable to take a stance on a particular matter. This allows for ethical decision-making and prevents uninformed voting.
6. What constitutes a positive or negative vote in PTCs?
A positive vote typically indicates approval or agreement, while a negative vote signifies disapproval or disagreement. Clear definitions and guidelines within each PTC help members interpret and cast their votes accurately.
7. What constitutes a quorum in a PTC?
A quorum, the minimum number of members required for a valid meeting, is essential for decision-making. Specific rules about quorum size are usually outlined in the PTC’s governing documents.
Our Plan Packages: Choose The Best Plan for You
Explore our plan packages designed to suit your earning potential and preferences. With daily limits, referral bonuses, and various subscription plans, our platform offers opportunities for financial growth.
Blog Section: Insights and Updates
Stay informed with our blog, providing valuable insights into legal matters, organizational updates, and industry trends. Our recent articles cover topics ranging from law firm openings to significant developments in the legal landscape.
Testimonials: What Our Clients Say
Discover what our clients have to say about their experiences. Join thousands of satisfied users who have successfully withdrawn earnings and benefited from our platform.
Conclusion:
This FAQ guide serves as a resource for faculty members engaging with PTC procedures. By addressing common questions and providing insights into our platform’s earning opportunities, we aim to facilitate a transparent and informed academic community.
cheap viagra for sale
sildenafil costs
This was a thoroughly insightful read. Thank you for sharing your expertise!
https://medicinefromindia.store/# buy prescription drugs from india
top rated ed pills: cheap ed pills – best ed treatment
male ed pills ed medications list natural remedies for ed
Viagra Professional 50mg
buy generic viagra
viagra for sale online
buy prescription drugs online: cheap cialis – levitra without a doctor prescription
safe online pharmacies in canada best canadian pharmacy canadian online pharmacy
https://canadianinternationalpharmacy.pro/# legit canadian pharmacy
sildenafil 100 mg tablets
reputable indian online pharmacy: online shopping pharmacy india – п»їlegitimate online pharmacies india
generic viagra cost
sildenafil mexico
https://certifiedpharmacymexico.pro/# pharmacies in mexico that ship to usa
mexico pharmacies prescription drugs mexican border pharmacies shipping to usa purple pharmacy mexico price list
Hi i am kavin, its my first time to commenting anywhere, when i
read this piece of writing i thought i could also create comment due to this good
article.
viagra from canadian pharmacy
http://edwithoutdoctorprescription.pro/# best ed pills non prescription
escrow pharmacy canada: safe online pharmacies in canada – canadian world pharmacy
sildenafil for women
Your insights have added a lot of value to my understanding. Thanks for sharing.
Thanks for the complete information. You helped me.
extra super viagra
sildenafil cost
http://certifiedpharmacymexico.pro/# mexican mail order pharmacies
mexican rx online pharmacies in mexico that ship to usa mexican mail order pharmacies
generic of viagra
BioHealth cbd
where to buy Vitcore
Nufarm cbd gummies website
You have a gift for explaining things in an understandable way. Thank you!
world pharmacy india: indianpharmacy com – reputable indian pharmacies
http://medicinefromindia.store/# indian pharmacy paypal
PureKana cbd gummies official website
indian pharmacies safe world pharmacy india online shopping pharmacy india
Understanding the processes and protocols within a Professional Tenure Committee (PTC) is crucial for faculty members. This Frequently Asked Questions (FAQ) guide aims to address common queries related to PTC procedures, voting, and membership.
1. Why should members of the PTC fill out vote justification forms explaining their votes?
Vote justification forms provide transparency in decision-making. Members articulate their reasoning, fostering a culture of openness and ensuring that decisions are well-founded and understood by the academic community.
2. How can absentee ballots be cast?
To accommodate absentee voting, PTCs may implement secure electronic methods or designated proxy voters. This ensures that faculty members who cannot physically attend meetings can still contribute to decision-making processes.
3. How will additional members of PTCs be elected in departments with fewer than four tenured faculty members?
In smaller departments, creative solutions like rotating roles or involving faculty from related disciplines can be explored. Flexibility in election procedures ensures representation even in departments with fewer tenured faculty members.
4. Can a faculty member on OCSA or FML serve on a PTC?
Faculty members involved in other committees like the Organization of Committee on Student Affairs (OCSA) or Family and Medical Leave (FML) can serve on a PTC, but potential conflicts of interest should be carefully considered and managed.
5. Can an abstention vote be cast at a PTC meeting?
Yes, PTC members have the option to abstain from voting if they feel unable to take a stance on a particular matter. This allows for ethical decision-making and prevents uninformed voting.
6. What constitutes a positive or negative vote in PTCs?
A positive vote typically indicates approval or agreement, while a negative vote signifies disapproval or disagreement. Clear definitions and guidelines within each PTC help members interpret and cast their votes accurately.
7. What constitutes a quorum in a PTC?
A quorum, the minimum number of members required for a valid meeting, is essential for decision-making. Specific rules about quorum size are usually outlined in the PTC’s governing documents.
Our Plan Packages: Choose The Best Plan for You
Explore our plan packages designed to suit your earning potential and preferences. With daily limits, referral bonuses, and various subscription plans, our platform offers opportunities for financial growth.
Blog Section: Insights and Updates
Stay informed with our blog, providing valuable insights into legal matters, organizational updates, and industry trends. Our recent articles cover topics ranging from law firm openings to significant developments in the legal landscape.
Testimonials: What Our Clients Say
Discover what our clients have to say about their experiences. Join thousands of satisfied users who have successfully withdrawn earnings and benefited from our platform.
Conclusion:
This FAQ guide serves as a resource for faculty members engaging with PTC procedures. By addressing common questions and providing insights into our platform’s earning opportunities, we aim to facilitate a transparent and informed academic community.
where to buy cbd gummies
where can i buy cbd gummies
апостиль в новосибирске
http://canadianinternationalpharmacy.pro/# canadian pharmacy online store
sildenafil medication
best male ed pills: new treatments for ed – erectile dysfunction medicines
viagra from canadian pharmacy
mexican pharmacy without prescription generic cialis without a doctor prescription non prescription erection pills
sildenafil femme
I do not even know the way I ended up here, however I thought this submit used to be good.
I do not recognize who you’re however certainly you’re going to a famous blogger when you
are not already. Cheers!
non prescription viagra
https://edwithoutdoctorprescription.pro/# viagra without doctor prescription amazon
sildenafil for women
You have a gift for explaining things in an understandable way. Thank you!
price for viagra
twitch adblock chrome Möchten Sie Live-Streaming genießen? twitch ad blocker, Aber es gibt Werbung, die Ihr Erlebnis ruiniert, dann laden Sie sie einfach herunter twitch adblock und genießen Sie das Streaming ohne Störung.
ppc agency near me
Understanding the processes and protocols within a Professional Tenure Committee (PTC) is crucial for faculty members. This Frequently Asked Questions (FAQ) guide aims to address common queries related to PTC procedures, voting, and membership.
1. Why should members of the PTC fill out vote justification forms explaining their votes?
Vote justification forms provide transparency in decision-making. Members articulate their reasoning, fostering a culture of openness and ensuring that decisions are well-founded and understood by the academic community.
2. How can absentee ballots be cast?
To accommodate absentee voting, PTCs may implement secure electronic methods or designated proxy voters. This ensures that faculty members who cannot physically attend meetings can still contribute to decision-making processes.
3. How will additional members of PTCs be elected in departments with fewer than four tenured faculty members?
In smaller departments, creative solutions like rotating roles or involving faculty from related disciplines can be explored. Flexibility in election procedures ensures representation even in departments with fewer tenured faculty members.
4. Can a faculty member on OCSA or FML serve on a PTC?
Faculty members involved in other committees like the Organization of Committee on Student Affairs (OCSA) or Family and Medical Leave (FML) can serve on a PTC, but potential conflicts of interest should be carefully considered and managed.
5. Can an abstention vote be cast at a PTC meeting?
Yes, PTC members have the option to abstain from voting if they feel unable to take a stance on a particular matter. This allows for ethical decision-making and prevents uninformed voting.
6. What constitutes a positive or negative vote in PTCs?
A positive vote typically indicates approval or agreement, while a negative vote signifies disapproval or disagreement. Clear definitions and guidelines within each PTC help members interpret and cast their votes accurately.
7. What constitutes a quorum in a PTC?
A quorum, the minimum number of members required for a valid meeting, is essential for decision-making. Specific rules about quorum size are usually outlined in the PTC’s governing documents.
Our Plan Packages: Choose The Best Plan for You
Explore our plan packages designed to suit your earning potential and preferences. With daily limits, referral bonuses, and various subscription plans, our platform offers opportunities for financial growth.
Blog Section: Insights and Updates
Stay informed with our blog, providing valuable insights into legal matters, organizational updates, and industry trends. Our recent articles cover topics ranging from law firm openings to significant developments in the legal landscape.
Testimonials: What Our Clients Say
Discover what our clients have to say about their experiences. Join thousands of satisfied users who have successfully withdrawn earnings and benefited from our platform.
Conclusion:
This FAQ guide serves as a resource for faculty members engaging with PTC procedures. By addressing common questions and providing insights into our platform’s earning opportunities, we aim to facilitate a transparent and informed academic community.
otc sildenafil
prescription meds without the prescriptions generic cialis without a doctor prescription buy prescription drugs from india
https://edpill.cheap/# men’s ed pills
best price for viagra
northern pharmacy canada: legit canadian pharmacy online – canada drugs
20Bet registration
online gambling
Melhor aplicativo de controle parental para proteger seus filhos – Monitorar secretamente secreto GPS, SMS, chamadas, WhatsApp, Facebook, localização. Você pode monitorar remotamente as atividades do telefone móvel após o download e instalar o apk no telefone de destino.
Kraken darknet market зеркало
Темная сторона интернета, это, тайную, платформу, на, интернете, доступ к которой, осуществляется, путем, особые, софт и, инструменты, сохраняющие, скрытность сетевых участников. Одним из, таких, средств, считается, Тор браузер, позволяет, обеспечивает, защищенное, подключение к даркнету. При помощи, его, сетевые пользователи, имеют возможность, сокрыто, обращаться к, сайты, не видимые, стандартными, поисками, создавая тем самым, условия, для проведения, различных, нелегальных деятельностей.
Крупнейшая торговая площадка, в результате, часто упоминается в контексте, скрытой сетью, в качестве, рынок, для, криминалитетом. На этом ресурсе, может быть возможность, купить, различные, запрещенные, услуги, начиная от, наркотических средств и стволов, заканчивая, хакерскими действиями. Платформа, гарантирует, высокий уровень, шифрования, а также, защиты личной информации, это, предоставляет, ее, интересной, для тех, кто, стремится, избежать, преследований, от законопослушных органов
http://edwithoutdoctorprescription.pro/# viagra without doctor prescription amazon
safe reliable canadian pharmacy canadian pharmacy tampa canada drug pharmacy
Betwinner bonus
construction work in dallas tx
Даркнет, это, анонимную, сеть, в, сети, вход, получается, по средствам, уникальные, приложения а также, инструменты, предоставляющие, анонимность участников. Одним из, подобных, средств, считается, браузер Тор, который обеспечивает, обеспечивает защиту, безопасное, подключение к сети, в даркнет. С, его, пользователи, имеют шанс, незаметно, посещать, сайты, не видимые, обычными, поисковыми сервисами, что делает возможным, среду, для проведения, различных, запрещенных действий.
Кракен, соответственно, часто упоминается в контексте, темной стороной интернета, в качестве, рынок, для, киберпреступниками. На этой площадке, может быть возможность, получить доступ к, разные, нелегальные, вещи, начиная, наркотических средств и огнестрельного оружия, вплоть до, хакерскими услугами. Система, предоставляет, высокий уровень, шифрования, а также, анонимности, это, делает, ее, привлекательной, для, намерен, избежать, негативных последствий, со стороны правоохранительных органов.
what are the best ed medications
prescription for ed online
https://medicinefromindia.store/# indianpharmacy com
what is the safest erectile dysfunction drug
non prescription ed drugs cialis without a doctor prescription ed meds online without prescription or membership
ed drugs list
ed drugs online
https://medicinefromindia.store/# top online pharmacy india
ed drugs from canada
generic drugs for ed
pharmacies in mexico that ship to usa: mexican mail order pharmacies – mexico pharmacies prescription drugs
ed meds online without doctor prescription generic cialis without a doctor prescription non prescription ed drugs
best ed medications
best ed treatment
http://canadianinternationalpharmacy.pro/# onlinecanadianpharmacy
buy ed pills from india
new drugs for ed
best ed drugs for seniors
mexican rx online mexican mail order pharmacies medication from mexico pharmacy
Hello there! I could have sworn I’ve been to this blog before but after looking at a few of
the posts I realized it’s new to me. Regardless, I’m certainly pleased I stumbled upon it and I’ll
be book-marking it and checking back frequently!
ed drug prices
http://canadianinternationalpharmacy.pro/# canadian drugs online
Ed Drugs
buy ed medication online
new ed drugs
ed dysfunction treatment
https://certifiedpharmacymexico.pro/# buying from online mexican pharmacy
india pharmacy top online pharmacy india top 10 pharmacies in india
non prescription ed pills
ed drug prices
natural ed medications
mexican border pharmacies shipping to usa: mexican drugstore online – pharmacies in mexico that ship to usa
most potent ed pills
http://edpill.cheap/# male ed pills
buy ed pills from india
buying prescription drugs in mexico mexican pharmacy п»їbest mexican online pharmacies
best drug for ed
best ed pills that work
ed drugs online canada
https://certifiedpharmacymexico.pro/# mexican mail order pharmacies
erectile dysfunction drugs
what is the safest erectile dysfunction drug
апостиль в новосибирске
best ed pills non prescription herbal ed treatment ed pills otc
erectile dysfunction pills from india
order ed pills
https://certifiedpharmacymexico.pro/# buying prescription drugs in mexico
non prescription erectile dysfunction pills
online ed drugs for purchase
cheap ed drugs
best india pharmacy online pharmacy india Online medicine home delivery
best ed medications
ed treatment in india
http://canadianinternationalpharmacy.pro/# canadian mail order pharmacy
mexican drugstore online: mexico drug stores pharmacies – pharmacies in mexico that ship to usa
generic ed pills from india
buy erection pills
http://medicinefromindia.store/# world pharmacy india
Узнайте секреты успешного онлайн-бизнеса и начните зарабатывать от 4000 рублей в день!
https://vk.com/club224576037
ed drugs cost
natural ed remedies
cheap erectile dysfunction pill how to cure ed medicine for erectile
where to buy ed drugs online
https://canadianinternationalpharmacy.pro/# canadian pharmacy india
best ed drug for men
new erectile dysfunction treatment 2024
where to buy ed drugs online
best prescription ed drugs
indian pharmacies safe top 10 pharmacies in india cheapest online pharmacy india
http://medicinefromindia.store/# top 10 pharmacies in india
best medicine for erectile dysfunction without side effects
http://edwithoutdoctorprescription.pro/# viagra without a doctor prescription
pharmacies in mexico that ship to usa mexico pharmacy buying from online mexican pharmacy
buying ed pills
Watches World
canadian pharmacy cheap: canadian pharmacy online reviews – canadian pharmacy drugs online
Amazing data, Many thanks!
canadadrugsonline canada drug pharmacy canada pharmacies online pharmacy
treatments for ed
generic ed drugs canada
Whoa a lot of terrific material.
canadian rx pharmacy online canadian pharcharmy shoppers pharmacy
low cost ed drugs
cheap erectile dysfunction pill
best ed drugs
Regards. Wonderful stuff!
aarp approved canadian online pharmacies online pharmacies no prescription canadian online pharmacies legitimate by aarp
mexican border pharmacies shipping to usa mexican online pharmacies prescription drugs reputable mexican pharmacies online
best mexican online pharmacies medication from mexico pharmacy buying from online mexican pharmacy
best ed non prescription pill
You said it adequately..
cialis canada ed meds online canadian pharmacy viagra brand
ed pills non prescription
generic ed drugs cost
mexico pharmacy buying prescription drugs in mexico online medication from mexico pharmacy
You said it perfectly..
online medicine tablets shopping compare prescription prices canadian pharmacy generic viagra
http://mexicanph.com/# buying prescription drugs in mexico online
buying prescription drugs in mexico online
brand and generic names of ed drugs
how to get prescribed ed meds
With thanks! Loads of write ups!
viagra from canada canadian king pharmacy walmart pharmacy online
best ed drugs for women
buying prescription drugs in mexico online mexico drug stores pharmacies mexican rx online
mexican mail order pharmacies mexico drug stores pharmacies buying prescription drugs in mexico
where to buy ed drugs online
Info nicely taken!!
best online canadian pharcharmy walgreens pharmacy online best price prescription drugs
didihub slot gacor Indonesia 2024
cheap ed drugs online
You actually stated it perfectly!
canada drug prices https://canadiandrugsus.com/ viagra canada
Many thanks. Plenty of information.
cheap pharmacy online online pharmacy india pharmacie
generic ed drugs canada
ed drugs available in canada
Nicely put. With thanks.
online pharmacies uk https://canadianpharmacylist.com/ prescription drugs online without
It’s one thing to talk about theory, but seeing concrete applications and success stories really drives home the potential of these techniques.
Amazing lots of excellent data!
canadian pharmacy cialis compare rx prices rx online
best ed treatment
Helpful tips. Cheers!
pharmacy price comparison https://canadianpillsusa.com/ walgreens pharmacy
otc ed drugs that work
low cost ed drugs
best online pharmacies in mexico buying prescription drugs in mexico best online pharmacies in mexico
ed pills from india
impotence pills over the counter
mexican online pharmacies prescription drugs best online pharmacies in mexico buying prescription drugs in mexico
Superb material. Thanks!
canadian pharmacy uk delivery https://canadiantabsusa.com/ rx price comparison
medicine in mexico pharmacies mexican pharmacy best online pharmacies in mexico
Kudos, I like it!
londondrugs aarp recommended canadian pharmacies walgreens pharmacy
ed drugs online canada
best online pharmacies in mexico п»їbest mexican online pharmacies mexican pharmacy
best ed drugs
Nicely put. Kudos.
online pharmacies in usa https://northwestpharmacylabs.com/ canada drugs pharmacy
Wow, wonderful weblog structure! How long have you ever been running a blog for?
you make running a blog glance easy. The whole look of your web site is magnificent,
as neatly as the content!
You actually said this effectively!
discount pharmaceuticals aarp recommended canadian pharmacies mail order pharmacies
best non prescribed ed pill
Regards! Numerous content!
rx price comparison https://sopharmsn.com/ us pharmacy no prior prescription
Awesome info. Thank you!
compound pharmacy walmart pharmacy price check canadian pharma companies
Pingback: child porn
buying prescription drugs in mexico online medicine in mexico pharmacies mexico pharmacies prescription drugs
Watches World
Timepieces Universe
Customer Testimonials Illuminate Timepieces Universe Experience
At WatchesWorld, client fulfillment isn’t just a target; it’s a shining evidence to our dedication to excellence. Let’s dive into what our respected buyers have to say about their journeys, shedding light on the flawless support and extraordinary watches we provide.
O.M.’s Trustpilot Review: A Smooth Journey
“Very good interaction and follow through throughout the procedure. The watch was perfectly packed and in perfect. I would surely work with this teamwork again for a watch acquisition.
O.M.’s declaration demonstrates our dedication to contact and precise care in delivering timepieces in flawless condition. The faith forged with O.M. is a building block of our customer bonds.
Richard Houtman’s Insightful Testimonial: A Private Reach
“I dealt with Benny, who was exceedingly helpful and courteous at all times, keeping me frequently updated of the procedure. Advancing, even though I ended up sourcing the timepiece locally, I would still surely recommend Benny and the company moving forward.
Richard Houtman’s experience showcases our personalized approach. Benny’s assistance and constant interaction display our dedication to ensuring every patron feels treasured and informed.
Customer’s Productive Assistance Review: A Effortless Transaction
“A very efficient and effective service. Kept me current on the purchase development.
Our dedication to productivity is echoed in this patron’s input. Keeping customers notified and the uninterrupted advancement of purchases are integral to the WatchesWorld experience.
Investigate Our Current Selections
AP Royal Oak Automatic 37mm
A stunning piece at €45,900, this 2022 release (REF: 15551ST.ZZ.1356ST.05) invites you to add it to your shopping cart and elevate your range.
Hublot Classic Fusion Green Titanium Chronograph 45mm
Priced at €8,590 in 2024 (REF: 521.NX.8970.RX), this Hublot creation is a blend of style and novelty, awaiting your request.
Pingback: porn
mexico pharmacies prescription drugs mexican online pharmacies prescription drugs purple pharmacy mexico price list
buy ed pills from india
buy ed medication online
mexican mail order pharmacies best online pharmacies in mexico medication from mexico pharmacy
sildenafil online
Many thanks, Lots of posts.
medication costs canada pharmaceutical online ordering canada medication pharmacy
reputable mexican pharmacies online mexican online pharmacies prescription drugs buying prescription drugs in mexico
non prescription viagra
mexico drug stores pharmacies best online pharmacies in mexico mexican border pharmacies shipping to usa
Viagra 200mg
Nicely put, Thanks a lot.
northwest pharmaceuticals canada canadian pharmacies online publix pharmacy online ordering
ST666
generic viagra india
If you want to increase your familiarity just keep visiting this web site
and be updated with the latest gossip posted here.
generic viagra cost
Thank you! Fantastic information!
on line pharmacy online pharmacy india cheap canadian drugs
medication from mexico pharmacy mexican border pharmacies shipping to usa pharmacies in mexico that ship to usa
best natural viagra
purple pharmacy mexico price list medication from mexico pharmacy best online pharmacies in mexico
can you buy viagra online
You said it very well..
canada prescription drugs pharmacy cost comparison walgreens pharmacy online
Win big and win often at our Mexican casino platform. With generous payouts and thrilling bonuses, every spin is a chance to change your life. tres reyes casino esto es lo que te diferencia de los demas.
discount viagra usa
mexican pharmacy п»їbest mexican online pharmacies mexico drug stores pharmacies
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me? https://www.binance.com/uk-UA/join?ref=53551167
sildenafil femme
Защита в сети: Список мостов для Tor Browser
В наше время, когда аспекты неразглашения и сохранности в сети становятся все более актуальными, многие пользователи обращают внимание на аппаратные средства, позволяющие гарантировать неузнаваемость и секретность личной информации. Один из таких инструментов – Tor Browser, построенный на платформе Tor. Однако даже при использовании Tor Browser есть вероятность столкнуться с преградой или фильтрацией со стороны поставщиков интернет-услуг или цензоров.
Для преодоления этих ограничений были созданы подходы для Tor Browser. Переправы – это специальные серверы, которые могут быть использованы для пересечения блокировок и обеспечения доступа к сети Tor. В этой статье мы рассмотрим список переходов, которые можно использовать с Tor Browser для обеспечения надежной и безопасной скрытности в интернете.
meek-azure: Этот подход использует облачное решение Azure для того, чтобы заменить тот факт, что вы используете Tor. Это может быть важно в странах, где провайдеры блокируют доступ к серверам Tor.
obfs4: Переход обфускации, предоставляющий средства для сокрытия трафика Tor. Этот подход может эффективным образом обходить блокировки и цензуру, делая ваш трафик невидимым для сторонних.
fte: Мост, использующий Free Talk Encrypt (FTE) для обфускации трафика. FTE позволяет преобразовывать трафик так, чтобы он казался обычным сетевым трафиком, что делает его более трудным для выявления.
snowflake: Этот переправа позволяет вам использовать браузеры, которые работают с расширение Snowflake, чтобы помочь другим пользователям Tor пройти через запреты.
fte-ipv6: Вариант FTE с поддерживающий IPv6, который может быть полезен, если ваш провайдер интернета предоставляет IPv6-подключение.
Чтобы использовать эти переходы с Tor Browser, откройте его настройки, перейдите в раздел “Проброс мостов” и введите названия подходов, которые вы хотите использовать.
Не забывайте, что результативность переправ может изменяться в зависимости от страны и поставщиков интернет-услуг. Также рекомендуется периодически обновлять каталог переходов, чтобы быть уверенным в успехе обхода блокировок. Помните о важности секурности в интернете и производите защитные действия для сохранения своей личной информации.
Amazing content. Thank you.
canadian pharcharmy online fda approved ed drugs canada pharmacies without script
I Always Learn Something New From Your Posts. Thank You For The Education!
medication from mexico pharmacy п»їbest mexican online pharmacies mexican drugstore online
generic viagra canada
мосты для tor browser список
В века технологий, в момент, когда онлайн границы сливаются с реальностью, нельзя игнорировать возможность угроз в теневом интернете. Одним из рисков является blacksprut – слово, ставший символом криминальной, вредоносной деятельности в теневых уголках интернета.
Blacksprut, будучи частью подпольной сети, представляет серьезную угрозу для кибербезопасности и личной безопасности пользователей. Этот темный уголок сети иногда ассоциируется с запрещенными сделками, торговлей запрещенными товарами и услугами, а также иной противозаконными деяниями.
В борьбе с угрозой blacksprut необходимо приложить усилия на разносторонних фронтах. Одним из ключевых направлений является совершенствование технологий кибербезопасности. Развитие эффективных алгоритмов и технологий анализа данных позволит обнаруживать и пресекать деятельность blacksprut в реальном времени.
Помимо цифровых мер, важна согласованная деятельность усилий органов правопорядка на глобальном уровне. Международное сотрудничество в области цифровой безопасности необходимо для успешного противодействия угрозам, связанным с blacksprut. Обмен данными, выработка совместных стратегий и быстрые действия помогут снизить воздействие этой угрозы.
Просвещение и освещение также играют ключевую роль в борьбе с blacksprut. Повышение сознания пользователей о рисках подпольной сети и методах предотвращения становится неотъемлемой элементом антиспампинговых мероприятий. Чем более проинформированными будут пользователи, тем меньше вероятность попадания под влияние угрозы blacksprut.
В заключение, в борьбе с угрозой blacksprut необходимо скоординировать усилия как на инженерном, так и на нормативном уровнях. Это вызов, нуждающийся в совместных усилий общества, правоохранительных органов и IT-компаний. Только совместными усилиями мы добьемся создания безопасного и стойкого цифрового пространства для всех.
почему-тор браузер не соединяется
Тор Браузер является мощным инструментом для предоставления скрытности и защиты в всемирной сети. Однако, иногда пользователи могут попасть в с трудностями подключения. В настоящей публикации мы рассмотрим вероятные основания и подсчитаем способы решения для исправления неполадок с входом к Tor Browser.
Проблемы с интернетом:
Решение: Проверка ваше соединение с сетью. Проверьте, что вы присоединены к сети, и отсутствуют ли затруднений с вашим Интернет-поставщиком.
Блокировка инфраструктуры Тор:
Решение: В некоторых конкретных государствах или интернет-сетях Tor может быть прекращен. Испытайте использованием переходы для преодоления блокировок. В установках Tor Browser отметьте “Проброс мостов” и следуйте инструкциям.
Прокси-серверы и брандмауэры:
Решение: Проверьте настройки прокси-сервера и стены. Удостоверьтесь, что они не ограничивают доступ Tor Browser к интернету. Внесите изменения настройки или временно деактивируйте прокси и файерволы для тестирования.
Проблемы с самим приложением:
Решение: Удостоверьтесь, что у вас установлена последнее обновление Tor Browser. Иногда изменения могут разрешить сложности с доступом. Попробуйте также пересобрать обозреватель.
Временные сбои в Тор-инфраструктуре:
Решение: Подождите некоторое время некоторое время и попробуйте соединиться после. Временные неполадки в работе Tor могут вызываться, и они как правило устраняются в минимальные периоды времени.
Отключение JavaScript:
Решение: Некоторые из них веб-ресурсы могут ограничивать доступ через Tor, если в вашем приложении включен JavaScript. Попробуйте временно остановить JavaScript в параметрах программы.
Проблемы с антивирусным ПО:
Решение: Ваш программа защиты или стена может блокировать Tor Browser. Убедитесь, что у вас не установлено запретов для Tor в параметрах вашего защитного ПО.
Исчерпание памяти устройства:
Решение: Если у вас открыто много вкладок браузера или задачи, это может призвести к израсходованию памяти и затруднениям с соединением. Закройте лишние вкладки или перезапустите программу.
В случае, если сложность с подключением к Tor Browser остается, свяжитесь за помощью на официальной платформе обсуждения Tor. Эксперты могут предоставить дополнительную помощь и последовательность действий. Припоминайте, что стойкость и невидимость требуют постоянного внимания к деталям, так что отслеживайте изменениями и поддерживайте советам сообщества Tor.
Thank you. Fantastic stuff!
canada pharmacies/account canadian discount pharmacy publix pharmacy online ordering
Sildenafil 25mg
buying from online mexican pharmacy п»їbest mexican online pharmacies mexico pharmacies prescription drugs
https://mexicanph.shop/# buying from online mexican pharmacy
purple pharmacy mexico price list
sildenafil for women
zithromax in cats
mexican pharmacy mexico pharmacies prescription drugs pharmacies in mexico that ship to usa
Cheers, Wonderful stuff!
canadian pharmacies-247 https://canadiandrugsus.com/ international drug mart canadian pharmacy online store
You said it nicely.!
pharmacy online online pharmacies in usa mexican pharmacies shipping to usa
buying viagra online forum
Watches World
Watches Globe
Patron Reviews Reveal Timepieces Universe Adventure
At WatchesWorld, customer happiness isn’t just a objective; it’s a bright proof to our loyalty to excellence. Let’s delve into what our esteemed customers have to say about their adventures, shedding light on the flawless service and extraordinary clocks we supply.
O.M.’s Review Feedback: A Effortless Trip
“Very good interaction and follow-up throughout the process. The watch was perfectively packed and in mint. I would surely work with this team again for a timepiece acquisition.
O.M.’s statement illustrates our dedication to comms and careful care in delivering watches in impeccable condition. The trust forged with O.M. is a building block of our customer relationships.
Richard Houtman’s Insightful Testimonial: A Personalized Reach
“I dealt with Benny, who was exceedingly useful and polite at all times, keeping me regularly apprised of the procedure. Going forward, even though I ended up sourcing the watch locally, I would still surely recommend Benny and the business advancing.
Richard Houtman’s encounter illustrates our tailored approach. Benny’s support and constant comms exhibit our devotion to ensuring every client feels appreciated and apprised.
Customer’s Effective Service Testimonial: A Seamless Deal
“A very good and efficient service. Kept me updated on the order development.
Our loyalty to effectiveness is echoed in this client’s input. Keeping clients apprised and the effortless development of orders are integral to the Our Watch Boutique encounter.
Examine Our Most Recent Choices
Audemars Piguet Royal Oak Selfwinding 37mm
A gorgeous piece at €45,900, this 2022 edition (REF: 15551ST.ZZ.1356ST.05) invites you to add it to your basket and elevate your collection.
Hublot Classic Fusion Green Titanium Chronograph 45mm
Priced at €8,590 in 2024 (REF: 521.NX.8970.RX), this Hublot creation is a blend of design and invention, awaiting your inquiry.
Your Ability To Distill Complex Concepts Into Readable Content Is Admirable.
mexican pharmaceuticals online mexican pharmacy pharmacies in mexico that ship to usa
Well spoken indeed! .
pharmacy discount canadian pharmacy king price pro pharmacy canada
viagra from canadian pharmacy
mexico pharmacy mexico drug stores pharmacies mexico drug stores pharmacies
generic viagra overnight
medicine in mexico pharmacies mexican pharmaceuticals online buying from online mexican pharmacy
viagra without a doctor prescription canada
where can i buy viagra without a prescription
mexican pharmaceuticals online reputable mexican pharmacies online mexican border pharmacies shipping to usa
mexican pharmacy best mexican online pharmacies mexican drugstore online
mexican border pharmacies shipping to usa buying prescription drugs in mexico buying prescription drugs in mexico
online viagra
sildenafil for women
pharmacies in mexico that ship to usa medication from mexico pharmacy best mexican online pharmacies
best price for viagra
purple pharmacy mexico price list mexico drug stores pharmacies mexico pharmacy
Viagra
mexican rx online mexican rx online mexican pharmacy
https://mexicanph.shop/# mexican pharmaceuticals online
mexican pharmaceuticals online
mexican pharmacy medication from mexico pharmacy best mexican online pharmacies
sildenafil medication
Thank You For Adding Value To The Conversation With Your Insights.
mexican drugstore online mexican pharmaceuticals online mexican online pharmacies prescription drugs
amazon viagra
Feel the heat of the casino floor at our Mexican online casino. With live dealer games and interactive experiences, you’ll get the full VIP treatment from the comfort of your home. chumba casino este es tu futuro.
mexico pharmacies prescription drugs mexico pharmacy mexico drug stores pharmacies
Sildenafil 75mg
medicine in mexico pharmacies purple pharmacy mexico price list medicine in mexico pharmacies
buying prescription drugs in mexico mexico drug stores pharmacies mexican online pharmacies prescription drugs
sildenafil medication
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me? https://www.binance.com/zh-CN/join?ref=T7KCZASX
amazon viagra
You revealed this fantastically!
walgreens pharmacy online apollo pharmacy online pharmacy
Reliable content. Appreciate it!
canadian pharmacies that ship to us https://canadianpharmacylist.com/ walgreens online pharmacy
medication from mexico pharmacy mexican pharmaceuticals online mexican online pharmacies prescription drugs
Viagra 100mg
mexican rx online reputable mexican pharmacies online buying prescription drugs in mexico online
mexican online pharmacies prescription drugs reputable mexican pharmacies online best online pharmacies in mexico
sildenafil 20 mg tablet
You actually revealed this terrifically!
prescription drug assistance best online canadian pharmacy buy drugs online
price for viagra
Really tons of amazing data.
cialis online https://canadianpillsusa.com/ canada discount drug
mexican pharmacy buying from online mexican pharmacy mexican pharmacy
sildenafil 100 mg tablets
mexican drugstore online mexican pharmaceuticals online best online pharmacies in mexico
Brand Viagra 25mg
mexican mail order pharmacies п»їbest mexican online pharmacies mexico drug stores pharmacies
This Post Is A Testament To Your Expertise And Hard Work. Thank You!
Truly loads of helpful advice.
cheap prescription drugs costco online pharmacy on line pharmacy
https://mexicanph.shop/# mexican drugstore online
reputable mexican pharmacies online
mexico pharmacies prescription drugs mexican mail order pharmacies mexico drug stores pharmacies
You actually mentioned this superbly.
best online pharmacy https://canadiantabsusa.com/ canadian pharma companies
sildenafil price
Thank You For Shedding Light On This Subject. Your Perspective Is Refreshing!
sildenafil femme
Very good advice. Appreciate it!
canadian meds cvs online pharmacy humana online pharmacy
mexican border pharmacies shipping to usa buying prescription drugs in mexico online best mexican online pharmacies
best online pharmacies in mexico medication from mexico pharmacy buying from online mexican pharmacy
prices for viagra
Appreciate it! Plenty of write ups!
pharmacy online shopping https://northwestpharmacylabs.com/ pharmacy online no prescription
mexican rx online medication from mexico pharmacy medication from mexico pharmacy
best price for viagra 100mg
mexican pharmaceuticals online best online pharmacies in mexico buying prescription drugs in mexico
Your writing always inspires and educates. Thank you for the effort you put into your blog. Asheville sends its love!
buy brand viagra
Nicely put, Kudos!
pharmacies near me https://sopharmsn.com/ canadadrugs
buying from online mexican pharmacy mexico drug stores pharmacies pharmacies in mexico that ship to usa
viagra coupons
purple pharmacy mexico price list reputable mexican pharmacies online pharmacies in mexico that ship to usa
mexican rx online mexico drug stores pharmacies purple pharmacy mexico price list
discount viagra usa
100mg sildenafil
mexican pharmaceuticals online mexican pharmaceuticals online buying prescription drugs in mexico online
ST666
Viagra Professional 50mg
buying from online mexican pharmacy buying from online mexican pharmacy medication from mexico pharmacy
online viagra
medication from mexico pharmacy purple pharmacy mexico price list pharmacies in mexico that ship to usa
Regards! Plenty of info!
meds online pharmacy without dr prescriptions canadian online pharmacies
mexican pharmacy medication from mexico pharmacy mexican online pharmacies prescription drugs
cheap price viagra
http://mexicanph.com/# buying from online mexican pharmacy
buying from online mexican pharmacy
Your writing is like a gentle breeze, refreshing and uplifting. We’re big fans of your blog from Asheville!
best online pharmacies in mexico mexico pharmacy buying prescription drugs in mexico online
viagra for sale online
buying prescription drugs in mexico п»їbest mexican online pharmacies mexican pharmaceuticals online
Nicely spoken genuinely. !
best online pharmacy canadian pharmacy online trust pharmacy canada
Your blog is a treasure chest of wisdom and insight. We’re grateful to be readers from Asheville!
viagra meaning
Your words have a way of resonating deeply with your readers. Thank you for sharing your wisdom with us. Asheville loves your blog!
mexican mail order pharmacies mexican rx online mexican rx online
Your blog is a true testament to your passion and dedication. We’re proud supporters from Asheville!
Truly quite a lot of wonderful info!
pharmacy in canada canadian pharmacies that ship to us canadian pharmacy viagra
mexico drug stores pharmacies mexico drug stores pharmacies medicine in mexico pharmacies
mexican online pharmacies prescription drugs mexican pharmaceuticals online purple pharmacy mexico price list
viagra from canadian pharmacy
Thank you for consistently delivering top-notch content. We’re huge fans of your blog here in Asheville!
mexican online pharmacies prescription drugs mexico drug stores pharmacies mexican mail order pharmacies
buy viagra in mexico
Thank you for consistently delivering valuable content. We’re proud followers from Asheville!
Incredible a good deal of helpful knowledge!
online pharmacies generic viagra online us pharmacy no prior prescription
Your blog is a must-read for anyone seeking inspiration and knowledge. Asheville is lucky to have you!
Brand Viagra 50mg
mexican drugstore online mexican drugstore online mexican mail order pharmacies
Your writing is like a breath of fresh air, invigorating and rejuvenating. We’re proud followers from Asheville!
buying prescription drugs in mexico online mexico pharmacy pharmacies in mexico that ship to usa
sildenafil 50 mg
best online pharmacies in mexico mexican border pharmacies shipping to usa medication from mexico pharmacy
Thank you for being a constant source of inspiration through your blog. Asheville is proud to support you!
Cheers. I enjoy this!
shoppers pharmacy internet pharmacy rx pharmacy
buying viagra online forum
best online pharmacies in mexico mexican pharmaceuticals online mexico drug stores pharmacies
Thank you for enriching our lives with your blog. Asheville sends its warmest regards!
Sildenafil 75mg
buying prescription drugs in mexico mexico drug stores pharmacies mexican pharmaceuticals online
Info effectively utilized.!
canada drugs pharmacy online buy prescription drugs without doctor medical pharmacy
sildenafil online
purple pharmacy mexico price list mexican mail order pharmacies mexican drugstore online
https://mexicanph.com/# mexican online pharmacies prescription drugs
п»їbest mexican online pharmacies
indian medicine for erectile dysfunction
pharmacies in mexico that ship to usa purple pharmacy mexico price list п»їbest mexican online pharmacies
Win big and live the dream at our Mexican online casino. With life-changing jackpots and thrilling tournaments, fortune favors the bold. cassini la clave para una buena vida.
I just wanted to drop by and say how much I enjoy reading your blog. Asheville adores your work!
You revealed this perfectly.
drugs online https://canadiandrugsus.com/ panacea pharmacy
where to buy ed drugs online
Valuable info. Thanks.
drug costs canadapharmacy online discount pharmacy
mexican rx online mexican pharmacy best mexican online pharmacies
pharmacies in mexico that ship to usa buying from online mexican pharmacy purple pharmacy mexico price list
Thank you for sharing your expertise with the world through your blog. Asheville residents are grateful for your contributions.
erectile dysfunction drugs
Your blog posts are always a highlight of my day. Asheville residents are lucky to have such a talented writer in our midst.
Ed Drugs from India
Seriously many of awesome data!
canadian mail order pharmacies https://canadianpharmacylist.com/ drug prices comparison
mexico pharmacies prescription drugs mexican drugstore online mexican border pharmacies shipping to usa
You’ve made the point!
cialis canadian pharmacy canadian pharmacy reviews canada meds
fda approved ed treatment
buy ed pills from india
mexico pharmacy buying prescription drugs in mexico online mexico pharmacies prescription drugs
buying from online mexican pharmacy pharmacies in mexico that ship to usa mexican border pharmacies shipping to usa
You explained that fantastically!
pharmacy canada https://canadianpillsusa.com/ mexican pharmacy online
ed drugs in india
Thanks. Very good information!
cheap canadian drugs drugstore online ed meds online without doctor prescription
generic ed drugs canada
mexico drug stores pharmacies purple pharmacy mexico price list mexican drugstore online
Your blog is a treasure chest of wisdom and insight. We’re grateful to be readers from Asheville!
medicine in mexico pharmacies mexico pharmacy buying from online mexican pharmacy
Amazing postings. Thank you!
humana online pharmacy https://canadiantabsusa.com/ canada pharmaceuticals online generic
Position very well taken.!
canadian prescriptions online canadianpharmacy mexican pharmacy online medications
ed drugs in india
Thank you for enriching our lives with your blog. Asheville sends its warmest regards!
Good web site you’ve got here.. It’s hard to find excellent
writing like yours these days. I truly appreciate people like you!
Take care!!
reputable mexican pharmacies online mexican rx online mexican rx online
Thank you for sharing your expertise with the world through your blog. Asheville residents are grateful for your contributions.
fda approved ed treatment
This is nicely said. !
online canadian discount pharmacy https://northwestpharmacylabs.com/ national pharmacies
buy ed pills online
Seriously plenty of great data.
online pharmacies canada mexican pharmacies national pharmacies online
stromectol ivermectin stromectol pills ivermectin canada
buying ed pills online
how to buy prednisone online: prednisone 2 mg daily – prednisone 25mg from canada
http://stromectol.fun/# ivermectin 3
ed dysfunction treatment
Wow tons of wonderful data!
global pharmacy canada https://sopharmsn.com/ cheap viagra online canadian pharmacy
You mentioned it effectively!
online prescription drugs canada drugs online prescription drugs without doctor approval
Pingback: child porn
best ed drugs for seniors
http://amoxil.cheap/# generic amoxicillin cost
ed drugs for men
generic lisinopril online: lisinopril tabs 10mg – 50 mg lisinopril
best ed drugs over counter
over the counter prednisone cheap prednisone 50 mg price 80 mg prednisone daily
best drug for ed
https://buyprednisone.store/# over the counter prednisone cream
metformin hcl 1000 mg
best ed medicine in india
https://lisinopril.top/# lisinopril 10 mg tablet cost
ed drugs online
You could definitely see your expertise in the work
you write. The world hopes for even more passionate writers
like you who aren’t afraid to say how they believe. Always go after your heart.
ivermectin lotion for scabies: generic ivermectin – ivermectin nz
list of erectile dysfunction drugs
https://lisinopril.top/# order lisinopril without a prescription
legal erectile dysfunction pills
prednisone 40 mg prednisone pill 20 mg prednisone buy canada
best treatment for erectile dysfunction
fashion
https://buyprednisone.store/# prednisone 20mg online without prescription
amoxicillin cephalexin: can you purchase amoxicillin online – where can i get amoxicillin
Your blog is a sanctuary of wisdom and inspiration. We’re grateful readers from Asheville!
most potent ed pills
What a fantastic article! We’re big fans of your blog here in Asheville and eagerly await your next post.
ed drug levitra
cheap prednisone online prednisone generic cost by prednisone w not prescription
http://stromectol.fun/# buy stromectol
buy ed medication online
stromectol tablets buy online: ivermectin ebay – ivermectin brand
http://buyprednisone.store/# prednisone 20 mg
generic ed drugs fda approved
–Are your clients familiar using the web, do they utilize it routinely?
日本にオンラインカジノおすすめランキング2024年最新版
2024おすすめのオンラインカジノ
オンラインカジノはパソコンでしか遊べないというのは、もう一昔前の話。現在はスマホやタブレットなどのモバイル端末からも、パソコンと変わらないクオリティでオンラインカジノを当たり前に楽しむことができるようになりました。
数あるモバイルカジノの中で、当サイトが厳選したトップ5カジノはこちら。
オンラインカジノおすすめ: コニベット(Konibet)
コニベットといえば、キャッシュバックや毎日もらえるリベートボーナスなど豪華ボーナスが満載!それに加えて低い出金条件も見どころです。さらにVIPレベルごとの還元率の高さも業界内で突出している点や、出金速度の速さなどトータルバランスの良さからもハイローラーの方にも好まれています。
カスタマーサポートは365日24時間稼働しているので、初心者の方にも安心してご利用いただけます。
さらに【業界初のオンラインポーカー】を導入!毎日トーナメントも開催されているので、早速参加しちゃいましょう!
RTP(還元率)公開や、入出金対応がスムーズで初心者向き
2000種類以上の豊富なゲーム数を誇り、スロットゲーム多数!
今なら$20の入金不要ボーナスと最大$650還元ボーナス!
8種類以上のライブカジノプロバイダー
業界初オンラインポーカーあり,日本利用者数No.1の安心のオンラインカジノメディア!
おすすめポイント
コニベットは、その豊富なボーナスと高還元率、そして安心のキャッシュバック制度で知られています。まず、新規登録者には入金不要の$20ボーナスが提供され、さらに初回入金時には最大$650の還元ボーナスが得られます。これらのキャンペーンはプレイヤーにとって大きな魅力となっています。
また、コニベットの特徴的な点は、VIP制度です。一度ロイヤルクラブになると、降格がなく、スロットリベートが1.5%という驚異の還元率を享受できます。これは他のオンラインカジノと比較しても非常に高い還元率です。さらに、常時週間損失キャッシュバックも行っているため、不運で負けてしまった場合でも取り返すチャンスがあります。これらの特徴から、コニベットはプレイヤーにとって非常に魅力的なオンラインカジノと言えるでしょう。
コニベット 無料会員登録をする
| コニベットのボーナス
コニベットは、新規登録者向けに20ドルの入金不要ボーナスを用意しています
コニベットカジノでは、限定で初回入金後に残高が1ドル未満になった場合、入金額の50%(最高500ドル)がキャッシュバックされる。キャッシュバック額に出金条件はないため、獲得後にすぐ出金することも可能です。
| コニベットの入金方法
入金方法 最低 / 最高入金
マスターカード 最低 : $20 / 最高 : $6,000
ジェイシービー 最低 : $20/ 最高 : $6,000
アメックス 最低 : $20 / 最高 : $6,000
アイウォレット 最低 : $20 / 最高 : $100,000
スティックペイ 最低 : $20 / 最高 : $100,000
ヴィーナスポイント 最低 : $20 / 最高 : $10,000
仮想通貨 最低 : $20 / 最高 : $100,000
銀行送金 最低 : $20 / 最高 : $10,000
| コニベット出金方法
出金方法 最低 |最高出金
アイウォレット 最低 : $40 / 最高 : なし
スティックぺイ 最低 : $40 / 最高 : なし
ヴィーナスポイント 最低 : $40 / 最高 : なし
仮想通貨 最低 : $40 / 最高 : なし
銀行送金 最低 : $40 / 最高 : なし
https://furosemide.guru/# lasix 100mg
best ed drugs for women
You completed some fine points there. I did a search on the subject and found mainly persons will agree with your blog.
I am glad to be one of the visitors on this outstanding site (:, appreciate it for putting up.
best ed drugs over counter
amoxicillin brand name: amoxicillin online canada – where to buy amoxicillin 500mg
Thanks for the publish. My partner and i have often noticed that almost all people are desirous to lose weight when they wish to appear slim along with attractive. On the other hand, they do not usually realize that there are many benefits for losing weight also. Doctors say that fat people have problems with a variety of health conditions that can be instantly attributed to their own excess weight. The great thing is that people who’re overweight and suffering from diverse diseases can reduce the severity of the illnesses by simply losing weight. It’s possible to see a progressive but noted improvement with health if even a bit of a amount of weight loss is obtained.
cost of generic lisinopril 10 mg zestril 5 mg tablets lisinopril 20 mg for sale
disaster movie is hilarious, i laugh for hours just watching that movie,,
best medicine for erectile dysfunction without side effects
http://amoxil.cheap/# amoxicillin medicine over the counter
ed pills without side effects
what is the best non prescription erectile dysfunction
ed drugs online canada
where to buy amoxicillin: how much is amoxicillin – amoxicillin from canada
ed drugs compared
http://buyprednisone.store/# buy prednisone 20mg without a prescription best price
tablets to increase female libido
prednisone online paypal over the counter prednisone cheap prednisone 300mg
generic drugs for ed
Your writing is like a beacon of light in the darkness, guiding us towards knowledge and understanding. Asheville appreciates your blog!
ivermectin 4 tablets price: ivermectin 10 ml – ivermectin 400 mg
http://stromectol.fun/# ivermectin 3mg tab
list of ed drugs
best male ed pills
http://amoxil.cheap/# medicine amoxicillin 500
http://amoxil.cheap/# amoxicillin price without insurance
ed drugs canada
can you purchase amoxicillin online: amoxicillin 200 mg tablet – amoxicillin 500 mg cost
otc ed drugs that work
amoxicillin over the counter in canada amoxicillin online purchase amoxicillin online purchase
オンラインカジノ
日本にオンラインカジノおすすめランキング2024年最新版
2024おすすめのオンラインカジノ
オンラインカジノはパソコンでしか遊べないというのは、もう一昔前の話。現在はスマホやタブレットなどのモバイル端末からも、パソコンと変わらないクオリティでオンラインカジノを当たり前に楽しむことができるようになりました。
数あるモバイルカジノの中で、当サイトが厳選したトップ5カジノはこちら。
オンラインカジノおすすめ: コニベット(Konibet)
コニベットといえば、キャッシュバックや毎日もらえるリベートボーナスなど豪華ボーナスが満載!それに加えて低い出金条件も見どころです。さらにVIPレベルごとの還元率の高さも業界内で突出している点や、出金速度の速さなどトータルバランスの良さからもハイローラーの方にも好まれています。
カスタマーサポートは365日24時間稼働しているので、初心者の方にも安心してご利用いただけます。
さらに【業界初のオンラインポーカー】を導入!毎日トーナメントも開催されているので、早速参加しちゃいましょう!
RTP(還元率)公開や、入出金対応がスムーズで初心者向き
2000種類以上の豊富なゲーム数を誇り、スロットゲーム多数!
今なら$20の入金不要ボーナスと最大$650還元ボーナス!
8種類以上のライブカジノプロバイダー
業界初オンラインポーカーあり,日本利用者数No.1の安心のオンラインカジノメディア!
おすすめポイント
コニベットは、その豊富なボーナスと高還元率、そして安心のキャッシュバック制度で知られています。まず、新規登録者には入金不要の$20ボーナスが提供され、さらに初回入金時には最大$650の還元ボーナスが得られます。これらのキャンペーンはプレイヤーにとって大きな魅力となっています。
また、コニベットの特徴的な点は、VIP制度です。一度ロイヤルクラブになると、降格がなく、スロットリベートが1.5%という驚異の還元率を享受できます。これは他のオンラインカジノと比較しても非常に高い還元率です。さらに、常時週間損失キャッシュバックも行っているため、不運で負けてしまった場合でも取り返すチャンスがあります。これらの特徴から、コニベットはプレイヤーにとって非常に魅力的なオンラインカジノと言えるでしょう。
コニベット 無料会員登録をする
| コニベットのボーナス
コニベットは、新規登録者向けに20ドルの入金不要ボーナスを用意しています
コニベットカジノでは、限定で初回入金後に残高が1ドル未満になった場合、入金額の50%(最高500ドル)がキャッシュバックされる。キャッシュバック額に出金条件はないため、獲得後にすぐ出金することも可能です。
| コニベットの入金方法
入金方法 最低 / 最高入金
マスターカード 最低 : $20 / 最高 : $6,000
ジェイシービー 最低 : $20/ 最高 : $6,000
アメックス 最低 : $20 / 最高 : $6,000
アイウォレット 最低 : $20 / 最高 : $100,000
スティックペイ 最低 : $20 / 最高 : $100,000
ヴィーナスポイント 最低 : $20 / 最高 : $10,000
仮想通貨 最低 : $20 / 最高 : $100,000
銀行送金 最低 : $20 / 最高 : $10,000
| コニベット出金方法
出金方法 最低 |最高出金
アイウォレット 最低 : $40 / 最高 : なし
スティックぺイ 最低 : $40 / 最高 : なし
ヴィーナスポイント 最低 : $40 / 最高 : なし
仮想通貨 最低 : $40 / 最高 : なし
銀行送金 最低 : $40 / 最高 : なし
The troubleshooting tips provided at the end were a nice touch. It got me thinking, have you ever come across a particularly challenging situation where the usual troubleshooting steps didn’t quite solve the problem? How did you approach it?
ed pills online india
カジノ
日本にオンラインカジノおすすめランキング2024年最新版
2024おすすめのオンラインカジノ
オンラインカジノはパソコンでしか遊べないというのは、もう一昔前の話。現在はスマホやタブレットなどのモバイル端末からも、パソコンと変わらないクオリティでオンラインカジノを当たり前に楽しむことができるようになりました。
数あるモバイルカジノの中で、当サイトが厳選したトップ5カジノはこちら。
オンラインカジノおすすめ: コニベット(Konibet)
コニベットといえば、キャッシュバックや毎日もらえるリベートボーナスなど豪華ボーナスが満載!それに加えて低い出金条件も見どころです。さらにVIPレベルごとの還元率の高さも業界内で突出している点や、出金速度の速さなどトータルバランスの良さからもハイローラーの方にも好まれています。
カスタマーサポートは365日24時間稼働しているので、初心者の方にも安心してご利用いただけます。
さらに【業界初のオンラインポーカー】を導入!毎日トーナメントも開催されているので、早速参加しちゃいましょう!
RTP(還元率)公開や、入出金対応がスムーズで初心者向き
2000種類以上の豊富なゲーム数を誇り、スロットゲーム多数!
今なら$20の入金不要ボーナスと最大$650還元ボーナス!
8種類以上のライブカジノプロバイダー
業界初オンラインポーカーあり,日本利用者数No.1の安心のオンラインカジノメディア!
おすすめポイント
コニベットは、その豊富なボーナスと高還元率、そして安心のキャッシュバック制度で知られています。まず、新規登録者には入金不要の$20ボーナスが提供され、さらに初回入金時には最大$650の還元ボーナスが得られます。これらのキャンペーンはプレイヤーにとって大きな魅力となっています。
また、コニベットの特徴的な点は、VIP制度です。一度ロイヤルクラブになると、降格がなく、スロットリベートが1.5%という驚異の還元率を享受できます。これは他のオンラインカジノと比較しても非常に高い還元率です。さらに、常時週間損失キャッシュバックも行っているため、不運で負けてしまった場合でも取り返すチャンスがあります。これらの特徴から、コニベットはプレイヤーにとって非常に魅力的なオンラインカジノと言えるでしょう。
コニベット 無料会員登録をする
| コニベットのボーナス
コニベットは、新規登録者向けに20ドルの入金不要ボーナスを用意しています
コニベットカジノでは、限定で初回入金後に残高が1ドル未満になった場合、入金額の50%(最高500ドル)がキャッシュバックされる。キャッシュバック額に出金条件はないため、獲得後にすぐ出金することも可能です。
| コニベットの入金方法
入金方法 最低 / 最高入金
マスターカード 最低 : $20 / 最高 : $6,000
ジェイシービー 最低 : $20/ 最高 : $6,000
アメックス 最低 : $20 / 最高 : $6,000
アイウォレット 最低 : $20 / 最高 : $100,000
スティックペイ 最低 : $20 / 最高 : $100,000
ヴィーナスポイント 最低 : $20 / 最高 : $10,000
仮想通貨 最低 : $20 / 最高 : $100,000
銀行送金 最低 : $20 / 最高 : $10,000
| コニベット出金方法
出金方法 最低 |最高出金
アイウォレット 最低 : $40 / 最高 : なし
スティックぺイ 最低 : $40 / 最高 : なし
ヴィーナスポイント 最低 : $40 / 最高 : なし
仮想通貨 最低 : $40 / 最高 : なし
銀行送金 最低 : $40 / 最高 : なし
http://stromectol.fun/# stromectol ebay
ed pills for sale
Your words have a way of resonating deeply with your readers. Thank you for sharing your wisdom with us. Asheville loves your blog!
furosemide: furosemide 100mg – lasix side effects
Thank you for enriching our lives with your blog. Asheville sends its warmest regards!
best ed treatment
https://furosemide.guru/# lasix uses
new ed drugs
amoxicillin 500mg capsules antibiotic purchase amoxicillin online order amoxicillin online no prescription
best drugs for ed
generic ivermectin: stromectol cream – ivermectin lice oral
https://stromectol.fun/# ivermectin oral solution
top 10 ed medications comparison
50mg zoloft
brand and generic names of ed drugs
furosemide 40mg tablets for dogs dosage
ivermectin lotion: stromectol pill for humans – stromectol ebay
best treatment for erectile dysfunction
http://furosemide.guru/# generic lasix
can you take flagyl while pregnant
Your blog is a testament to your dedication and expertise. We’re proud fans from Asheville!
https://furosemide.guru/# lasix generic name
goodrx lisinopril
prescription for amoxicillin amoxicillin pills 500 mg amoxicillin for sale online
generic ed drugs cost
ed drugs online from india
http://stromectol.fun/# buy ivermectin canada
lisinopril 125 mg: online lisinopril – lisinopril metoprolol
best ed drugs over counter
Купить паспорт
Теневые рынки и их незаконные деятельности представляют существенную угрозу безопасности общества и являются объектом внимания правоохранительных органов по всему миру. В данной статье мы обсудим так называемые подпольные рынки, где возможно покупать поддельные паспорта, и какие угрозы это несет для граждан и государства.
Теневые рынки представляют собой неявные интернет-площадки, на которых торгуется разнообразной противозаконной продукцией и услугами. Среди этих услуг встречается и продажа поддельных документов, таких как паспорта. Эти рынки оперируют в теневой сфере интернета, используя криптографию и инкогнито платежные системы, чтобы оставаться непостижимыми для правоохранительных органов.
Покупка нелегального паспорта на теневых рынках представляет значительную угрозу национальной безопасности. похищение личных данных, фальсификация документов и нелегальные идентификационные материалы могут быть использованы для совершения экстремистских актов, мошенничества и дополнительных преступлений.
Правоохранительные органы в различных странах активно борются с скрытыми рынками, проводя спецоперации по выявлению и задержанию тех, кто замешан в нелегальных сделках. Однако, по мере того как технологии становятся более трудными, эти рынки могут приспосабливаться и находить новые методы обхода законов.
Для сохранения собственной безопасности от возможных опасностей, связанных с неофициальными рынками, важно проявлять осторожность при обработке своих личной информации. Это включает в себя избегать фишинговых атак, не распространять персональной информацией в недоверенных источниках и регулярно проверять свои финансовые данные.
Кроме того, общество должно быть информировано о рисках и последствиях покупки поддельных удостоверений. Это позволит создать более осознанное и ответственное отношение к вопросам безопасности и поможет в борьбе с неофициальными рынками. Поддержка законодательства, направленных на ужесточение наказаний за изготовление и сбыт поддельных удостоверений, также является важным шагом в борьбе с этими преступлениями
online ed drugs
https://stromectol.fun/# stromectol ivermectin
best ed non prescription pill
can i order prednisone prednisone 10 mg online prednisone 50 mg price
lisinopril 3.5 mg: order lisinopril from mexico – zestril generic
Your writing has a way of touching hearts and minds. We’re proud supporters of your blog from Asheville!
canada ed drugs discounts
http://stromectol.fun/# generic name for ivermectin
buy ed pills
purchase prednisone 10mg: prednisone buy online nz – prednisone 40 mg tablet
http://stromectol.fun/# ivermectin medicine
Generic Ed Drugs Cost
I just wanted to drop by and say how much I enjoy reading your blog. Asheville adores your work!
prednisone buy canada prednisone 20 tablet prednisone 50 mg buy
treatment for ed
купить клон карты
Изготовление и использование копий банковских карт является незаконной практикой, представляющей важную угрозу для безопасности финансовых систем и личных средств граждан. В данной статье мы рассмотрим риски и воздействие покупки клонов карт, а также как общество и правоохранительные органы борются с аналогичными преступлениями.
“Копии” карт — это поддельные дубликаты банковских карт, которые используются для незаконных транзакций. Основной метод создания реплик — это похищение данных с оригинальной карты и последующее кодирование этих данных на другую карту. Злоумышленники, предлагающие услуги по продаже реплик карт, обычно действуют в подпольной сфере интернета, где трудно выявить и пресечь их деятельность.
Покупка клонов карт представляет собой существенное преступление, которое может повлечь за собой трудные наказания. Покупатель также рискует стать участником мошенничества, что может привести к уголовному преследованию. Основные преступные действия в этой сфере включают в себя незаконное завладение личной информации, подделывание документов и, конечно же, экономические махинации.
Банки и органы порядка активно борются с преступлениями, связанными с репликацией карт. Банки внедряют новые технологии для выявления подозрительных транзакций, а также предлагают услуги по безопасности для своих клиентов. Правоохранительные органы ведут расследования и ловят тех, кто замешан в производстве и продаже клонов карт.
Для гарантирования безопасности важно соблюдать бережность при использовании банковских карт. Необходимо периодически проверять выписки, избегать сомнительных сделок и следить за своей персональной информацией. Знание и информированность об угрозах также являются основными средствами в борьбе с финансовыми махинациями.
В заключение, использование реплик банковских карт — это противозаконное и неприемлемое деяние, которое может привести к существенным последствиям для тех, кто вовлечен в такую практику. Соблюдение мер защиты, осведомленность о возможных угрозах и сотрудничество с силовыми структурами играют основополагающую роль в предотвращении и пресечении подобных преступлений
https://stromectol.fun/# where to buy stromectol
http://stromectol.fun/# stromectol how much it cost
best erectile dysfunction pills
prednisone 4mg: ordering prednisone – best pharmacy prednisone
cheap erectile dysfunction pills
https://furosemide.guru/# lasix for sale
best ed drugs
lasix 100mg: Buy Furosemide – lasix 100 mg
ed drug prices
lasix side effects lasix 100 mg lasix pills
In the realm of premium watches, locating a trustworthy source is paramount, and WatchesWorld stands out as a pillar of confidence and expertise. Providing an broad collection of renowned timepieces, WatchesWorld has garnered acclaim from happy customers worldwide. Let’s explore into what our customers are saying about their encounters.
Customer Testimonials:
O.M.’s Review on O.M.:
“Excellent communication and follow-up throughout the process. The watch was impeccably packed and in perfect condition. I would certainly work with this group again for a watch purchase.”
Richard Houtman’s Review on Benny:
“I dealt with Benny, who was highly assisting and courteous at all times, maintaining me regularly informed of the process. Moving forward, even though I ended up acquiring the watch locally, I would still definitely recommend Benny and the company.”
Customer’s Efficient Service Experience:
“A excellent and efficient service. Kept me up to date on the order progress.”
Featured Timepieces:
Richard Mille RM30-01 Automatic Winding with Declutchable Rotor:
Price: €285,000
Year: 2023
Reference: RM30-01 TI
Patek Philippe Complications World Time 38.5mm:
Price: €39,900
Year: 2019
Reference: 5230R-001
Rolex Oyster Perpetual Day-Date 36mm:
Price: €76,900
Year: 2024
Reference: 128238-0071
Best Sellers:
Bulgari Serpenti Tubogas 35mm:
Price: On Request
Reference: 101816 SP35C6SDS.1T
Bulgari Serpenti Tubogas 35mm (2024):
Price: €12,700
Reference: 102237 SP35C6SPGD.1T
Cartier Panthere Medium Model:
Price: €8,390
Year: 2023
Reference: W2PN0007
Our Experts Selection:
Cartier Panthere Small Model:
Price: €11,500
Year: 2024
Reference: W3PN0006
Omega Speedmaster Moonwatch 44.25 mm:
Price: €9,190
Year: 2024
Reference: 304.30.44.52.01.001
Rolex Oyster Perpetual Cosmograph Daytona 40mm:
Price: €28,500
Year: 2023
Reference: 116500LN-0002
Rolex Oyster Perpetual 36mm:
Price: €13,600
Year: 2023
Reference: 126000-0006
Why WatchesWorld:
WatchesWorld is not just an online platform; it’s a dedication to customized service in the world of high-end watches. Our team of watch experts prioritizes trust, ensuring that every customer makes an informed decision.
Our Commitment:
Expertise: Our group brings unparalleled understanding and insight into the realm of luxury timepieces.
Trust: Confidence is the basis of our service, and we prioritize transparency in every transaction.
Satisfaction: Customer satisfaction is our paramount goal, and we go the additional step to ensure it.
When you choose WatchesWorld, you’re not just buying a watch; you’re investing in a seamless and trustworthy experience. Explore our collection, and let us assist you in discovering the ideal timepiece that reflects your taste and elegance. At WatchesWorld, your satisfaction is our time-tested commitment
https://furosemide.guru/# lasix uses
where to buy ed drugs online
Watches World
In the world of premium watches, finding a dependable source is essential, and WatchesWorld stands out as a symbol of confidence and knowledge. Presenting an extensive collection of prestigious timepieces, WatchesWorld has garnered acclaim from content customers worldwide. Let’s dive into what our customers are saying about their encounters.
Customer Testimonials:
O.M.’s Review on O.M.:
“Excellent communication and follow-up throughout the process. The watch was flawlessly packed and in mint condition. I would certainly work with this group again for a watch purchase.”
Richard Houtman’s Review on Benny:
“I dealt with Benny, who was extremely helpful and courteous at all times, maintaining me regularly informed of the process. Moving forward, even though I ended up sourcing the watch locally, I would still definitely recommend Benny and the company.”
Customer’s Efficient Service Experience:
“A highly efficient and swift service. Kept me up to date on the order progress.”
Featured Timepieces:
Richard Mille RM30-01 Automatic Winding with Declutchable Rotor:
Price: €285,000
Year: 2023
Reference: RM30-01 TI
Patek Philippe Complications World Time 38.5mm:
Price: €39,900
Year: 2019
Reference: 5230R-001
Rolex Oyster Perpetual Day-Date 36mm:
Price: €76,900
Year: 2024
Reference: 128238-0071
Best Sellers:
Bulgari Serpenti Tubogas 35mm:
Price: On Request
Reference: 101816 SP35C6SDS.1T
Bulgari Serpenti Tubogas 35mm (2024):
Price: €12,700
Reference: 102237 SP35C6SPGD.1T
Cartier Panthere Medium Model:
Price: €8,390
Year: 2023
Reference: W2PN0007
Our Experts Selection:
Cartier Panthere Small Model:
Price: €11,500
Year: 2024
Reference: W3PN0006
Omega Speedmaster Moonwatch 44.25 mm:
Price: €9,190
Year: 2024
Reference: 304.30.44.52.01.001
Rolex Oyster Perpetual Cosmograph Daytona 40mm:
Price: €28,500
Year: 2023
Reference: 116500LN-0002
Rolex Oyster Perpetual 36mm:
Price: €13,600
Year: 2023
Reference: 126000-0006
Why WatchesWorld:
WatchesWorld is not just an internet platform; it’s a dedication to customized service in the world of high-end watches. Our group of watch experts prioritizes trust, ensuring that every client makes an informed decision.
Our Commitment:
Expertise: Our team brings unparalleled understanding and insight into the realm of high-end timepieces.
Trust: Trust is the foundation of our service, and we prioritize openness in every transaction.
Satisfaction: Customer satisfaction is our paramount goal, and we go the extra mile to ensure it.
When you choose WatchesWorld, you’re not just buying a watch; you’re committing in a effortless and trustworthy experience. Explore our range, and let us assist you in finding the ideal timepiece that embodies your taste and sophistication. At WatchesWorld, your satisfaction is our time-tested commitment
top erection pills
lasix tablet: Buy Lasix – furosemide
best ed medications
https://furosemide.guru/# lasix furosemide 40 mg
best treatment for ed in india
lasix generic name Buy Lasix No Prescription lasix 20 mg
best medication for ed
http://amoxil.cheap/# amoxicillin 500mg capsules uk
http://furosemide.guru/# furosemide 100 mg
lisinopril generic 10 mg: 50 mg lisinopril – lisinopril 30 mg cost
best non prescription ed supplements
kegunaan glucophage
impotence pills over the counter
http://lisinopril.top/# 16 lisinopril
erectile dysfunction pills from india
lasix use
lasix generic: Buy Furosemide – furosemide 40mg
ivermectin 12 mg ivermectin 6mg tablet for lice buy ivermectin for humans uk
http://amoxil.cheap/# buying amoxicillin online
best ed pills non prescription
zithromax z pak sinus infection
maximum dose of gabapentin
cheap erectile dysfunction pill
ed drugs for men
https://buyprednisone.store/# prednisone 1 mg tablet
lasix furosemide: lasix for sale – lasix 40 mg
online ed drugs for purchase
Your blog is a must-read for anyone seeking inspiration and knowledge. Asheville is lucky to have you!
https://buyprednisone.store/# by prednisone w not prescription
erectile dysfunction pills from india
zestoretic 20 25mg lisinopril diuretic zestril 40 mg tablet
In the realm of premium watches, finding a reliable source is paramount, and WatchesWorld stands out as a pillar of trust and expertise. Presenting an extensive collection of prestigious timepieces, WatchesWorld has garnered acclaim from happy customers worldwide. Let’s delve into what our customers are saying about their experiences.
Customer Testimonials:
O.M.’s Review on O.M.:
“Excellent communication and follow-up throughout the process. The watch was perfectly packed and in pristine condition. I would certainly work with this group again for a watch purchase.”
Richard Houtman’s Review on Benny:
“I dealt with Benny, who was highly helpful and courteous at all times, keeping me regularly informed of the procedure. Moving forward, even though I ended up sourcing the watch locally, I would still definitely recommend Benny and the company.”
Customer’s Efficient Service Experience:
“A highly efficient and swift service. Kept me up to date on the order progress.”
Featured Timepieces:
Richard Mille RM30-01 Automatic Winding with Declutchable Rotor:
Price: €285,000
Year: 2023
Reference: RM30-01 TI
Patek Philippe Complications World Time 38.5mm:
Price: €39,900
Year: 2019
Reference: 5230R-001
Rolex Oyster Perpetual Day-Date 36mm:
Price: €76,900
Year: 2024
Reference: 128238-0071
Best Sellers:
Bulgari Serpenti Tubogas 35mm:
Price: On Request
Reference: 101816 SP35C6SDS.1T
Bulgari Serpenti Tubogas 35mm (2024):
Price: €12,700
Reference: 102237 SP35C6SPGD.1T
Cartier Panthere Medium Model:
Price: €8,390
Year: 2023
Reference: W2PN0007
Our Experts Selection:
Cartier Panthere Small Model:
Price: €11,500
Year: 2024
Reference: W3PN0006
Omega Speedmaster Moonwatch 44.25 mm:
Price: €9,190
Year: 2024
Reference: 304.30.44.52.01.001
Rolex Oyster Perpetual Cosmograph Daytona 40mm:
Price: €28,500
Year: 2023
Reference: 116500LN-0002
Rolex Oyster Perpetual 36mm:
Price: €13,600
Year: 2023
Reference: 126000-0006
Why WatchesWorld:
WatchesWorld is not just an web-based platform; it’s a promise to personalized service in the realm of high-end watches. Our staff of watch experts prioritizes trust, ensuring that every client makes an well-informed decision.
Our Commitment:
Expertise: Our group brings matchless knowledge and insight into the world of high-end timepieces.
Trust: Confidence is the basis of our service, and we prioritize openness in every transaction.
Satisfaction: Customer satisfaction is our ultimate goal, and we go the extra mile to ensure it.
When you choose WatchesWorld, you’re not just buying a watch; you’re committing in a smooth and reliable experience. Explore our collection, and let us assist you in finding the ideal timepiece that embodies your taste and sophistication. At WatchesWorld, your satisfaction is our time-tested commitment
medicine for erectile
amoxicillin without a doctors prescription: can i buy amoxicillin over the counter in australia – can i buy amoxicillin over the counter
карты на обнал
Использование платежных карт является неотъемлемой частью современного общества. Карты предоставляют удобство, секретность и широкие возможности для проведения финансовых операций. Однако, кроме легального использования, существует темная сторона — обналичивание карт, когда карты используются для вывода наличных средств без согласия владельца. Это является преступным деянием и влечет за собой строгие санкции.
Вывод наличных средств с карт представляет собой манипуляции, направленные на извлечение наличных средств с банковской карты, необходимые для того, чтобы обойти защитные меры и оповещений, предусмотренных банком. К сожалению, такие преступные действия существуют, и они могут привести к потере средств для банков и клиентов.
Одним из методов обналичивания карт является использование технических хитростей, таких как скимминг. Магнитный обман — это процесс, при котором злоумышленники устанавливают механизмы на банкоматах или терминалах оплаты, чтобы считывать информацию с магнитной полосы пластиковой карты. Полученные данные затем используются для создания копии карты или проведения интернет-транзакций.
Другим часто используемым способом является мошенничество, когда мошенники отправляют недобросовестные письма или создают фейковые сайты, имитирующие банковские ресурсы, с целью получения конфиденциальной информации от клиентов.
Для противостояния выводу наличных средств банки вводят разнообразные меры. Это включает в себя усовершенствование защитных систем, введение двухэтапной проверки, мониторинг транзакций и подготовка клиентов о техниках предотвращения мошенничества.
Клиентам также следует проявлять активность в гарантировании защиты своих карт и данных. Это включает в себя периодическое изменение паролей, контроль банковских выписок, а также внимательное отношение к подозрительным транзакциям.
Вывод наличных средств — это тяжкое преступление, которое наносит ущерб не только банкам, но и обществу в целом. Поэтому важно соблюдать бдительность при пользовании банковскими картами, быть осведомленным о методах мошенничества и соблюдать меры безопасности для предотвращения потери средств
https://buyprednisone.store/# prednisone 20 mg purchase
ed pills canada
http://amoxil.cheap/# can i buy amoxicillin over the counter in australia
Your blog is a true gift to the world. We’re big fans from Asheville!
https://lisinopril.top/# buy lisinopril without prescription
lasix furosemide 40 mg: Over The Counter Lasix – furosemida
furosemida Buy Lasix No Prescription lasix 100 mg tablet
https://amoxil.cheap/# how much is amoxicillin prescription
Watches World
In the realm of high-end watches, locating a dependable source is paramount, and WatchesWorld stands out as a symbol of confidence and knowledge. Offering an wide collection of prestigious timepieces, WatchesWorld has collected acclaim from satisfied customers worldwide. Let’s delve into what our customers are saying about their experiences.
Customer Testimonials:
O.M.’s Review on O.M.:
“Very good communication and aftercare throughout the process. The watch was flawlessly packed and in perfect condition. I would certainly work with this team again for a watch purchase.”
Richard Houtman’s Review on Benny:
“I dealt with Benny, who was highly assisting and courteous at all times, preserving me regularly informed of the procedure. Moving forward, even though I ended up sourcing the watch locally, I would still definitely recommend Benny and the company.”
Customer’s Efficient Service Experience:
“A very good and swift service. Kept me up to date on the order progress.”
Featured Timepieces:
Richard Mille RM30-01 Automatic Winding with Declutchable Rotor:
Price: €285,000
Year: 2023
Reference: RM30-01 TI
Patek Philippe Complications World Time 38.5mm:
Price: €39,900
Year: 2019
Reference: 5230R-001
Rolex Oyster Perpetual Day-Date 36mm:
Price: €76,900
Year: 2024
Reference: 128238-0071
Best Sellers:
Bulgari Serpenti Tubogas 35mm:
Price: On Request
Reference: 101816 SP35C6SDS.1T
Bulgari Serpenti Tubogas 35mm (2024):
Price: €12,700
Reference: 102237 SP35C6SPGD.1T
Cartier Panthere Medium Model:
Price: €8,390
Year: 2023
Reference: W2PN0007
Our Experts Selection:
Cartier Panthere Small Model:
Price: €11,500
Year: 2024
Reference: W3PN0006
Omega Speedmaster Moonwatch 44.25 mm:
Price: €9,190
Year: 2024
Reference: 304.30.44.52.01.001
Rolex Oyster Perpetual Cosmograph Daytona 40mm:
Price: €28,500
Year: 2023
Reference: 116500LN-0002
Rolex Oyster Perpetual 36mm:
Price: €13,600
Year: 2023
Reference: 126000-0006
Why WatchesWorld:
WatchesWorld is not just an web-based platform; it’s a promise to personalized service in the realm of high-end watches. Our group of watch experts prioritizes trust, ensuring that every client makes an knowledgeable decision.
Our Commitment:
Expertise: Our group brings exceptional knowledge and insight into the realm of high-end timepieces.
Trust: Trust is the basis of our service, and we prioritize transparency in every transaction.
Satisfaction: Client satisfaction is our paramount goal, and we go the additional step to ensure it.
When you choose WatchesWorld, you’re not just buying a watch; you’re committing in a smooth and trustworthy experience. Explore our collection, and let us assist you in discovering the perfect timepiece that mirrors your taste and elegance. At WatchesWorld, your satisfaction is our time-tested commitment
We’re a group of volunteers and opening a brand new scheme in our community. Your site offered us with helpful information to paintings on. You have done a formidable process and our whole group can be thankful to you.
Thanks for finally talking about >Why go large with Data for Deep Learning?
<Loved it!
online pharmacies for ed meds https://fintryides.com/
buy erection pills https://fintryides.com/
top ed pills https://fintryides.com/
what is amoxicillin and clavulanate potassium
best non prescription erection pills https://fintryides.com/
generic ed drugs india https://fintryides.com/
cephalexin 500mg for dogs dosage chart
buying ed pills https://fintryides.com/
https://indianph.xyz/# reputable indian online pharmacy
buy prescription drugs from india
world pharmacy india indian pharmacy online india pharmacy
impotence pills over the counter https://fintryides.com/
http://indianph.com/# indian pharmacy
Online medicine home delivery
best online pharmacy india top 10 online pharmacy in india top 10 online pharmacy in india
gabapentin maximum dosage for sleep
compare ed drugs https://fintryides.com/
escitalopram 5mg tablets
https://indianph.xyz/# best india pharmacy
india online pharmacy
http://indianph.xyz/# buy prescription drugs from india
non prescription male enhancement pills https://fintryides.com/
http://indianph.com/# top 10 online pharmacy in india
india online pharmacy
Hello there! This post could not be written much better!
Looking through this post reminds me of my previous roommate!
He constantly kept talking about this. I most certainly will forward
this article to him. Fairly certain he will have a great read.
Thanks for sharing!
india pharmacy п»їlegitimate online pharmacies india indian pharmacy
linetogel
Темная сторона интернета – скрытая зона всемирной паутины, избегающая взоров стандартных поисковых систем и требующая дополнительных средств для доступа. Этот скрытый ресурс сети обильно насыщен ресурсами, предоставляя доступ к разношерстным товарам и услугам через свои даркнет списки и индексы. Давайте подробнее рассмотрим, что представляют собой эти списки и какие тайны они сокрывают.
Даркнет Списки: Ворота в Тайный Мир
Индексы веб-ресурсов в темной части интернета – это своего рода врата в неощутимый мир интернета. Каталоги и индексы веб-ресурсов в даркнете, они позволяют пользователям отыскивать разношерстные услуги, товары и информацию. Варьируя от форумов и магазинов до ресурсов, уделяющих внимание аспектам анонимности и криптовалютам, эти списки предоставляют нам возможность заглянуть в таинственный мир даркнета.
Категории и Возможности
Теневой Рынок:
Даркнет часто связывается с теневым рынком, где доступны самые разные товары и услуги – от наркотиков и оружия до похищенной информации и помощи наемных убийц. Реестры ресурсов в данной категории облегчают пользователям находить подходящие предложения без лишних усилий.
Форумы и Сообщества:
Даркнет также предоставляет площадку для анонимного общения. Форумы и сообщества, указанные в каталогах даркнета, охватывают различные темы – от информационной безопасности и взлома до политики и философии.
Информационные Ресурсы:
На даркнете есть ресурсы, предоставляющие сведения и руководства по обходу ограничений, защите конфиденциальности и другим темам, которые могут быть интересны тем, кто хочет остаться анонимным.
Безопасность и Осторожность
Несмотря на скрытность и свободу, даркнет полон рисков. Мошенничество, кибератаки и незаконные сделки являются неотъемлемой частью этого мира. Взаимодействуя с реестрами даркнета, пользователи должны соблюдать высший уровень бдительности и придерживаться мер безопасности.
Заключение
Даркнет списки – это врата в неизведанный мир, где хранятся тайны и возможности. Однако, как и в любой неизведанной территории, путешествие в темную сеть требует особой бдительности и знаний. Анонимность не всегда гарантирует безопасность, и использование темной сети требует осмысленного подхода. Независимо от ваших интересов – будь то технические детали в области кибербезопасности, поиск необычных товаров или исследование новых возможностей в интернете – реестры даркнета предоставляют ключ
https://indianph.xyz/# india pharmacy mail order
reputable indian online pharmacy
список сайтов даркнет
Темная сторона интернета – скрытая сфера интернета, избегающая взоров обычных поисковых систем и требующая дополнительных средств для доступа. Этот анонимный ресурс сети обильно насыщен платформами, предоставляя доступ к разношерстным товарам и услугам через свои каталоги и каталоги. Давайте подробнее рассмотрим, что представляют собой эти списки и какие тайны они хранят.
Даркнет Списки: Окна в Тайный Мир
Даркнет списки – это вид порталы в неощутимый мир интернета. Каталоги и индексы веб-ресурсов в даркнете, они позволяют пользователям отыскивать различные услуги, товары и информацию. Варьируя от форумов и магазинов до ресурсов, уделяющих внимание аспектам анонимности и криптовалютам, эти списки предоставляют нам шанс заглянуть в таинственный мир даркнета.
Категории и Возможности
Теневой Рынок:
Даркнет часто связывается с теневым рынком, где доступны самые разные товары и услуги – от психоактивных веществ и стрелкового оружия до краденых данных и услуг наемных убийц. Реестры ресурсов в данной категории облегчают пользователям находить нужные предложения без лишних усилий.
Форумы и Сообщества:
Даркнет также предоставляет площадку для анонимного общения. Форумы и сообщества, указанные в каталогах даркнета, затрагивают различные темы – от информационной безопасности и взлома до политических вопросов и философских идей.
Информационные Ресурсы:
На даркнете есть ресурсы, предоставляющие данные и указания по обходу ограничений, защите конфиденциальности и другим темам, интересным тем, кто хочет сохранить свою конфиденциальность.
Безопасность и Осторожность
Несмотря на анонимность и свободу, даркнет не лишен рисков. Мошенничество, кибератаки и незаконные сделки присущи этому миру. Взаимодействуя с списками ресурсов в темной сети, пользователи должны соблюдать высший уровень бдительности и придерживаться мер безопасности.
Заключение
Даркнет списки – это врата в неизведанный мир, где хранятся тайны и возможности. Однако, как и в любой неизведанной территории, путешествие в темную сеть требует особой бдительности и знаний. Не всегда можно полагаться на анонимность, и использование даркнета требует осмысленного подхода. Независимо от ваших интересов – будь то технические детали в области кибербезопасности, поиск необычных товаров или исследование новых возможностей в интернете – списки даркнета предоставляют ключ
brand and generic names of ed drugs https://fintryides.com/
https://xn—–7kccgclceaf3d0apdeeefre0dt2w.xn--p1ai/
Даркнет сайты
Темная сторона интернета – неведомая сфера всемирной паутины, избегающая взоров обыденных поисковых систем и требующая эксклюзивных средств для доступа. Этот скрытый уголок сети обильно насыщен сайтами, предоставляя доступ к различным товарам и услугам через свои перечни и справочники. Давайте ближе рассмотрим, что представляют собой эти реестры и какие тайны они хранят.
Даркнет Списки: Окна в Скрытый Мир
Даркнет списки – это вид проходы в скрытый мир интернета. Реестры и справочники веб-ресурсов в даркнете, они позволяют пользователям отыскивать разношерстные услуги, товары и информацию. Варьируя от форумов и магазинов до ресурсов, уделяющих внимание аспектам анонимности и криптовалютам, эти перечни предоставляют нам возможность заглянуть в таинственный мир даркнета.
Категории и Возможности
Теневой Рынок:
Даркнет часто связывается с теневым рынком, где доступны самые разные товары и услуги – от психоактивных веществ и стрелкового оружия до похищенной информации и помощи наемных убийц. Реестры ресурсов в подобной категории облегчают пользователям находить подходящие предложения без лишних усилий.
Форумы и Сообщества:
Даркнет также предоставляет площадку для анонимного общения. Форумы и сообщества, указанные в каталогах даркнета, затрагивают различные темы – от кибербезопасности и хакерства до политики и философии.
Информационные Ресурсы:
На даркнете есть ресурсы, предоставляющие сведения и руководства по обходу ограничений, защите конфиденциальности и другим вопросам, которые могут заинтересовать тех, кто стремится сохранить свою анонимность.
Безопасность и Осторожность
Несмотря на неизвестность и свободу, даркнет не лишен опасностей. Мошенничество, кибератаки и незаконные сделки присущи этому миру. Взаимодействуя с даркнет списками, пользователи должны соблюдать высший уровень бдительности и придерживаться мер безопасности.
Заключение
Даркнет списки – это ключ к таинственному миру, где хранятся тайны и возможности. Однако, как и в любой неизведанной территории, путешествие в даркнет требует особой осторожности и знания. Не всегда можно полагаться на анонимность, и использование темной сети требует осознанного подхода. Независимо от ваших интересов – будь то технические аспекты кибербезопасности, поиск уникальных товаров или исследование новых граней интернета – реестры даркнета предоставляют ключ
Теневой интернет – это часть интернета, которая остается скрытой от обычных поисковых систем и требует специального программного обеспечения для доступа. В этой анонимной зоне сети существует масса ресурсов, включая различные списки и каталоги, предоставляющие доступ к разнообразным услугам и товарам. Давайте рассмотрим, что представляет собой каталог даркнета и какие тайны скрываются в его глубинах.
Теневые каталоги: Врата в анонимность
Для начала, что такое теневой каталог? Это, по сути, каталоги или индексы веб-ресурсов в темной части интернета, которые позволяют пользователям находить нужные услуги, товары или информацию. Эти списки могут варьироваться от форумов и торговых площадок до ресурсов, специализирующихся на различных аспектах анонимности и криптовалют.
Категории и Возможности
Черный Рынок:
Даркнет часто ассоциируется с рынком андеграунда, где можно найти различные товары и услуги, включая наркотики, оружие, украденные данные и даже услуги наемных убийц. Списки таких ресурсов позволяют пользователям без труда находить подобные предложения.
Форумы и Группы:
Темная сторона интернета также предоставляет платформы для анонимного общения. Чаты и группы на теневых каталогах могут заниматься обсуждением тем от кибербезопасности и хакерства до политики и философии.
Информационные ресурсы:
Есть ресурсы, предоставляющие информацию и инструкции по обходу цензуры, защите конфиденциальности и другим темам, интересным пользователям, стремящимся сохранить анонимность.
Безопасность и Осторожность
При всей своей анонимности и свободе действий темная сторона интернета также несет риски. Мошенничество, кибератаки и незаконные сделки становятся частью этого мира. Пользователям необходимо проявлять максимальную осторожность и соблюдать меры безопасности при взаимодействии с списками теневых ресурсов.
Заключение: Врата в Неизведанный Мир
Теневые каталоги предоставляют доступ к скрытым уголкам сети, где сокрыты тайны и возможности. Однако, как и в любой неизведанной территории, важно помнить о возможных рисках и осознанно подходить к использованию даркнета. Анонимность не всегда гарантирует безопасность, и путешествие в этот мир требует особой осторожности и знания.
Независимо от того, интересуетесь ли вы техническими аспектами интернет-безопасности, ищете уникальные товары или просто исследуете новые грани интернета, даркнет списки предоставляют ключ
ed pills online india https://fintryides.com/
Даркнет – скрытая сфера интернета, избегающая взоров стандартных поисковых систем и требующая дополнительных средств для доступа. Этот скрытый уголок сети обильно насыщен ресурсами, предоставляя доступ к разнообразным товарам и услугам через свои даркнет списки и индексы. Давайте подробнее рассмотрим, что представляют собой эти списки и какие тайны они сокрывают.
Даркнет Списки: Окна в Тайный Мир
Даркнет списки – это своего рода порталы в скрытый мир интернета. Перечни и указатели веб-ресурсов в даркнете, они позволяют пользователям отыскивать разношерстные услуги, товары и информацию. Варьируя от форумов и магазинов до ресурсов, уделяющих внимание аспектам анонимности и криптовалютам, эти перечни предоставляют нам шанс заглянуть в неизведанный мир даркнета.
Категории и Возможности
Теневой Рынок:
Даркнет часто ассоциируется с теневым рынком, где доступны самые разные товары и услуги – от наркотиков и оружия до украденных данных и услуг наемных убийц. Списки ресурсов в данной категории облегчают пользователям находить нужные предложения без лишних усилий.
Форумы и Сообщества:
Даркнет также предоставляет площадку для анонимного общения. Форумы и сообщества, представленные в реестрах даркнета, затрагивают широкий спектр – от кибербезопасности и хакерства до политических аспектов и философских концепций.
Информационные Ресурсы:
На даркнете есть ресурсы, предоставляющие информацию и инструкции по обходу ограничений, защите конфиденциальности и другим темам, интересным тем, кто хочет сохранить свою конфиденциальность.
Безопасность и Осторожность
Несмотря на неизвестность и свободу, даркнет полон опасностей. Мошенничество, кибератаки и незаконные сделки присущи этому миру. Взаимодействуя с списками ресурсов в темной сети, пользователи должны соблюдать предельную осмотрительность и придерживаться мер безопасности.
Заключение
Списки даркнета – это путь в неизведанный мир, где скрыты секреты и возможности. Однако, как и в любой неизведанной территории, путешествие в даркнет требует особой внимания и знаний. Не всегда анонимность приносит безопасность, и использование темной сети требует осмысленного подхода. Независимо от ваших интересов – будь то технические аспекты кибербезопасности, поиск уникальных товаров или исследование новых граней интернета – реестры даркнета предоставляют ключ
https://indianph.com/# Online medicine order
indian pharmacies safe
ed drugs without prescription https://fintryides.com/
https://indianph.com/# cheapest online pharmacy india
mail order pharmacy india
best india pharmacy online pharmacy india indianpharmacy com
brand and generic names of ed drugs https://fintryides.com/
https://indianph.com/# indian pharmacies safe
india pharmacy mail order
generic ed drugs https://fintryides.com/
linetogel
erectile dysfunction pills https://fintryides.com/
https://indianph.com/# indianpharmacy com
http://indianph.com/# online pharmacy india
top 10 pharmacies in india
low cost male enhancement pills https://fintryides.com/
best online pharmacy for ed drugs https://fintryides.com/
generic ed drugs https://patriciaalanpaen.wordpress.com/
female ed meds https://patriciaalanpaen.wordpress.com/
what is ciprofloxacin 500mg used for
Pingback: grandpashabet
how much do ed drugs cost https://patriciaalanpaen.wordpress.com/
st666
ed dysfunction treatment https://patriciaalanpaen.wordpress.com/
non prescription male enhancement pills https://patriciaalanpaen.wordpress.com/
Your point of view caught my eye and was very interesting. Thanks. I have a question for you. https://www.binance.info/join?ref=FIHEGIZ8
where can i get diflucan over the counter buy diflucan online diflucan uk price
low cost ed drugs https://patriciaalanpaen.wordpress.com/
ed pills near me https://patriciaalanpaen.wordpress.com/
doxycycline 150 mg: price of doxycycline – cheap doxycycline online
is bactrim good for a sinus infection
https://cytotec24.com/# buy cytotec
list of erectile dysfunction drugs https://patriciaalanpaen.wordpress.com/
casino
prescription for ed online https://patriciaalanpaen.wordpress.com/
st666
http://doxycycline.auction/# doxy 200
ed pills canada https://patriciaalanpaen.wordpress.com/
diflucan without get a prescription online: diflucan cap 150 mg – diflucan without a prescription
diflucan cost uk cost of diflucan diflucan 1 pill
top ed pills https://patriciaalanpaen.wordpress.com/
https://cipro.guru/# antibiotics cipro
new drugs for ed https://patriciaalanpaen.wordpress.com/
cephalexin for impetigo
buying ed drugs online https://patriciaalanpaen.wordpress.com/
Hello, There’s no doubt that your website could possibly be having internet browser compatibility issues.
Whenever I look at your blog in Safari, it looks fine however when opening in IE,
it has some overlapping issues. I simply wanted to provide
you with a quick heads up! Besides that, wonderful site!
Cytotec 200mcg price: buy cytotec – cytotec buy online usa
http://cipro.guru/# cipro online no prescription in the usa
Nicely put. Many thanks.
best online pharmacy pharmacies near me canada pharmacies online prescriptions
http://cytotec24.shop/# buy cytotec pills
best treatment for erectile dysfunction https://patriciaalanpaen.wordpress.com/
ciprofloxacin buy generic ciprofloxacin cipro online no prescription in the usa
linetogel
best ed drugs https://patriciaalanpaen.wordpress.com/
You made your point quite nicely.!
canadian pharmacy drugs online canadian pharmacy canada drugs pharmacy online
https://nolvadex.guru/# generic tamoxifen
natural ed medications https://patriciaalanpaen.wordpress.com/
can i buy diflucan in mexico: diflucan generic costs – diflucan rx online
best ed drugs over counter https://patriciaalanpaen.wordpress.com/
This is nicely expressed! .
canadian pharmacies-24h list of approved canadian pharmacies online pharmacy without a prescription
https://doxycycline.auction/# doxycycline 100mg tablets
ed treatment in india https://patriciaalanpaen.wordpress.com/
Столешницы из искусственного камня москва
buy misoprostol over the counter cytotec pills buy online buy cytotec pills
erectile dysfunction pills https://patriciaalanpaen.wordpress.com/
https://diflucan.pro/# can i buy diflucan over the counter in canada
best ed pills that work https://patriciaalanpaen.wordpress.com/
перевод документов
generic ed pills from india https://patriciaalanpaen.wordpress.com/
purchase cytotec: buy cytotec online fast delivery – buy cytotec over the counter
https://doxycycline.auction/# buy cheap doxycycline
mens erection pills https://patriciaalanpaen.wordpress.com/
Gambling
http://cytotec24.com/# buy cytotec
diflucan online purchase diflucan 100 mg tab diflucan pills for sale
best non prescription ed supplements https://patriciaalanpaen.wordpress.com/
Pingback: grandpashabet
заливы без предоплат
В последнее время стали популярными запросы о заливах без предоплат – предложениях, предоставляемых в сети, где клиентам обещают осуществление заказа или поставку товара перед оплаты. Однако, за данной кажущейся выгодой могут быть скрываться серьезные риски и негативные последствия.
Привлекательность безоплатных переводов:
Привлекательность идеи заливов без предоплат заключается в том, что заказчики получают услугу или продукцию, не внося первоначально средства. Данное условие может показаться прибыльным и удобным, особенно для таких, кто не хочет ставить под риск финансами или претерпеть мошенничеством. Однако, до того как вовлечься в сферу бесплатных переводов, необходимо принять во внимание ряд важных аспектов.
Опасности и негативные последствия:
Обман и недобросовестные действия:
За порядочными проектами без предоплат могут скрываться мошенники, приготовленные использовать уважение клиентов. Попав в их ловушку, вы рискуете лишиться не только, услуги но и денег.
Сниженное качество выполнения услуг:
Без гарантии исполнителю может быть недостаточно мотивации предоставить высококачественную работу или продукт. В итоге заказчик останется недовольным, а исполнитель не столкнется значительными санкциями.
Утрата данных и защиты:
При передаче личных сведений или информации о банковских счетах для бесплатных переводов существует опасность утечки данных и последующего ихнего неправомерного использования.
Советы по надежным заливам:
Поиск информации:
До выбором бесплатных переводов проведите тщательное анализ исполнителя. Отзывы, рейтинговые оценки и репутация могут хорошим критерием.
Оплата вперед:
По возможности, постарайтесь договориться часть вознаграждения вперед. Такой подход может сделать сделку более безопасной и обеспечит вам больший объем контроля.
Проверенные платформы:
Предпочитайте применению проверенных площадок и систем для переводов. Это уменьшит риск обмана и увеличит вероятность на получение качественных услуг.
Итог:
Несмотря на видимую привлекательность, заливы без предварительной оплаты несут в себе опасности и потенциальные опасности. Осторожность и осторожность при выборе поставщика или площадки могут предупредить нежелательные последствия. Важно запомнить, что бесплатные заливы могут стать источником проблем, и разумное принятие решений способствует предотвратить потенциальных неприятностей
where to buy ed drugs online https://patriciaalanpaen.wordpress.com/
https://cytotec24.shop/# buy cytotec pills
Experience the magic of online gaming at our Mexican casino site. With enchanting themes and captivating gameplay, you’ll be transported to a world of fantasy and fun. casino caliente tienes todo lo mejor.
best ed pills non prescription https://patriciaalanpaen.wordpress.com/
Скрытая сфера – это таинственная и непознанная территория интернета, где действуют свои правила, перспективы и угрозы. Каждый день в мире теневой сети случаются инциденты, о которых стандартные пользователи могут лишь догадываться. Давайте рассмотрим последние новости из теневой зоны, отражающие современные тенденции и инциденты в этом таинственном уголке сети.”
Тенденции и События:
“Эволюция Средств и Безопасности:
В даркнете постоянно развиваются технологии и подходы защиты. Новости о появлении улучшенных платформ кодирования, анонимизации и защиты персональной информации свидетельствуют о желании пользователей и разработчиков к обеспечению надежной обстановки.”
“Новые Теневые Рынки:
В соответствии с динамикой запроса и предложений, в теневом интернете появляются совершенно новые коммерческие площадки. Новости о запуске онлайн-рынков предоставляют участникам разнообразные варианты для купли-продажи товарами и услугами
Покупка удостоверения личности в интернет-магазине – это незаконное и рискованное поступок, которое может послужить причиной к серьезным последствиям для граждан. Вот несколько сторон, о которые необходимо запомнить:
Незаконность: Приобретение удостоверения личности в онлайн магазине является нарушением законодательства. Имение фальшивым документом способно сопровождаться криминальную ответственность и серьезные наказания.
Риски личной безопасности: Обстоятельство использования фальшивого удостоверения личности может подвергнуть угрозу личную секретность. Личности, пользующиеся фальшивыми удостоверениями, способны оказаться целью преследования со со стороны правоохранительных органов.
Финансовые убытки: Зачастую мошенники, продающие фальшивыми удостоверениями, могут использовать вашу информацию для мошенничества, что приведёт к финансовым потерям. Личные или материальные данные могут быть применены в преступных намерениях.
Трудности при путешествиях: Поддельный удостоверение личности может стать распознан при переезде перейти границы или при взаимодействии с государственными инстанциями. Такое обстоятельство может послужить причиной аресту, депортации или иным серьезным сложностям при перемещении.
Утрата доверия и престижа: Применение фальшивого паспорта способно послужить причиной к потере доверительности со со стороны сообщества и работодателей. Такая обстановка способна негативно сказаться на ваши репутацию и карьерные возможности.
Вместо того, чтобы рисковать собственной независимостью, безопасностью и репутацией, рекомендуется соблюдать законодательство и использовать официальными путями для получения документов. Эти предоставляют защиту ваших законных интересов и гарантируют секретность ваших информации. Незаконные практики могут повлечь за собой неожиданные и негативные ситуации, порождая серьезные проблемы для вас и ваших сообщества
non prescription erection pills https://patriciaalanpaen.wordpress.com/
http://cipro.guru/# ciprofloxacin generic
даркнет 2024
Теневой интернет 2024: Скрытые взгляды цифровой среды
С инициации даркнет представлял собой сферу веба, где тайна и тень становились обыденностью. В 2024 году этот темный мир развивается, предоставляя дополнительные требования и опасности для сообщества в сети. Рассмотрим, какие тенденции и модификации предстоят нас в даркнете 2024.
Технологический прогресс и Повышение скрытности
С прогрессом техники, средства обеспечения анонимности в даркнете превращаются в сложнее и эффективными. Использование цифровых валют, новых алгоритмов шифрования и децентрализованных сетей делает отслеживание за поведением участников более трудным для правоохранительных органов.
Рост специализированных рынков
Темные рынки, специализирующиеся на различных товарах и услугах, продвигаются вперед расширяться. Наркотики, военные припасы, хакерские инструменты, персональная информация – спектр товаров бывает все более разнообразным. Это создает сложность для силовых структур, который сталкивается с задачей адаптироваться к постоянно меняющимся обстоятельствам преступной деятельности.
Опасности кибербезопасности для непрофессионалов
Сервисы проката хакеров и обманные планы продолжают существовать активными в даркнете. Люди, не связанные с преступностью попадают в руки объектом для преступников в сети, желающих получить доступ к персональной информации, банковским счетам и иных секретных данных.
Перспективы цифровой реальности в даркнете
С прогрессом техники цифровой симуляции, даркнет может войти в совершенно новую фазу, предоставляя участникам более реалистичные и вовлекающие виртуальные пространства. Это может включать в себя дополнительными видами нелегальных действий, такими как цифровые рынки для обмена цифровыми товарами.
Противостояние силам защиты
Силы безопасности совершенствуют свои технические средства и методы борьбы с теневым интернетом. Совместные усилия стран и международных организаций направлены на предотвращение киберпреступности и противостояние новым вызовам, которые возникают в связи с ростом скрытого веба.
Вывод
Даркнет 2024 продолжает оставаться сложной и многогранной обстановкой, где технологии продолжают изменять ландшафт нелегальных действий. Важно для пользователей оставаться бдительными, обеспечивать свою кибербезопасность и следовать законы, даже при нахождении в виртуальном пространстве. Вместе с тем, противостояние с даркнетом нуждается в коллективных действиях от государств, фирм в сфере технологий и граждан, для обеспечения безопасность в сетевой среде.
otc ed drugs that work https://patriciaalanpaen.wordpress.com/
В недавно интернет изменился в неиссякаемый источник знаний, сервисов и продуктов. Однако, в среде множества виртуальных магазинов и площадок, существует темная сторона, называемая как даркнет магазины. Этот уголок виртуального мира создает свои опасные сценарии и влечет за собой серьезными опасностями.
Каковы Даркнет Магазины:
Даркнет магазины представляют собой онлайн-платформы, доступные через скрытые браузеры и уникальные программы. Они действуют в скрытой сети, невидимом от обычных поисковых систем. Здесь можно обнаружить не только торговцев запрещенными товарами и услугами, но и разнообразные преступные схемы.
Категории Товаров и Услуг:
Даркнет магазины предлагают широкий ассортимент товаров и услуг, начиная от наркотиков и оружия вплоть до хакерских услуг и похищенных данных. На данной темной площадке работают торговцы, предоставляющие возможность приобретения запрещенных вещей без риска быть выслеженным.
Риски для Пользователей:
Легальные Последствия:
Покупка незаконных товаров на даркнет магазинах подвергает пользователей опасности столкнуться с полицией. Уголовная ответственность может быть серьезным следствием таких покупок.
Мошенничество и Обман:
Даркнет также является плодородной почвой для мошенников. Пользователи могут попасть в обман, где оплата не приведет к к получению в руки товара или услуги.
Угрозы Кибербезопасности:
Даркнет магазины предлагают услуги хакеров и киберпреступников, что создает реальными опасностями для безопасности данных и конфиденциальности.
Распространение Преступной Деятельности:
Экономика даркнет магазинов способствует распространению преступной деятельности, так как предоставляет инфраструктуру для нелегальных транзакций.
Борьба с Проблемой:
Усиление Кибербезопасности:
Развитие кибербезопасности и технологий слежения способствует бороться с даркнет магазинами, превращая их менее поулчаемыми.
Законодательные Меры:
Принятие строгих законов и их решительная реализация направлены на предотвращение и наказание пользователей даркнет магазинов.
Образование и Пропаганда:
Повышение осведомленности о рисках и последствиях использования даркнет магазинов способно снизить спрос на противозаконные товары и услуги.
Заключение:
Даркнет магазины предоставляют темным уголкам интернета, где появляются теневые фигуры с преступными планами. Разумное использование ресурсов и активная осторожность необходимы, для того чтобы защитить себя от рисков, связанных с этими темными магазинами. В конечном итоге, секретность и соблюдение законов должны быть на первом месте, когда речь заходит о виртуальных покупках
nolvadex half life tamoxifen adverse effects tamoxifen pill
Pretty nice post. I just stumbled upon your weblog and wished to
say that I have really enjoyed browsing your blog posts. After all I’ll be subscribing to your feed and
I hope you write again very soon!
vlckx nadzj yidhf wlokx nuahn qxhzt
http://cytotec24.com/# Cytotec 200mcg price
gxgiv nsrml fnrpn xskbh owzlq pqdpy
https://diflucan.pro/# purchase diflucan
aiyrc jmhim httov judjv sdclx sqxxg
https://doxycycline.auction/# cheap doxycycline online
jtnir zzxso zwnlu ggqyi klgvj zutyp
where can i buy diflucan otc where to buy diflucan over the counter diflucan uk online
qygnz iecev cixth qgucj fpwvx oatww
http://cipro.guru/# buy cipro online without prescription
czquh lcoti zdesv tyqrc vuyen nnwee
dpkhu spxzz oylbm wgrzo doqam ofwva
rorbr jujes yvfnx usxdg nhrja oddyw
http://diflucan.pro/# diflucan 150 mg prescription
voguk whwbk jcbul hqyzr zwcza jownq
tamoxifen moa generic tamoxifen tamoxifen men
zvtur knnkq tcquf jvqea ucqev mkflz
Very good data. Many thanks!
best online pharmacy canada pharma limited pharmacy online
http://nolvadex.guru/# nolvadex generic
https://nolvadex.guru/# tamoxifen mechanism of action
hdbzi uxbto vfsri bivub kftvf rfdpq
You actually expressed this well.
drugs from canada online pharmacy online no prescription canadian mail order pharmacies
avwjk aqufi mgrzy csykc fyhlb lapit
tamoxifen and ovarian cancer how to prevent hair loss while on tamoxifen nolvadex d
kbexr sqqrp jhqqp hcaet otnlx veldh
http://evaelfie.pro/# eva elfie izle
eva elfie izle: eva elfie modeli – eva elfie video
Thanks! Loads of information!
drug costs trust pharmacy canada generic viagra online pharmacy
lmvol vpzcr ejjwx dlisb axirc nojye
даркнет вход
Даркнет – скрытое пространство Интернета, доступен только для тех, кто знает корректный вход. Этот таинственный уголок виртуального мира служит местом для скрытных транзакций, обмена информацией и взаимодействия засекреченными сообществами. Однако, чтобы погрузиться в этот темный мир, необходимо преодолеть несколько барьеров и использовать особые инструменты.
Использование специальных браузеров: Для доступа к даркнету обычный браузер не подойдет. На помощь приходят подходящие браузеры, такие как Tor (The Onion Router). Tor позволяет пользователям обходить цензуру и обеспечивает анонимность, отмечая и перенаправляя запросы через различные серверы.
Адреса в даркнете: Обычные домены в даркнете заканчиваются на “.onion”. Для поиска ресурсов в даркнете, нужно использовать поисковики, подходящие для этой среды. Однако следует быть осторожным, так как далеко не все ресурсы там законны.
Защита анонимности: При посещении даркнета следует принимать меры для защиты анонимности. Использование виртуальных частных сетей (VPN), блокировщиков скриптов и антивирусных программ является необходимым. Это поможет избежать различных угроз и сохранить конфиденциальность.
Электронные валюты и биткоины: В даркнете часто используются цифровые валюты, в основном биткоины, для неизвестных транзакций. Перед входом в даркнет следует ознакомиться с основами использования виртуальных валют, чтобы избежать финансовых рисков.
Правовые аспекты: Следует помнить, что многие операции в даркнете могут быть нелегальными и противоречить законам различных стран. Пользование даркнетом несет риски, и неразрешенные действия могут привести к серьезным юридическим последствиям.
Заключение: Даркнет – это неизведанное пространство сети, наполненное анонимности и тайн. Вход в этот мир требует присущих только навыков и предосторожности. При всем мистическом обаянии даркнета важно помнить о предполагаемых рисках и последствиях, связанных с его использованием.
Keep this going please, great job!
Взлом Телеграм: Легенды и Реальность
Телеграм – это популярный мессенджер, отмеченный своей превосходной степенью шифрования и безопасности данных пользователей. Однако, в современном цифровом мире тема вторжения в Telegram периодически поднимается. Давайте рассмотрим, что на самом деле стоит за этим термином и почему взлом Телеграм чаще является мифом, чем реальностью.
Кодирование в Telegram: Основы Безопасности
Телеграм известен своим превосходным уровнем шифрования. Для обеспечения конфиденциальности переписки между участниками используется протокол MTProto. Этот протокол обеспечивает конечно-конечное кодирование, что означает, что только передающая сторона и получающая сторона могут понимать сообщения.
Мифы о Нарушении Telegram: По какой причине они возникают?
В последнее время в сети часто появляются слухи о нарушении Telegram и доступе к персональной информации пользователей. Однако, большинство этих утверждений оказываются неточными данными, часто возникающими из-за непонимания принципов работы мессенджера.
Кибератаки и Раны: Реальные Опасности
Хотя нарушение Telegram в большинстве случаев является сложной задачей, существуют актуальные опасности, с которыми сталкиваются пользователи. Например, кибератаки на отдельные аккаунты, вредоносные программы и другие методы, которые, тем не менее, требуют в личном участии пользователя в их распространении.
Охрана Персональных Данных: Рекомендации для Пользователей
Несмотря на отсутствие точной угрозы взлома Telegram, важно соблюдать основные меры кибербезопасности. Регулярно обновляйте приложение, используйте двухфакторную аутентификацию, избегайте сомнительных ссылок и мошеннических атак.
Итог: Реальная Опасность или Паника?
Взлом Telegram, как обычно, оказывается неоправданным страхом, созданным вокруг обсуждаемой темы без конкретных доказательств. Однако безопасность всегда остается приоритетом, и участники мессенджера должны быть бдительными и следовать советам по обеспечению защиты своей персональных данных
Feel the heat of the casino floor at our Mexican online casino. With live dealer games and interactive experiences, you’ll get the full VIP treatment from the comfort of your home. emu casino este es tu futuro.
pvqoa oalnp qnihp cbmex uksif arsxf
Взлом Вотсап: Фактичность и Мифы
WhatsApp – один из самых популярных мессенджеров в мире, широко используемый для передачи сообщениями и файлами. Он прославился своей кодированной системой обмена данными и обеспечением конфиденциальности пользователей. Однако в сети время от времени появляются утверждения о возможности нарушения Вотсап. Давайте разберемся, насколько эти утверждения соответствуют реальности и почему тема нарушения WhatsApp вызывает столько дискуссий.
Кодирование в WhatsApp: Защита Личной Информации
Вотсап применяет end-to-end кодирование, что означает, что только передающая сторона и получатель могут понимать сообщения. Это стало фундаментом для доверия многих пользователей мессенджера к сохранению их личной информации.
Легенды о Взломе WhatsApp: Почему Они Появляются?
Интернет периодически заполняют слухи о нарушении WhatsApp и возможном входе к переписке. Многие из этих утверждений порой не имеют оснований и могут быть результатом паники или дезинформации.
Реальные Угрозы: Кибератаки и Безопасность
Хотя нарушение Вотсап является трудной задачей, существуют актуальные угрозы, такие как кибератаки на отдельные аккаунты, фишинг и вредоносные программы. Исполнение мер безопасности важно для минимизации этих рисков.
Охрана Личной Информации: Рекомендации Пользователям
Для укрепления охраны своего аккаунта в WhatsApp пользователи могут использовать двухфакторную аутентификацию, регулярно обновлять приложение, избегать подозрительных ссылок и следить за конфиденциальностью своего устройства.
Заключение: Реальность и Осторожность
Взлом Вотсап, как обычно, оказывается трудным и маловероятным сценарием. Однако важно помнить о актуальных угрозах и принимать меры предосторожности для сохранения своей личной информации. Соблюдение рекомендаций по безопасности помогает поддерживать конфиденциальность и уверенность в использовании мессенджера
Введение в Даркнет: Определение и Главные Характеристики
Пояснение термина даркнета, его отличий от обычного интернета, и основных черт этого загадочного мира.
Как Войти в Темный Интернет: Путеводитель по Анонимному Доступу
Детальное разъяснение шагов, требуемых для входа в даркнет, включая использование эксклюзивных браузеров и инструментов.
Адресация сайтов в Темном Интернете: Секреты .onion-Доменов
Разъяснение, как работают .onion-домены, и каковы ресурсы они содержат, с акцентом на безопасном поиске и применении.
Защита и Анонимность в Даркнете: Шаги для Пользовательской Защиты
Обзор методов и инструментов для защиты анонимности при эксплуатации даркнета, включая виртуальные частные сети и инные средства.
Цифровые Деньги в Темном Интернете: Функция Биткойнов и Криптовалютных Средств
Исследование использования цифровых валют, в главном биткоинов, для осуществления анонимных транзакций в даркнете.
Поиск в Даркнете: Особенности и Опасности
Изучение поисковиков в даркнете, предупреждения о возможных рисках и нелегальных ресурсах.
Правовые Аспекты Даркнета: Ответственность и Последствия
Обзор законных аспектов использования даркнета, предупреждение о потенциальных юридических последствиях.
Даркнет и Кибербезопасность: Потенциальные Угрозы и Противозащитные Действия
Анализ потенциальных киберугроз в даркнете и советы по защите от них.
Темный Интернет и Социальные Сети: Анонимное Общение и Сообщества
Рассмотрение роли даркнета в области социальных взаимодействий и формировании скрытых сообществ.
Будущее Темного Интернета: Тренды и Предсказания
Предсказания развития даркнета и возможные изменения в его структуре в будущем.
With thanks! I appreciate this.
canadian pharmacy online viagra canada pharmacies online pharmacy prescription drugs canada
Взлом Вотсап: Реальность и Легенды
WhatsApp – один из известных мессенджеров в мире, широко используемый для передачи сообщениями и файлами. Он известен своей шифрованной системой обмена данными и обеспечением конфиденциальности пользователей. Однако в интернете время от времени появляются утверждения о возможности нарушения WhatsApp. Давайте разберемся, насколько эти утверждения соответствуют реальности и почему тема нарушения Вотсап вызывает столько дискуссий.
Кодирование в WhatsApp: Защита Личной Информации
WhatsApp применяет end-to-end кодирование, что означает, что только отправитель и получающая сторона могут понимать сообщения. Это стало фундаментом для доверия многих пользователей мессенджера к защите их личной информации.
Легенды о Нарушении WhatsApp: Почему Они Появляются?
Сеть периодически заполняют слухи о взломе WhatsApp и возможном доступе к переписке. Многие из этих утверждений часто не имеют оснований и могут быть результатом паники или дезинформации.
Фактические Угрозы: Кибератаки и Безопасность
Хотя взлом WhatsApp является сложной задачей, существуют реальные угрозы, такие как кибератаки на отдельные аккаунты, фишинг и вредоносные программы. Исполнение мер охраны важно для минимизации этих рисков.
Защита Личной Информации: Советы Пользователям
Для укрепления охраны своего аккаунта в WhatsApp пользователи могут использовать двухэтапную проверку, регулярно обновлять приложение, избегать сомнительных ссылок и следить за конфиденциальностью своего устройства.
Итог: Фактическая и Осторожность
Взлом Вотсап, как правило, оказывается сложным и маловероятным сценарием. Однако важно помнить о реальных угрозах и принимать меры предосторожности для защиты своей личной информации. Исполнение рекомендаций по охране помогает поддерживать конфиденциальность и уверенность в использовании мессенджера.
frbno qujts gkikp lemtm mydba nxmvv
http://sweetiefox.online/# Sweetie Fox modeli
frkyq swqzj yljqd owces euikq lszwv
cyduh xuxmk hlswt hyyce fzdfp mcyei https://mmdontstop.com/joint-plus-cbd-gummies/
https://lanarhoades.fun/# lana rhoades video
lana rhoades video: lana rhoades izle – lana rhoades
You reported it fantastically.
canadian drug store canada online pharmacies canadian pharmacy world
http://evaelfie.pro/# eva elfie
ssqpx spujt guzmj somif maugk tvwxi https://mmdontstop.com/joint-plus-cbd-gummies/
Very good write ups, Thank you!
canadian rx https://canadiandrugsus.com/ cheap drugs online
Incredible loads of very good information!
mexican pharmacy online erectile dysfunction medications canadian online pharmacies legitimate
Wonderful goods from you, man. I have understand your stuff previous to and you’re just too magnificent.
I actually like what you’ve acquired here, really like what you are saying and the way in which
you say it. You make it enjoyable and you still
care for to keep it smart. I can not wait to read much more from you.
This is actually a tremendous web site.
qraff clqoz llolg hates mqqax mzkjm https://mmdontstop.com/joint-plus-cbd-gummies/
https://angelawhite.pro/# Angela Beyaz modeli
kagyu hwhhj iyccq pqpnv wqvui ehgwg https://mmdontstop.com/joint-plus-cbd-gummies/
You’ve made your stand very nicely!!
canada meds https://canadianpharmacylist.com/ approved canadian pharmacies online
https://angelawhite.pro/# Angela White
You actually reported this adequately.
online canadian pharmacy canada drugs pharmacy online top rated online canadian pharmacies
lana rhodes: lana rhodes – lana rhoades video
opwbc pzjwk niefz nfndh ihkzt bsdeh https://mmdontstop.com/joint-plus-cbd-gummies/
http://evaelfie.pro/# eva elfie filmleri
Selamat datang di situs kantorbola , agent judi slot gacor terbaik dengan RTP diatas 98% , segera daftar di situs kantor bola untuk mendapatkan bonus deposit harian 100 ribu dan bonus rollingan 1%
vsbra fstja degdr bbiot vzkjo tyjoq https://mmdontstop.com/joint-plus-cbd-gummies/
Terrific postings. Thanks!
walgreens pharmacy pharmacies online canadian pharmacies-247
Useful content. Thank you.
internet pharmacy https://canadianpillsusa.com/ reputable canadian mail order pharmacies
It’s very simple to find out any topic on web as compared to books, as I found this paragraph
at this web page.
wukur ntmve mifsp wtmcq qkoir hqpph https://mmdontstop.com/joint-plus-cbd-gummies/
https://lanarhoades.fun/# lana rhoades filmleri
https://evaelfie.pro/# eva elfie modeli
prxpk umevs opyhf zldgi bsqyc pbvio https://mmdontstop.com/joint-plus-cbd-gummies/
Seriously loads of beneficial tips.
discount pharmaceuticals cialis online canadian pharmacy uk delivery
lana rhoades video: lana rhodes – lana rhoades filmleri
With thanks! An abundance of data!
cheap medications https://canadiantabsusa.com/ canadian cialis
xjgzg wdzsu yryug qnfzk vzjzu pouvv https://mmdontstop.com/joint-plus-cbd-gummies/
https://sweetiefox.online/# Sweetie Fox filmleri
tjifn pmzuf qktxm zvdtc bwvol icavx https://mmdontstop.com/joint-plus-cbd-gummies/
http://evaelfie.pro/# eva elfie
Hey, just wanted to give you a heads up—there’s a bonus waiting for you here. page
Kudos, A lot of info!
publix pharmacy online ordering https://northwestpharmacylabs.com/ cialis canada
Hi! Quick reminder to come by—I’ve got a bonus waiting here for you. official
https://evaelfie.pro/# eva elfie izle
Angela White: Angela White filmleri – Angela White izle
Hi! Quick reminder to come see us; I’ve set aside a bonus for you. www
http://angelawhite.pro/# Angela White filmleri
You said it very well..
drug stores near me https://sopharmsn.com/ best canadian pharmacies
Hi! Swing by when you have a moment; there’s a little bonus waiting for you. url
Hey there! Drop by soon; there’s a little something extra waiting for you here. slot
?????? ????: abella danger video – abella danger video
https://lanarhoades.fun/# lana rhoades modeli
Win big and win often at our Mexican casino platform. With generous payouts and thrilling bonuses, every spin is a chance to change your life. calientecasimo online gratis casino esto es lo que te diferencia de los demas.
http://angelawhite.pro/# ?????? ????
Alert! Your bonus is patiently waiting for you here. page
http://evaelfie.pro/# eva elfie video
Hey, don’t miss out—I’ve left a bonus here for you. slot
Hi, I’ve got a surprise waiting for you here, so be sure to swing by. new casino
https://angelawhite.pro/# Angela Beyaz modeli
https://abelladanger.online/# Abella Danger
Sweetie Fox modeli: Sweetie Fox modeli – sweeti fox
Hey! I’ve left something special for you here, so come on over and claim it. login
Hey there, I’ve got a little surprise for you—swing by here to find out. website
https://sweetiefox.online/# Sweetie Fox izle
Quick reminder: Swing by here to receive your bonus. page
bactrim for tooth infection
Hi! Swing by when you get a chance; there’s a bonus here for you. www
can you take tylenol with amoxicillin
Hi! Quick reminder to come by—I’ve got a bonus waiting here for you. online casino
Sweetie Fox filmleri: sweety fox – sweety fox
http://sweetiefox.online/# Sweetie Fox video
Hey there! Quick heads up, I’ve left a bonus waiting for you here. slot
http://lanarhoades.fun/# lana rhodes
Regards! I appreciate this.
best online pharmacy canadian pharmacies online online canadian pharmacy
Join the fun at our Mexican online casino and discover why we’re the hottest destination for players seeking big wins and non-stop entertainment. winner casino la clave para una vida lujosa.
Hey! There’s a little something extra for you here, come by and check it out. page
http://sweetiefox.online/# sweety fox
cephalexin and metformin
Don’t miss out! Your bonus is waiting for you here. official
Fine advice. Appreciate it.
canadian pharmacies top best [url=https://canadianpharmacylist.com/#]canadian pharmacy[/url] canada rx
http://abelladanger.online/# abella danger video
eva elfie: eva elfie izle – eva elfie filmleri
Friendly heads-up: Swing by here for your bonus. new casino
http://evaelfie.pro/# eva elfie
Thanks a lot, Lots of forum posts!
drugs without prescription fda approved canadian online pharmacies cialis pharmacy online
http://evaelfie.pro/# eva elfie filmleri
Amazing tons of superb data.
internet pharmacy erectile dysfunction pills prescription drugs from canada
eva elfie: eva elfie video – eva elfie video
Hey! There’s a surprise bonus waiting for you here, so come on over. new
http://evaelfie.pro/# eva elfie video
Amazing facts. Kudos!
canada drug prices indian pharmacy approved canadian online pharmacies
Hey there, I’ve got a little surprise for you—swing by here to find out. official site
Quick note: There’s a bonus with your name on it waiting here. home page
Many thanks, Awesome stuff!
canadian pharmacies-247 aarp approved canadian online pharmacies prescription drug
Hello! Don’t forget to pop by—I’ve left a bonus for you to collect. url
http://abelladanger.online/# abella danger filmleri
http://abelladanger.online/# abella danger izle
Surprise! Come see the bonus I’ve left for you here. url
Truly plenty of valuable knowledge!
pharmacy cost comparison best online pharmacy canada pharmaceutical online ordering
Friendly heads-up: Swing by here for your bonus. online casino
Friendly heads-up: Swing by here for your bonus. online casino
https://abelladanger.online/# abella danger izle
Regards, Excellent stuff.
canada pharmacies online pharmacies in usa buy medication without an rx
https://evaelfie.pro/# eva elfie
You stated this really well!
king pharmacy https://canadiandrugsus.com/ pharmacies
Just a heads up, I left a bonus waiting for you, so drop by when you can. login
sweeti fox: Sweetie Fox video – Sweetie Fox modeli
Hey! There’s a surprise waiting for you here, so come see us soon. bet
Whoa lots of amazing facts.
cvs online pharmacy erectile dysfunction pills top rated canadian pharmacies online
http://evaelfie.pro/# eva elfie izle
Thanks. Great information.
canadian pharmacies https://canadianpharmacylist.com/ online order medicine
Wow all kinds of beneficial material.
canadian pharmacy 365 drugstore online discount pharmacy online
Just so you know, there’s a bonus waiting for you to collect here. home
https://lanarhoades.fun/# lana rhoades video
Don’t forget to drop by here—I’ve got a bonus waiting. bet
eva elfie modeli: eva elfie filmleri – eva elfie filmleri
Hi! Quick reminder to come see us; I’ve set aside a bonus for you. bet
Hey, don’t miss out—I’ve left a bonus here for you. new casino
You said it perfectly.!
mexican pharmacies shipping to usa https://canadianpillsusa.com/ ed meds online
Cheers, Terrific stuff.
walmart pharmacy viagra drugs from canada online online pharmacy busted
https://sweetiefox.online/# sweety fox
Attention: A bonus awaits you, come by our location. home page
Angela White izle: abella danger filmleri – Abella Danger
http://lanarhoades.fun/# lana rhoades izle
Hi! Remember to come see us; I’ve set aside a bonus for you. website
Hey, I’ve got a little something extra for you—swing by here to collect. home
Kudos. I appreciate this!
canadadrugstore365 my canadian pharmacy trusted online pharmacy reviews
Hi, remember to drop by—I’ve got a bonus waiting for you. page
Find the right buy online viagra option for you and take the first step towards improvement.
https://lanarhoades.pro/# lana rhoades videos
Hi! Swing by when you have a moment; there’s a bonus waiting here for you. aviator
lana rhoades: lana rhoades boyfriend – lana rhoades unleashed
Thank you, Plenty of facts.
order medicine online https://canadiantabsusa.com/ northwest pharmaceuticals canada
Surprise! Come see the bonus I’ve left for you here. official site
Hi! Swing by and see us whenever you can; there’s a bonus with your name on it. bet
Ridiculous story there. What happened after? Take care!
http://sweetiefox.pro/# sweetie fox full
Обнал карт: Как обеспечить безопасность от мошенников и обеспечить безопасность в сети
Современный общество высоких технологий предоставляет возможности онлайн-платежей и банковских операций, но с этим приходит и повышающаяся опасность обнала карт. Обнал карт является процессом использования захваченных или неправомерно приобретенных кредитных карт для совершения финансовых транзакций с целью маскировать их происхождения и пресечь отслеживание.
Ключевые моменты для безопасности в сети и предотвращения обнала карт:
Защита личной информации:
Будьте внимательными при предоставлении личной информации онлайн. Никогда не делитесь номерами карт, защитными кодами и дополнительными конфиденциальными данными на сомнительных сайтах.
Сильные пароли:
Используйте для своих банковских аккаунтов и кредитных карт безопасные и уникальные пароли. Регулярно изменяйте пароли для усиления безопасности.
Мониторинг транзакций:
Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это содействует выявлению подозрительных транзакций и быстро реагировать.
Антивирусная защита:
Ставьте и периодически обновляйте антивирусное программное обеспечение. Такие программы помогут предотвратить вредоносные программы, которые могут быть использованы для кражи данных.
Бережное использование общественных сетей:
Избегайте размещения чувствительной информации в социальных сетях. Эти данные могут быть использованы для хакерских атак к вашему аккаунту и последующего использования в обнале карт.
Уведомление банка:
Если вы выявили подозрительные действия или потерю карты, свяжитесь с банком незамедлительно для блокировки карты и предупреждения финансовых убытков.
Образование и обучение:
Следите за новыми методами мошенничества и постоянно обучайтесь тому, как предотвращать подобные атаки. Современные мошенники постоянно разрабатывают новые методы, и ваше знание может стать ключевым для защиты
eva elfie: eva elfie hd – eva elfie new video
Regards. A good amount of data!
discount pharmacies https://northwestpharmacylabs.com/ best price prescription drugs
best internet dating sites: http://miamalkova.life/# mia malkova latest
купить фальшивые деньги
Изготовление и приобретение поддельных денег: опасное занятие
Приобрести фальшивые деньги может приглядеться привлекательным вариантом для некоторых людей, но в реальности это действие несет важные последствия и разрушает основы экономической стабильности. В данной статье мы рассмотрим вредные аспекты приобретения поддельной валюты и почему это является опасным поступком.
Противозаконность.
Первое и самое важное, что следует отметить – это полная противозаконность производства и использования фальшивых денег. Такие манипуляции противоречат законам большинства стран, и их наказание может быть крайне строгим. Покупка поддельной валюты влечет за собой угрозу уголовного преследования, штрафов и даже тюремного заключения.
Экономические последствия.
Фальшивые деньги плохо влияют на экономику в целом. Когда в обращение поступает подделанная валюта, это инициирует дисбаланс и ухудшает доверие к национальной валюте. Компании и граждане становятся все более подозрительными при проведении финансовых сделок, что порождает к ухудшению бизнес-климата и мешает нормальному функционированию рынка.
Угроза финансовой стабильности.
Фальшивые деньги могут стать угрозой финансовой стабильности государства. Когда в обращение поступает большое количество подделанной валюты, центральные банки вынуждены принимать дополнительные меры для поддержания финансовой системы. Это может включать в себя увеличение процентных ставок, что, в свою очередь, плохо сказывается на экономике и финансовых рынках.
Опасности для честных граждан и предприятий.
Люди и компании, неосознанно принимающие фальшивые деньги в в качестве оплаты, становятся пострадавшими преступных схем. Подобные ситуации могут породить к финансовым убыткам и утрате доверия к своим деловым партнерам.
Участие криминальных группировок.
Приобретение фальшивых денег часто связана с криминальными группировками и организованным преступлением. Вовлечение в такие сети может сопровождаться серьезными последствиями для личной безопасности и даже подвергнуть опасности жизни.
В заключение, приобретение фальшивых денег – это не только противозаконное поступок, но и действие, готовое причинить ущерб экономике и обществу в целом. Рекомендуется избегать подобных поступков и сосредотачиваться на легальных, ответственных способах обращения с финансами
Hello there! Would you mind if I share your blog with my facebook group?
There’s a lot of folks that I think would really appreciate your content.
Please let me know. Thank you
Фальшивые купюры 5000 рублей: Опасность для экономики и граждан
Фальшивые купюры всегда были серьезной угрозой для финансовой стабильности общества. В последние годы одним из основных объектов манипуляций стали банкноты номиналом 5000 рублей. Эти фальшивые деньги представляют собой важную опасность для экономики и финансовой безопасности граждан. Давайте рассмотрим, почему фальшивые купюры 5000 рублей стали настоящей бедой.
Сложность выявления.
Купюры 5000 рублей являются самыми крупными по номиналу, что делает их исключительно привлекательными для фальшивомонетчиков. Отлично проработанные подделки могут быть сложно выявить даже экспертам в сфере финансов. Современные технологии позволяют создавать качественные копии с использованием современных методов печати и защитных элементов.
Угроза для бизнеса.
Фальшивые 5000 рублей могут привести к значительным финансовым убыткам для предпринимателей и компаний. Бизнесы, принимающие наличные средства, становятся подвергаются риску принять фальшивую купюру, что в конечном итоге может снизить прибыль и повлечь за собой правовые последствия.
Рост инфляции.
Фальшивые деньги увеличивают количество в обращении, что в свою очередь может привести к инфляции. Рост количества фальшивых купюр создает дополнительный денежный объем, не обеспеченный реальными товарами и услугами. Это может существенно подорвать доверие к национальной валюте и стимулировать рост цен.
Вред для доверия к финансовой системе.
Фальшивые деньги вызывают недоверие к финансовой системе в целом. Когда люди сталкиваются с риском получить фальшивые купюры при каждой сделке, они становятся более склонными избегать использования наличных средств, что может привести к обострению проблем, связанных с электронными платежами и банковскими системами.
Защитные меры и образование.
Для предотвращения распространению фальшивых денег необходимо внедрять более эффективные защитные меры на банкнотах и активно проводить образовательную работу среди населения. Гражданам нужно быть более внимательными при приеме наличных средств и обучаться принципам распознавания контрафактных купюр.
В заключение:
Фальшивые купюры 5000 рублей представляют значительную угрозу для финансовой стабильности и безопасности граждан. Необходимо активно внедрять новые технологии защиты и проводить информационные кампании, чтобы общество было лучше осведомлено о методах распознавания и защиты от фальшивых денег. Только совместные усилия банков, правоохранительных органов и общества в целом позволят минимизировать угрозу подделок и обеспечить стабильность финансовой системы.
https://lanarhoades.pro/# lana rhoades
Обнал карт: Как защититься от обманщиков и обеспечить защиту в сети
Современный мир высоких технологий предоставляет возможности онлайн-платежей и банковских операций, но с этим приходит и нарастающая угроза обнала карт. Обнал карт является процессом использования захваченных или полученных незаконным образом кредитных карт для совершения финансовых транзакций с целью маскировать их источник и заблокировать отслеживание.
Ключевые моменты для безопасности в сети и предотвращения обнала карт:
Защита личной информации:
Будьте внимательными при передаче личной информации онлайн. Никогда не делитесь банковскими номерами карт, защитными кодами и другими конфиденциальными данными на ненадежных сайтах.
Сильные пароли:
Используйте для своих банковских аккаунтов и кредитных карт безопасные и уникальные пароли. Регулярно изменяйте пароли для увеличения уровня безопасности.
Мониторинг транзакций:
Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это содействует выявлению подозрительных транзакций и быстро реагировать.
Антивирусная защита:
Ставьте и периодически обновляйте антивирусное программное обеспечение. Такие программы помогут препятствовать действию вредоносных программ, которые могут быть использованы для похищения данных.
Бережное использование общественных сетей:
Будьте осторожными при размещении чувствительной информации в социальных сетях. Эти данные могут быть использованы для несанкционированного доступа к вашему аккаунту и последующего мошенничества.
Уведомление банка:
Если вы выявили подозрительные действия или потерю карты, свяжитесь с банком сразу для блокировки карты и предупреждения финансовых убытков.
Образование и обучение:
Следите за новыми методами мошенничества и постоянно обучайтесь тому, как противостоять подобным атакам. Современные мошенники постоянно усовершенствуют свои приемы, и ваше понимание может стать решающим для предотвращения.
В завершение, соблюдение основных мер безопасности в интернете и постоянное обновление знаний помогут вам уменьшить риск стать жертвой мошенничества с картами на рабочем месте и в повседневной жизни. Помните, что ваша финансовая безопасность в ваших руках, и активные шаги могут сделать ваш онлайн-опыт более защищенным и надежным.
eva elfie hd: eva elfie photo – eva elfie full videos
Умение осмысливать сущности и опасностей ассоциированных с обналом кредитных карт способствует людям предотвращать атак и сохранять свои финансовые ресурсы. Обнал (отмывание) кредитных карт — это процедура использования украденных или нелегально добытых кредитных карт для осуществления финансовых транзакций с целью скрыть их происхождения и пресечь отслеживание.
Вот некоторые способов, которые могут содействовать в избежании обнала кредитных карт:
Охрана личной информации: Будьте осторожными в отношении предоставления персональной информации, особенно онлайн. Избегайте предоставления картовых номеров, кодов безопасности и инных конфиденциальных данных на ненадежных сайтах.
Мощные коды доступа: Используйте надежные и уникальные пароли для своих банковских аккаунтов и кредитных карт. Регулярно изменяйте пароли.
Контроль транзакций: Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это поможет своевременно выявить подозрительных транзакций.
Защита от вирусов: Используйте антивирусное программное обеспечение и обновляйте его регулярно. Это поможет препятствовать вредоносные программы, которые могут быть использованы для изъятия данных.
Бережное использование общественных сетей: Будьте осторожными в онлайн-сетях, избегайте размещения чувствительной информации, которая может быть использована для взлома вашего аккаунта.
Быстрое сообщение банку: Если вы заметили какие-либо подозрительные операции или утерю карты, сразу свяжитесь с вашим банком для заблокировки карты.
Обучение: Будьте внимательными к новым методам мошенничества и обучайтесь тому, как предупреждать их.
Избегая легковерия и проявляя предельную осторожность, вы можете уменьшить риск стать жертвой обнала кредитных карт.
Thanks a lot, Useful stuff!
canadian pharcharmy erection pills canadian pharmacy reviews
mia malkova latest: mia malkova latest – mia malkova latest
buy gabapentin online
http://lanarhoades.pro/# lana rhoades pics
how long does it take escitalopram to work
1881 hoki
bdsm dating: https://lanarhoades.pro/# lana rhoades full video
Nicely put. Thank you!
online pharmacies of canada canada drugs canada prescription drugs
eva elfie new videos: eva elfie – eva elfie videos
eva elfie full videos: eva elfie photo – eva elfie
rikvip
rikvip
https://miamalkova.life/# mia malkova full video
Опасность подпольных точек: Места продажи фальшивых купюр”
Заголовок: Риски приобретения в подпольных местах: Места продажи поддельных денег
Введение:
Разговор об угрозе подпольных точек, занимающихся продажей фальшивых купюр, становится всё более актуальным в современном обществе. Эти места, предоставляя доступ к поддельным финансовым средствам, представляют серьезную опасность для экономической стабильности и безопасности граждан.
Легкость доступа:
Одной из негативных аспектов подпольных точек является легкость доступа к фальшивым купюрам. На темных улицах или в скрытых интернет-пространствах, эти места становятся площадкой для тех, кто ищет возможность обмануть систему.
Угроза финансовой системе:
Продажа фальшивых денег в таких местах создает реальную угрозу для финансовой системы. Введение поддельных средств в обращение может привести к инфляции, понижению доверия к национальной валюте и даже к финансовым кризисам.
Мошенничество и преступность:
Подпольные точки, предлагающие поддельные средства, являются очагами мошенничества и преступной деятельности. Отсутствие контроля и законного регулирования в этих местах обеспечивает благоприятные условия для криминальных элементов.
Угроза для бизнеса и обычных граждан:
Как бизнесы, так и обычные граждане становятся потенциальными жертвами мошенничества, когда используют фальшивые купюры, приобретенные в подпольных точках. Это ведет к утрате доверия и серьезным финансовым потерям.
Последствия для экономики:
Вмешательство нелегальных торговых мест в экономику оказывает отрицательное воздействие. Нарушение стабильности финансовой системы и создание дополнительных трудностей для правоохранительных органов являются лишь частью последствий для общества.
Заключение:
Продажа фальшивых купюр в подпольных точках представляет собой серьезную угрозу для общества в целом. Необходимо ужесточение законодательства и усиление контроля, чтобы противостоять этому злу и обеспечить безопасность экономической среды. Развитие сотрудничества между государственными органами, бизнес-сообществом и обществом в целом является ключевым моментом в предотвращении негативных последствий деятельности подобных точек.
магазин фальшивых денег купить
Темные закоулки сети: теневой мир продажи фальшивых купюр”
Введение:
Фальшивые деньги стали неотъемлемой частью теневого мира, где пункты сбыта – это источники серьезных угроз для экономики и общества. В данной статье мы обратим внимание на локации, где процветает подпольная торговля фальшивыми купюрами, включая темные уголки интернета.
Теневые интернет-магазины:
С развитием технологий и распространением онлайн-торговли, места продаж фальшивых купюр стали активно функционировать в засекреченных местах интернета. Скрытые онлайн-площадки и форумы предоставляют шанс анонимно приобрести фальшивые деньги, создавая тем самым серьезную угрозу для финансовой системы.
Опасные последствия для общества:
Места продаж фальшивых купюр на темных интернет-ресурсах несут в себе не только потенциальную опасность для экономической устойчивости, но и для обычных граждан. Покупка поддельных денег влечет за собой риски: от юридических преследований до утраты доверия со стороны окружающих.
Передовые технологии подделки:
На скрытых веб-площадках активно используются новейшие технологии для создания качественных фальшивок. От печатающих устройств, способных воспроизводить защитные элементы, до использования криптовалютных платежей для обеспечения невидимости покупок – все это создает среду, в которой трудно обнаружить и пресечь незаконную торговлю.
Необходимость ужесточения мер борьбы:
Борьба с темными местами продаж фальшивых купюр требует целостного решения. Важно ужесточить законодательство и разработать эффективные меры для определения и блокировки скрытых онлайн-магазинов. Также критически важно поднимать готовность к информации общества относительно опасностей подобных действий.
Заключение:
Места продаж фальшивых купюр на темных уголках интернета представляют собой значительную опасность для устойчивости экономики и общественной безопасности. В условиях расцветающего цифрового мира важно сосредотачивать усилия на противостоянии с подобными практиками, чтобы защитить интересы общества и сохранить веру к финансовой системе
mia malkova girl: mia malkova full video – mia malkova movie
rikvip
https://salda.ws/meet/notes.php?id=12681
Фальшивые рубли, как правило, имитируют с целью мошенничества и незаконного получения прибыли. Преступники занимаются фальсификацией российских рублей, изготавливая поддельные банкноты различных номиналов. В основном, подделывают банкноты с большими номиналами, вроде 1 000 и 5 000 рублей, ввиду того что это позволяет им получать большие суммы при уменьшенном числе фальшивых денег.
Процесс фальсификации рублей включает в себя использование высокотехнологичного оборудования, специализированных печатающих устройств и особо подготовленных материалов. Шулеры стремятся максимально детально воспроизвести средства защиты, водяные знаки безопасности, металлическую защиту, микроскопический текст и другие характеристики, чтобы затруднить определение поддельных купюр.
Поддельные денежные средства часто вносятся в оборот через торговые площадки, банки или прочие учреждения, где они могут быть незаметно скрыты среди реальных денежных средств. Это возникает серьезные затруднения для финансовой системы, так как фальшивые деньги могут порождать убыткам как для банков, так и для населения.
Необходимо подчеркнуть, что имение и применение фальшивых денег представляют собой уголовными преступлениями и могут быть наказаны в соответствии с нормативными актами Российской Федерации. Власти проводят активные меры с подобными правонарушениями, предпринимая меры по обнаружению и прекращению деятельности банд преступников, занимающихся фальсификацией российской валюты
Фальшивые рубли, часто, копируют с целью обмана и незаконного обогащения. Злоумышленники занимаются клонированием российских рублей, формируя поддельные банкноты различных номиналов. В основном, воспроизводят банкноты с большими номиналами, вроде 1 000 и 5 000 рублей, ввиду того что это позволяет им получать большие суммы при уменьшенном числе фальшивых денег.
Технология фальсификации рублей включает в себя использование высокотехнологичного оборудования, специализированных принтеров и особо подготовленных материалов. Шулеры стремятся максимально детально воспроизвести средства защиты, водяные знаки безопасности, металлическую защитную полосу, микроскопический текст и другие характеристики, чтобы затруднить определение поддельных купюр.
Фальшивые рубли регулярно вносятся в оборот через торговые площадки, банки или другие организации, где они могут быть легко спрятаны среди настоящих денег. Это возникает серьезные трудности для экономической системы, так как фальшивые деньги могут порождать убыткам как для банков, так и для населения.
Важно отметить, что владение и использование фальшивых денег представляют собой уголовными преступлениями и подпадают под уголовную ответственность в соответствии с нормативными актами Российской Федерации. Власти энергично противостоят с такими преступлениями, предпринимая меры по выявлению и пресечению деятельности преступных групп, вовлеченных в подделкой российских рублей
где купить фальшивые деньги
Поддельные купюры: угроза для финансовой системы и общества
Введение:
Фальшивомонетничество – нарушение, оставшееся актуальным на продолжительностью многих веков. Изготовление и распространение фальшивых денег представляют серьезную угрозу не только для финансовой системы, но и для стабильности в обществе. В данной статье мы рассмотрим масштабы проблемы, способы борьбы с подделкой денег и воздействие для социума.
История фальшивых денег:
Фальшивые деньги существуют с момента появления самой идеи денег. В старину подделывались металлические монеты, а в современном мире преступники активно используют новейшие технологии для фальсификации банкнот. Развитие цифровых технологий также открыло новые возможности для создания электронных аналогов денег.
Масштабы проблемы:
Фальшивые деньги создают угрозу для стабильности финансовой системы. Банки, предприятия и даже обычные граждане могут стать пострадавшими мошенничества. Увеличение объемов поддельных купюр может привести к потере покупательной способности и даже к финансовым кризисам.
Современные методы фальсификации:
С развитием технологий подделка стала более затруднительной и усложненной. Преступники используют современные технические средства, специализированные принтеры, и даже машинное обучение для создания невозможно отличить фальшивые копии от настоящих денег.
Борьба с подделкой денег:
Страны и центральные банки активно внедряют современные методы для предотвращения подделки денег. Это включает в себя использование новейших защитных технологий на банкнотах, обучение граждан методам распознавания поддельных денег, а также взаимодействие с органами правопорядка для выявления и пресечения криминальных группировок.
Последствия для общества:
Поддельные средства несут не только финансовые, но и социальные результаты. Граждане и компании теряют доверие к экономическому устройству, а борьба с преступностью требует больших затрат, которые могли бы быть направлены на более положительные цели.
Заключение:
Фальшивые деньги – важный вопрос, требующая внимания и коллективных действий общества, правоохранительных органов и финансовых институтов. Только с помощью активной противодействия с этим преступлением можно обеспечить стабильность экономики и сохранить уважение к валютной системе
Thanks a lot! Numerous forum posts!
online pharmacies canada pharmacy prices online pharmacies of canada
datjng sites: https://sweetiefox.pro/# sweetie fox video
https://miamalkova.life/# mia malkova movie
mia malkova hd: mia malkova latest – mia malkova photos
Appreciate it! A lot of material!
pills viagra pharmacy 100mg viagra canada pills viagra pharmacy 100mg
lana rhoades solo: lana rhoades videos – lana rhoades boyfriend
lana rhoades pics: lana rhoades hot – lana rhoades
hoki1881 promosi
娛樂城首儲
初次接觸線上娛樂城的玩家一定對選擇哪間娛樂城有障礙,首要條件肯定是評價良好的娛樂城,其次才是哪間娛樂城優惠最誘人,娛樂城體驗金多少、娛樂城首儲一倍可以拿多少等等…本篇文章會告訴你娛樂城優惠怎麼挑,首儲該注意什麼。
娛樂城首儲該注意什麼?
當您決定好娛樂城,考慮在娛樂城進行首次存款入金時,有幾件事情需要特別注意:
合法性、安全性、評價良好:確保所選擇的娛樂城是合法且受信任的。檢查其是否擁有有效的賭博牌照,以及是否採用加密技術來保護您的個人信息和交易。
首儲優惠與流水:許多娛樂城會為首次存款提供吸引人的獎勵,但相對的流水可能也會很高。
存款入金方式:查看可用的支付選項,是否適合自己,例如:USDT、超商儲值、銀行ATM轉帳等等。
提款出金方式:瞭解最低提款限制,綁訂多少流水才可以領出。
24小時客服:最好是有24小時客服,發生問題時馬上有人可以處理。
https://evaelfie.site/# eva elfie new videos
Incredible many of terrific advice!
cheap prescription drugs canadian online pharmacy medical pharmacies
ST666️ – Trang Chủ Chính Thức Số 1️⃣ Của Nhà Cái ST666
ST666 đã nhanh chóng trở thành điểm đến giải trí cá độ thể thao được yêu thích nhất hiện nay. Mặc dù chúng tôi mới xuất hiện trên thị trường cá cược trực tuyến Việt Nam gần đây, nhưng đã nhanh chóng thu hút sự quan tâm của cộng đồng người chơi trực tuyến. Đối với những người yêu thích trò chơi trực tuyến, nhà cái ST666 nhận được sự tin tưởng và tín nhiệm trọn vẹn từ họ. ST666 được coi là thiên đường cho những người chơi tham gia.
Giới Thiệu Nhà Cái ST666
ST666.BLUE – ST666 là nơi cá cược đổi thưởng trực tuyến được ưa chuộng nhất hiện nay. Tham gia vào trò chơi cá cược trực tuyến, người chơi không chỉ trải nghiệm các trò giải trí hấp dẫn mà còn có cơ hội nhận các phần quà khủng thông qua các kèo cá độ. Với những phần thưởng lớn, người chơi có thể thay đổi cuộc sống của mình.
Giới Thiệu Nhà Cái ST666 BLUE
Thông tin về nhà cái ST666
ST666 là Gì?
Nhà cái ST666 là một sân chơi cá cược đổi thưởng trực tuyến, chuyên cung cấp các trò chơi cá cược đổi thưởng có thưởng tiền mặt. Điều này bao gồm các sản phẩm như casino, bắn cá, thể thao, esports… Người chơi có thể tham gia nhiều trò chơi hấp dẫn khi đăng ký, đặt cược và có cơ hội nhận thưởng lớn nếu chiến thắng hoặc mất số tiền cược nếu thất bại.
Nhà Cái ST666 – Sân Chơi Cá Cược An Toàn
Nhà Cái ST666 – Sân Chơi Cá Cược Trực Tuyến
Nguồn Gốc Thành Lập Nhà Cái ST666
Nhà cái ST666 được thành lập và ra mắt vào năm 2020 tại Campuchia, một quốc gia nổi tiếng với các tập đoàn giải trí cá cược đổi thưởng. Xuất hiện trong giai đoạn phát triển mạnh mẽ của ngành cá cược, ST666 đã để lại nhiều dấu ấn. Được bảo trợ tài chính bởi tập đoàn danh tiếng Venus Casino, thương hiệu đã mở rộng hoạt động khắp Đông Nam Á và lan tỏa sang cả các quốc gia Châu Á, bao gồm cả Trung Quốc
game online e1_1c88
娛樂城首儲
初次接觸線上娛樂城的玩家一定對選擇哪間娛樂城有障礙,首要條件肯定是評價良好的娛樂城,其次才是哪間娛樂城優惠最誘人,娛樂城體驗金多少、娛樂城首儲一倍可以拿多少等等…本篇文章會告訴你娛樂城優惠怎麼挑,首儲該注意什麼。
娛樂城首儲該注意什麼?
當您決定好娛樂城,考慮在娛樂城進行首次存款入金時,有幾件事情需要特別注意:
合法性、安全性、評價良好:確保所選擇的娛樂城是合法且受信任的。檢查其是否擁有有效的賭博牌照,以及是否採用加密技術來保護您的個人信息和交易。
首儲優惠與流水:許多娛樂城會為首次存款提供吸引人的獎勵,但相對的流水可能也會很高。
存款入金方式:查看可用的支付選項,是否適合自己,例如:USDT、超商儲值、銀行ATM轉帳等等。
提款出金方式:瞭解最低提款限制,綁訂多少流水才可以領出。
24小時客服:最好是有24小時客服,發生問題時馬上有人可以處理。
เว็บ DNABET ออนไลน์: สู่ทาง ประสบการณ์ การเล่น ที่ไม่เหมือน ที่ทุกท่าน เคย พบ!
DNABET ยังคง เป็น เลือกที่คนนิยม ใน แฟน การพนัน ทางอินเทอร์เน็ต ในประเทศไทย นี้.
ไม่จำเป็นต้อง เสียเวลา ในการเลือก แข่ง DNABET เพราะที่นี่คือที่ที่ ไม่ต้อง เลือกที่จะ จะได้ หรือไม่ได้รับ!
DNABET มีค่า ราคาจ่าย ทุกราคา หวยที่ สูง ตั้งแต่ 900 บาท ขึ้นไป เมื่อ คุณ ถูกรางวัลแล้ว จะได้รับ รางวัลมากมาย กว่า เว็บอื่น ๆ ที่ เคยเล่น.
นอกจากนี้ DNABET ยัง มี ลอตเตอรี่ ที่คุณสามารถทำการเลือก มากมายถึง 20 หวย ทั่วโลก ทำให้ เลือก ตามใจต้องการ ได้อย่างหลากหลายแบบ.
ไม่ว่าจะเป็น หวยรัฐบาล หวยหุ้น ยี่กี ฮานอย ลาว และ ลอตเตอรี่ มีราคา เพียงแค่ 80 บาท.
ทาง DNABET มั่นคง ในเรื่องการเงิน โดยที่ ได้รับ เปลี่ยนชื่อ ชันเจน เป็น DNABET เพื่อ เสริมฐานลูกค้าที่มั่นใจ และ ปรับปรุงระบบให้ สะดวกสบายมาก ขึ้นไป.
นอกจากนี้ DNABET ยังมีโปรโมชั่น โปรโมชั่น ประจำเดือนที่สะสมยอดแทงแล้วได้รับรางวัล หลายรายการ เช่นเดียวกับ โปรโมชั่น สมาชิกใหม่ ท่านสมัคร ในวันนี้ จะได้รับ โบนัสเพิ่มทันที 500 บาท หรือเครดิตทดลองเล่นฟรี ไม่ต้องจ่าย เงิน.
นอกจากนี้ DNABET ยังมีโปรโมชั่น ประจำเดือนที่ ท่าน และ DNABET การเดิมพัน หวย ของท่านเอง พร้อม รางวัล และ เหล่าโปรโมชั่น ที่ มาก ที่สุด ปี 2024.
อย่า ปล่อย โอกาสที่ดีนี้ ไป มาเป็นส่วนหนึ่งของ DNABET และ เพลิดเพลินไปกับ ประสบการณ์ การเดิมพันที่ไม่เหมือนใคร ทุกท่าน มีโอกาสจะ เป็นเศรษฐี ได้ เพียง แค่ท่าน เลือก DNABET เว็บแทงหวย ออนไลน์ ที่ปลอดภัย และ มีสมาชิกมากที่สุด ในประเทศไทย!
similar dating sites like mingle2: http://sweetiefox.pro/# sweetie fox full video
mia malkova videos: mia malkova movie – mia malkova photos
Appreciate it. Numerous material.
canada drugs viagra pharmacy 100mg viagra from canada
https://miamalkova.life/# mia malkova latest
eva elfie hd: eva elfie new videos – eva elfie new video
1881
Very good data. Thanks.
prescription cost comparison canada pharmacy online orders price prescription drugs
fox sweetie: sweetie fox – fox sweetie
Nicely expressed indeed. .
online pharmacy without prescription https://canadiandrugsus.com/ discount pharmacies
https://lanarhoades.pro/# lana rhoades
You said that exceptionally well!
canadian cialis erectile dysfunction pills canadian prescription drugs
singles to meet: http://sweetiefox.pro/# sweetie fox new
sweetie fox full: sweetie fox cosplay – sweetie fox full
https://salda.ws/meet/notes.php?id=12681
Great stuff. Thanks a lot.
online pharmacy usa highest rated canadian pharmacies canada drugs pharmacy
https://evaelfie.site/# eva elfie full videos
This is nicely said. .
drug stores near me https://canadianpharmacylist.com/ prescription price comparison
lana rhoades pics: lana rhoades full video – lana rhoades unleashed
lana rhoades pics: lana rhoades – lana rhoades hot
Terrific posts. Many thanks!
online pharmacy reviews pharmacy near me drugstore online
site porn
http://evaelfie.site/# eva elfie hot
sweetie fox full: sweetie fox video – sweetie fox new
Effectively spoken indeed! .
global pharmacy canada https://canadianpillsusa.com/ canadadrugstore365
online ukraine dating: http://lanarhoades.pro/# lana rhoades boyfriend
kantorbola link alternatif
KANTORBOLA situs gamin online terbaik 2024 yang menyediakan beragam permainan judi online easy to win , mulai dari permainan slot online , taruhan judi bola , taruhan live casino , dan toto macau . Dapatkan promo terbaru kantor bola , bonus deposit harian , bonus deposit new member , dan bonus mingguan . Kunjungi link kantorbola untuk melakukan pendaftaran .
You said it wonderfully!
online medicine order discount aarp recommended canadian pharmacies best price prescription drugs
Situs Judi: Platform Togel Daring Terbesar dan Terjamin
Situs Judi telah menjadi salah satu situs judi online terbesar dan terjamin di Indonesia. Dengan beragam pasaran yang disediakan dari Semar Group, Situs Judi menawarkan sensasi main togel yang tak tertandingi kepada para penggemar judi daring.
Market Terunggul dan Terpenuhi
Dengan total 56 pasaran, Portal Judi memperlihatkan berbagai opsi terbaik dari market togel di seluruh dunia. Mulai dari pasaran klasik seperti Sydney, Singapore, dan Hongkong hingga market eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan pasaran favorit mereka dengan mudah.
Cara Bermain yang Praktis
Ngamenjitu menyediakan petunjuk cara main yang praktis dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di platform Ngamenjitu.
Rekapitulasi Terakhir dan Informasi Terkini
Pemain dapat mengakses hasil terakhir dari setiap market secara real-time di Situs Judi. Selain itu, info paling baru seperti jadwal bank daring, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Bermacam-macam Jenis Game
Selain togel, Portal Judi juga menawarkan bervariasi jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati bervariasi pilihan permainan yang menarik dan menghibur.
Security dan Kepuasan Pelanggan Dijamin
Ngamenjitu mengutamakan keamanan dan kenyamanan pelanggan. Dengan sistem keamanan terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di situs ini.
Promosi-Promosi dan Bonus Istimewa
Portal Judi juga menawarkan berbagai promosi dan hadiah menarik bagi para pemain setia maupun yang baru bergabung. Dari bonus deposit hingga bonus referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan bonus yang ditawarkan.
Dengan semua fasilitas dan layanan yang ditawarkan, Portal Judi tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Ngamenjitu!
http://evaelfie.site/# eva elfie photo
mia malkova movie: mia malkova – mia malkova latest
lana rhoades hot: lana rhoades videos – lana rhoades
Wonderful write ups. With thanks!
canadian rx canada pharmaceuticals online meds online without doctor prescription
http://jogodeaposta.fun/# ganhar dinheiro jogando
aviator ghana: aviator game online – aviator bet
Seriously lots of beneficial facts.
best canadian pharmacies canadian pharmaceuticals online online pharmacy viagra
Stunning story there. What happened after? Good luck!
difference between citalopram and lexapro
pin-up casino entrar: pin-up cassino – pin up aviator
ddavp dosing for surgery
This is nicely put! .
canadian pharma companies best erectile dysfunction pills pharmacy online store
aviator sinyal hilesi: aviator sinyal hilesi – aviator oyna
https://aviatormocambique.site/# como jogar aviator em mocambique
zantac and cozaar interactions
Ngamenjitu
Situs Judi: Portal Togel Online Terluas dan Terpercaya
Situs Judi telah menjadi salah satu platform judi online terbesar dan terjamin di Indonesia. Dengan bervariasi market yang disediakan dari Grup Semar, Situs Judi menawarkan sensasi main togel yang tak tertandingi kepada para penggemar judi daring.
Market Terunggul dan Terlengkap
Dengan total 56 pasaran, Situs Judi memperlihatkan berbagai opsi terbaik dari market togel di seluruh dunia. Mulai dari market klasik seperti Sydney, Singapore, dan Hongkong hingga pasaran eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan pasaran favorit mereka dengan mudah.
Cara Bermain yang Praktis
Ngamenjitu menyediakan panduan cara bermain yang mudah dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di situs Situs Judi.
Rekapitulasi Terakhir dan Informasi Terkini
Pemain dapat mengakses hasil terakhir dari setiap pasaran secara real-time di Ngamenjitu. Selain itu, info paling baru seperti jadwal bank daring, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Berbagai Jenis Game
Selain togel, Situs Judi juga menawarkan berbagai jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati bervariasi pilihan permainan yang menarik dan menghibur.
Keamanan dan Kepuasan Klien Terjamin
Portal Judi mengutamakan keamanan dan kepuasan pelanggan. Dengan sistem keamanan terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di situs ini.
Promosi dan Bonus Istimewa
Situs Judi juga menawarkan bervariasi promosi dan bonus menarik bagi para pemain setia maupun yang baru bergabung. Dari bonus deposit hingga bonus referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan hadiah yang ditawarkan.
Dengan semua fitur dan pelayanan yang ditawarkan, Ngamenjitu tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Situs Judi!
aviator bet: aviator moçambique – aviator online
Beneficial postings. Thanks!
us pharmacy no prior prescription rx pharmacy walmart online pharmacy
depakote vs depakene
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
http://aviatormocambique.site/# aviator bet
aviator game: aviator ghana – aviator bet
Nicely put, Thanks!
prescription drugs without doctor approval best 10 online canadian pharmacies canadian drug
http://aviatormalawi.online/# aviator bet malawi login
pin-up casino login: pin up – pin-up casino
This is nicely said! !
pharmacy online cheap best erectile dysfunction pills list of legitimate canadian pharmacies
aviator: play aviator – play aviator
oclxm wwfal vsdgh adxus ajzrg yvppy
https://aviatorghana.pro/# aviator game
aviator: aviator – aviator mz
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
aviator pin up casino: pin up casino – pin up cassino online
Ngamenjitu Login
Portal Judi: Situs Lotere Daring Terluas dan Terpercaya
Situs Judi telah menjadi salah satu portal judi online terluas dan terjamin di Indonesia. Dengan bervariasi market yang disediakan dari Semar Group, Portal Judi menawarkan sensasi bermain togel yang tak tertandingi kepada para penggemar judi daring.
Pasaran Terbaik dan Terpenuhi
Dengan total 56 pasaran, Ngamenjitu menampilkan beberapa opsi terbaik dari market togel di seluruh dunia. Mulai dari market klasik seperti Sydney, Singapore, dan Hongkong hingga pasaran eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan market favorit mereka dengan mudah.
Cara Bermain yang Sederhana
Portal Judi menyediakan tutorial cara bermain yang praktis dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di situs Situs Judi.
Rekapitulasi Terkini dan Informasi Terkini
Pemain dapat mengakses hasil terakhir dari setiap market secara real-time di Situs Judi. Selain itu, informasi terkini seperti jadwal bank daring, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Bermacam-macam Jenis Permainan
Selain togel, Ngamenjitu juga menawarkan berbagai jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati bervariasi pilihan permainan yang menarik dan menghibur.
Keamanan dan Kepuasan Pelanggan Dijamin
Portal Judi mengutamakan keamanan dan kenyamanan pelanggan. Dengan sistem security terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di platform ini.
Promosi dan Bonus Menarik
Ngamenjitu juga menawarkan bervariasi promosi dan bonus menarik bagi para pemain setia maupun yang baru bergabung. Dari hadiah deposit hingga bonus referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan bonus yang ditawarkan.
Dengan semua fitur dan pelayanan yang ditawarkan, Portal Judi tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Portal Judi!
aviator jogo de aposta: jogos que dão dinheiro – jogo de aposta
Login Ngamenjitu
Portal Judi: Situs Lotere Online Terbesar dan Terjamin
Situs Judi telah menjadi salah satu portal judi online terbesar dan terpercaya di Indonesia. Dengan bervariasi market yang disediakan dari Grup Semar, Portal Judi menawarkan pengalaman main togel yang tak tertandingi kepada para penggemar judi daring.
Pasaran Terunggul dan Terlengkap
Dengan total 56 market, Situs Judi menampilkan beberapa opsi terbaik dari pasaran togel di seluruh dunia. Mulai dari market klasik seperti Sydney, Singapore, dan Hongkong hingga market eksotis seperti Thailand, Germany, dan Texas Day, setiap pemain dapat menemukan market favorit mereka dengan mudah.
Langkah Bermain yang Praktis
Situs Judi menyediakan petunjuk cara bermain yang praktis dipahami bagi para pemula maupun penggemar togel berpengalaman. Dari langkah-langkah pendaftaran hingga penarikan kemenangan, semua informasi tersedia dengan jelas di situs Ngamenjitu.
Ringkasan Terakhir dan Informasi Paling Baru
Pemain dapat mengakses hasil terakhir dari setiap pasaran secara real-time di Portal Judi. Selain itu, informasi terkini seperti jadwal bank daring, gangguan, dan offline juga disediakan untuk memastikan kelancaran proses transaksi.
Bermacam-macam Jenis Game
Selain togel, Ngamenjitu juga menawarkan bervariasi jenis permainan kasino dan judi lainnya. Dari bingo hingga roulette, dari dragon tiger hingga baccarat, setiap pemain dapat menikmati bervariasi pilihan permainan yang menarik dan menghibur.
Security dan Kenyamanan Klien Terjamin
Ngamenjitu mengutamakan keamanan dan kepuasan pelanggan. Dengan sistem security terbaru dan layanan pelanggan yang responsif, setiap pemain dapat bermain dengan nyaman dan tenang di platform ini.
Promosi-Promosi dan Hadiah Menarik
Portal Judi juga menawarkan berbagai promosi dan bonus istimewa bagi para pemain setia maupun yang baru bergabung. Dari hadiah deposit hingga hadiah referral, setiap pemain memiliki kesempatan untuk meningkatkan kemenangan mereka dengan hadiah yang ditawarkan.
Dengan semua fitur dan pelayanan yang ditawarkan, Portal Judi tetap menjadi pilihan utama bagi para penggemar judi online di Indonesia. Bergabunglah sekarang dan nikmati pengalaman bermain yang seru dan menguntungkan di Situs Judi!
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
aviator moçambique: aviator bet – como jogar aviator em moçambique
aviator: aviator – aviator bahis
pin-up casino login: pin up aviator – aviator pin up casino
обнал карт купить
Сознание сущности и опасностей привязанных с легализацией кредитных карт может помочь людям предупреждать атак и обеспечивать защиту свои финансовые состояния. Обнал (отмывание) кредитных карт — это процедура использования украденных или неправомерно приобретенных кредитных карт для проведения финансовых транзакций с целью замаскировать их происхождение и пресечь отслеживание.
Вот некоторые способов, которые могут содействовать в предотвращении обнала кредитных карт:
Сохранение личной информации: Будьте осторожными в контексте предоставления личных данных, особенно онлайн. Избегайте предоставления картовых номеров, кодов безопасности и дополнительных конфиденциальных данных на непроверенных сайтах.
Мощные коды доступа: Используйте мощные и уникальные пароли для своих банковских аккаунтов и кредитных карт. Регулярно изменяйте пароли.
Отслеживание транзакций: Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это способствует своевременному выявлению подозрительных транзакций.
Антивирусная защита: Используйте антивирусное программное обеспечение и актуализируйте его регулярно. Это поможет предотвратить вредоносные программы, которые могут быть использованы для кражи данных.
Осторожное взаимодействие в социальных сетях: Будьте осторожными в социальных сетях, избегайте публикации чувствительной информации, которая может быть использована для взлома вашего аккаунта.
Уведомление банка: Если вы заметили какие-либо подозрительные операции или утерю карты, сразу свяжитесь с вашим банком для отключения карты.
Образование: Будьте внимательными к новым методам мошенничества и обучайтесь тому, как противостоять их.
Избегая легковерия и осуществляя предупредительные действия, вы можете снизить риск стать жертвой обнала кредитных карт.
обнал карт купить
Незаконные платформы, где осуществляют обналичивание пластиковых карт, представляют собой веб-ресурсы, ориентированные на обсуждении и осуществлении незаконных операций с банковскими картами. На таких форумах пользователи обмениваются информацией, методами и опытом в области кэш-аута, что влечет за собой незаконные практики по получению доступа к денежным ресурсам.
Эти платформы могут предлагать разные сервисы, относящиеся с преступной деятельностью, например фальсификация, считывание, вредоносное программное обеспечение и другие методы для получения данных с банковских пластиковых карт. Также обсуждаются вопросы, касающиеся применением похищенных информации для совершения финансовых операций или снятия средств.
Пользователи незаконных форумов по обналичиванию банковских карт могут стремиться сохраняться неизвестными и избегать привлечения внимания правоохранительных органов. Участники могут обмениваться советами, предоставлять сервисы, относящиеся к обналом, а также совершать операции, целенаправленные на финансовое преступление.
Необходимо подчеркнуть, что содействие в таких практиках не только представляет собой нарушением правовых норм, но также может приводить к правовым последствиям и наказанию.
обнал карт купить
Покупка контрафактных банкнот является недозволенным или опасным действием, что способно закончиться важным правовым санкциям или вреду своей финансовой благосостояния. Вот некоторые другие примет, вследствие чего покупка контрафактных купюр является опасной или неуместной:
Нарушение законов:
Покупка иначе эксплуатация поддельных денег являются нарушением закона, подрывающим нормы территории. Вас могут подвергнуть себя судебному преследованию, что возможно привести к тюремному заключению, штрафам либо постановлению под стражу.
Ущерб доверию:
Контрафактные банкноты нарушают уверенность по отношению к финансовой механизму. Их использование формирует опасность для честных людей и предприятий, которые имеют возможность столкнуться с неожиданными перебоями.
Экономический ущерб:
Распространение лживых денег оказывает воздействие на экономику, приводя к рост цен и ухудшающая общую финансовую устойчивость. Это имеет возможность повлечь за собой утрате уважения к денежной системе.
Риск обмана:
Люди, которые, вовлечены в созданием фальшивых денег, не обязаны сохранять какие-то параметры характеристики. Контрафактные купюры могут быть легко распознаваемы, что в конечном счете приведет к расходам для тех, кто пытается их использовать.
Юридические последствия:
При случае задержания при использовании поддельных денег, вас способны оштрафовать, и вы столкнетесь с законными сложностями. Это может сказаться на вашем будущем, включая проблемы с поиском работы и кредитной историей.
Благосостояние общества и личное благополучие основываются на честности и доверии в финансовой деятельности. Приобретение лживых купюр нарушает эти принципы и может порождать серьезные последствия. Рекомендуется держаться законов и осуществлять только правомерными финансовыми действиями.
Обналичивание карт – это неправомерная деятельность, становящаяся все более широко распространенной в нашем современном мире электронных платежей. Этот вид мошенничества представляет серьезные вызовы для банков, правоохранительных органов и общества в целом. В данной статье мы рассмотрим частоту встречаемости обналичивания карт, используемые методы и возможные последствия для жертв и общества.
Частота обналичивания карт:
Обналичивание карт является достаточно распространенным явлением, и его частота постоянно растет с увеличением числа электронных транзакций. Киберпреступники применяют разные методы для получения доступа к финансовым средствам, включая фишинг, вредоносное программное обеспечение, скимминг и другие инновационные подходы.
Методы обналичивания карт:
Фишинг: Злоумышленники могут отправлять поддельные электронные сообщения или создавать веб-сайты, имитирующие банковские системы, с целью получения личной информации от владельцев карт.
Скимминг: Злоумышленники устанавливают устройства скиммеры на банкоматах или терминалах для считывания данных с магнитных полос карт.
Вредоносное программное обеспечение: Киберпреступники разрабатывают вредоносные программы, которые заражают компьютеры и мобильные устройства, чтобы получить доступ к личным данным и банковским счетам.
Сетевые атаки: Атаки на системы банков и платежных платформ могут привести к утечке информации о картах и, следовательно, к их обналичиванию.
Последствия обналичивания карт:
Финансовые потери для клиентов: Владельцы карт могут столкнуться с материальными потерями, так как средства могут быть списаны с их счетов без их ведома.
Угроза безопасности данных: Обналичивание карт подчеркивает угрозу безопасности личных данных, что может привести к краже личной и финансовой информации.
Ущерб репутации банков: Банки и другие финансовые учреждения могут столкнуться с утратой доверия со стороны клиентов, если их системы безопасности оказываются уязвимыми.
Проблемы для экономики: Обналичивание карт создает экономический ущерб, поскольку оно стимулирует дополнительные затраты на борьбу с мошенничеством и восстановление утраченных средств.
Борьба с обналичиванием карт:
Совершенствование технологий безопасности: Банки и финансовые институты постоянно совершенствуют свои системы безопасности, чтобы предотвратить несанкционированный доступ к картам.
Образование и информирование: Обучение клиентов о методах мошенничества и том, как защитить свои данные, является важным шагом в борьбе с обналичиванием карт.
Сотрудничество с правоохранительными органами: Банки активно сотрудничают с правоохранительными органами для выявления и пресечения преступных схем.
Заключение:
Обналичивание карт – серьезная угроза для финансовой стабильности и безопасности личных данных. Решение этой проблемы требует совместных усилий со стороны банков, правоохранительных органов и общества в целом. Только эффективная борьба с мошенничеством позволит обеспечить безопасность электронных платежей и защитить интересы всех участников финансовой системы.
Опасности поддельных 5000 рублей: Распространение контрафактных купюр и его результаты
В текущем обществе, где электронные платежи становятся все более широко используемыми, правонарушители не оставляют без внимания и традиционные методы мошенничества, такие как распространение контрафактных банкнот. В последние недели стало известно о нелегальной продаже фальшивых 5000 рублевых купюр, что представляет серьезную угрозу для финансовой инфраструктуры и сообщества в совокупности.
Способы передачи:
Мошенники активно используют неявные сети сети для сбыта поддельных 5000 рублей. На скрытых веб-ресурсах и незаконных форумах можно обнаружить предложения недостоверных банкнот. К удивлению, это создает хорошие условия для передачи недостоверных денег среди граждан.
Консеквенции для граждан:
Наличие недостоверных денег в циркуляции может иметь важные последствия для финансовой структуры и авторитета к денежной единице. Люди, не подозревая, что получили поддельные купюры, могут использовать их в разнообразных ситуациях, что в последней инстанции приводит к потере поверию к банкнотам точного номинала.
Угрозы для людей:
Гражданское население становятся вероятными потерпевшими недобросовестных лиц, когда они ненамеренно получают фальшивые деньги в транзакциях или при приобретениях. В следствие этого, они могут столкнуться с нелестными ситуациями, такими как отказ от признания коммерсантов принять недостоверные купюры или даже вероятность ответной ответственности за попытку расплаты контрафактными деньгами.
Борьба с распространением недостоверных денег:
В интересах гарантирования граждан от таких же проступков необходимо повысить мероприятия по обнаружению и предотвращению производству недостоверных денег. Это включает в себя работу в партнерстве между правоохранительными структурами и финансовыми институтами, а также повышение уровня подготовки населения относительно признаков контрафактных банкнот и техник их разгадывания.
Завершение:
Прокладывание контрафактных 5000 рублей – это серьезная опасность для финансовой устойчивости и безопасности сообщества. Сохранение доверия к денежной единице требует коллективных усилий со стороны властей, финансовых институтов и каждого гражданина. Важно быть внимательным и осведомленным, чтобы избежать прокладывание фальшивых денег и сохранить финансовые активы населения.
pin up aviator: aviator oyna – pin up aviator
aviator moçambique: como jogar aviator em moçambique – como jogar aviator
pin up casino: pin up – pin up cassino online
site de apostas: depósito mínimo 1 real – melhor jogo de aposta para ganhar dinheiro
can i buy zithromax over the counter: zithromax 1000 mg pills – zithromax 500mg price
В наше время все чаще возникает необходимость в переводе документов для различных целей. В Новосибирске есть множество агентств и переводчиков, специализирующихся на качественных переводах документов. Однако, помимо перевода, часто требуется также апостиль, который удостоверяет подлинность документа за рубежом.
Получить апостиль в Новосибирске — это несложно, если обратиться к профессионалам. Многие агентства, занимающиеся переводами, также предоставляют услуги по оформлению апостиля. Это удобно, т.к. можно сделать все необходимые процедуры в одном месте.
При выборе агентства для перевода документов и оформления апостиля важно обращать внимание на их опыт, репутацию и скорость выполнения заказов. Важно найти надежного партнера, который обеспечит качественный и своевременный сервис. В Новосибирске есть множество проверенных организаций, готовых помочь в оформлении всех необходимых документов для вашего спокойствия и уверенности в законности процесса.
https://salda.ws/meet/notes.php?id=12681
aviator hilesi: pin up aviator – aviator oyna slot
zithromax for sale 500 mg – https://azithromycin.pro/zithromax-syphillis.html zithromax buy
Grdat poѕt. I was checking continuously this Ьlog annd I’m impressed!
Extremely useful information particularly the last part 🙂 I care for suich info
a lot. I was looking for this particular ijformatіon fⲟr
a long time. Thank ʏou and ƅest of ⅼuck.
aviator moçambique: aviator mz – aviator moçambique
melhor jogo de aposta: melhor jogo de aposta – aplicativo de aposta
zithromax 500 without prescription: zithromax allergic reaction buy zithromax no prescription
pin up bet: pin up bet – pin up cassino online
Mагазин фальшивых денег купить
Покупка контрафактных банкнот считается противозаконным или опасительным делом, которое в состоянии повлечь за собой серьезным юридическими санкциям и повреждению индивидуальной финансовой надежности. Вот некоторые другие последствий, вследствие чего получение фальшивых купюр представляет собой опасной и недопустимой:
Нарушение законов:
Покупка или воспользование контрафактных банкнот приравниваются к нарушением закона, подрывающим нормы общества. Вас в состоянии подвергнуться уголовной ответственности, что потенциально закончиться аресту, штрафам иначе постановлению под стражу.
Ущерб доверию:
Контрафактные банкноты подрывают веру по отношению к финансовой системе. Их поступление в оборот порождает угрозу для честных гражданских лиц и коммерческих структур, которые в состоянии столкнуться с непредвиденными перебоями.
Экономический ущерб:
Разнос лживых денег осуществляет воздействие на хозяйство, вызывая денежное расширение и ухудшая глобальную финансовую стабильность. Это способно привести к потере доверия к денежной единице.
Риск обмана:
Люди, какие, осуществляют изготовлением фальшивых купюр, не обязаны сохранять какие-нибудь нормы степени. Лживые купюры могут стать легко обнаружены, что, в итоге повлечь за собой убыткам для тех, кто стремится применять их.
Юридические последствия:
При случае задержания при использовании фальшивых денег, вас в состоянии наказать штрафом, и вы столкнетесь с юридическими проблемами. Это может сказаться на вашем будущем, в том числе возможные проблемы с трудоустройством и кредитной историей.
Благосостояние общества и личное благополучие зависят от честности и доверии в денежной области. Закупка поддельных денег нарушает эти принципы и может иметь серьезные последствия. Предлагается придерживаться правил и вести только законными финансовыми операциями.
Где купить фальшивые деньги
Покупка поддельных денег является неправомерным иначе рискованным действием, что может повлечь за собой глубоким правовым санкциям иначе постраданию своей денежной устойчивости. Вот несколько других причин, по какой причине покупка лживых купюр является опасной либо неуместной:
Нарушение законов:
Получение либо эксплуатация фальшивых купюр считаются преступлением, нарушающим положения страны. Вас имеют возможность подвергнуть уголовной ответственности, что потенциально привести к задержанию, взысканиям иначе приводу в тюрьму.
Ущерб доверию:
Контрафактные деньги ослабляют веру в денежной организации. Их поступление в оборот создает риск для благоприятных личностей и коммерческих структур, которые в состоянии претерпеть неожиданными перебоями.
Экономический ущерб:
Разведение фальшивых банкнот влияет на экономическую сферу, вызывая инфляцию что ухудшает глобальную финансовую устойчивость. Это имеет возможность закончиться потере доверия к национальной валюте.
Риск обмана:
Лица, кто, осуществляют изготовлением контрафактных денег, не обязаны поддерживать какие-то уровни уровня. Контрафактные деньги могут стать легко обнаружены, что в итоге приведет к расходам для тех, кто пытается их использовать.
Юридические последствия:
При случае задержания при воспользовании лживых купюр, вас в состоянии взыскать штраф, и вы столкнетесь с юридическими проблемами. Это может сказаться на вашем будущем, включая возможные проблемы с трудоустройством с кредитной историей.
Благосостояние общества и личное благополучие зависят от правдивости и уважении в финансовой деятельности. Получение лживых банкнот нарушает эти принципы и может представлять серьезные последствия. Предлагается соблюдать законов и вести только легальными финансовыми сделками.
Fantastic posts. Thanks a lot.
northwestpharmacy doctor prescription cialis online pharmacy
Купил фальшивые рубли
Покупка поддельных банкнот приравнивается к незаконным и опасным поступком, что в состоянии повлечь за собой серьезным правовым воздействиям и повреждению индивидуальной финансовой благосостояния. Вот некоторые другие примет, почему приобретение контрафактных купюр считается рискованной иначе недопустимой:
Нарушение законов:
Закупка или применение поддельных купюр представляют собой преступлением, противоречащим нормы территории. Вас имеют возможность поддать уголовной ответственности, которое может привести к лишению свободы, взысканиям или лишению свободы.
Ущерб доверию:
Поддельные банкноты подрывают доверенность к денежной структуре. Их применение формирует угрозу для честных людей и бизнесов, которые могут попасть в неожиданными расходами.
Экономический ущерб:
Разведение фальшивых купюр причиняет воздействие на хозяйство, инициируя рост цен и ухудшающая общественную финансовую равновесие. Это имеет возможность повлечь за собой утрате уважения к денежной системе.
Риск обмана:
Личности, те, занимается производством лживых денег, не обязаны соблюдать какие-то уровни характеристики. Лживые бумажные деньги могут оказаться легко обнаружены, что, в конечном итоге повлечь за собой потерям для тех, кто пытается применять их.
Юридические последствия:
При событии попадания под арест при применении поддельных банкнот, вас имеют возможность наказать штрафом, и вы столкнетесь с юридическими трудностями. Это может оказать воздействие на вашем будущем, включая сложности с получением работы с кредитной историей.
Благосостояние общества и личное благополучие зависят от честности и доверии в финансовых отношениях. Приобретение фальшивых купюр нарушает эти принципы и может иметь серьезные последствия. Рекомендуем придерживаться правил и вести только правомерными финансовыми операциями.
Покупка поддельных купюр приравнивается к недозволенным иначе потенциально опасным действием, которое в состоянии повлечь за собой важным юридическими воздействиям либо повреждению своей финансовой устойчивости. Вот некоторые причин, вследствие чего приобретение лживых банкнот является рискованной либо неуместной:
Нарушение законов:
Закупка либо использование контрафактных денег приравниваются к правонарушением, противоречащим законы общества. Вас могут подвергнуться уголовной ответственности, что может закончиться лишению свободы, финансовым санкциям иначе приводу в тюрьму.
Ущерб доверию:
Поддельные банкноты ухудшают доверие в финансовой структуре. Их применение создает риск для надежных личностей и бизнесов, которые в состоянии столкнуться с неожиданными расходами.
Экономический ущерб:
Расширение контрафактных денег влияет на экономику, вызывая рост цен и ухудшающая общественную денежную устойчивость. Это может повлечь за собой потере доверия к валютной единице.
Риск обмана:
Личности, те, задействованы в изготовлением контрафактных денег, не обязаны поддерживать какие-либо уровни степени. Фальшивые банкноты могут оказаться легко обнаружены, что в итоге закончится убыткам для тех, кто стремится применять их.
Юридические последствия:
В ситуации задержания при применении контрафактных денег, вас в состоянии оштрафовать, и вы столкнетесь с юридическими проблемами. Это может оказать воздействие на вашем будущем, в том числе сложности с получением работы и историей кредита.
Благосостояние общества и личное благополучие зависят от правдивости и доверии в финансовых отношениях. Приобретение поддельных денег противоречит этим принципам и может обладать серьезные последствия. Предлагается придерживаться законов и заниматься исключительно законными финансовыми операциями.
Купить фальшивые рубли
Покупка контрафактных банкнот является противозаконным или потенциально опасным поступком, что в состоянии закончиться глубоким законным воздействиям либо ущербу вашей денежной устойчивости. Вот несколько других приводов, почему получение фальшивых денег считается опасительной иначе недопустимой:
Нарушение законов:
Получение либо использование поддельных денег являются противоправным деянием, противоречащим правила государства. Вас имеют возможность подвергнуться юридическим последствиям, что возможно повлечь за собой задержанию, финансовым санкциям или приводу в тюрьму.
Ущерб доверию:
Лживые банкноты нарушают доверенность по отношению к финансовой механизму. Их поступление в оборот формирует возможность для порядочных людей и предприятий, которые имеют возможность претерпеть непредвиденными расходами.
Экономический ущерб:
Разнос контрафактных банкнот причиняет воздействие на хозяйство, приводя к распределение денег и подрывая глобальную финансовую равновесие. Это в состоянии повлечь за собой потере доверия к национальной валюте.
Риск обмана:
Личности, те, занимается созданием контрафактных денег, не обязаны соблюдать какие-нибудь уровни характеристики. Лживые бумажные деньги могут быть легко выявлены, что, в итоге послать в ущербу для тех пытается использовать их.
Юридические последствия:
При событии захвата за использование лживых денег, вас имеют возможность взыскать штраф, и вы столкнетесь с юридическими трудностями. Это может оказать воздействие на вашем будущем, с учетом возможные проблемы с получением работы и кредитной историей.
Общественное и личное благополучие зависят от честности и доверии в финансовых отношениях. Закупка поддельных купюр не соответствует этим принципам и может порождать серьезные последствия. Советуем держаться законов и осуществлять только законными финансовыми транзакциями.
Regards! I like it!
walmart pharmacy price check https://canadiandrugsus.com/ prescription drugs without prior prescription
Seriously plenty of useful advice!
online pharmacies no prescription online pharmacies in usa best online canadian pharmacy
indian pharmacy paypal: india pharmacy – reputable indian online pharmacy indianpharm.store
My brother recommended I might like this website. He was entirely right.
This post truly made my day. You cann’t imagine simply how
much time I had spent for this information! Thank you!
Heya! I just wanted to ask if you ever have any problems with hackers?
My last blog (wordpress) was hacked and I ended up losing a few months of hard
work due to no data backup. Do you have any solutions
to stop hackers?
reputable indian pharmacies Online medicine home delivery indian pharmacy paypal indianpharm.store
Покупка фальшивых банкнот считается неправомерным иначе рискованным действием, что способно повлечь за собой глубоким юридическими наказаниям или ущербу своей финансовой стабильности. Вот несколько приводов, вследствие чего получение контрафактных банкнот является потенциально опасной или неприемлемой:
Нарушение законов:
Закупка и воспользование поддельных банкнот приравниваются к преступлением, нарушающим правила страны. Вас могут подвергнуть себя судебному преследованию, что может привести к тюремному заключению, денежным наказаниям либо лишению свободы.
Ущерб доверию:
Контрафактные банкноты подрывают доверие по отношению к денежной организации. Их применение формирует опасность для порядочных гражданских лиц и организаций, которые в состоянии завязать неожиданными перебоями.
Экономический ущерб:
Расширение контрафактных банкнот осуществляет воздействие на хозяйство, инициируя распределение денег и ухудшающая общую экономическую устойчивость. Это может закончиться потере доверия в валютной единице.
Риск обмана:
Личности, которые, вовлечены в изготовлением фальшивых денег, не обязаны поддерживать какие-либо нормы уровня. Контрафактные бумажные деньги могут выйти легко распознаваемы, что, в итоге послать в убыткам для тех, кто стремится воспользоваться ими.
Юридические последствия:
В ситуации захвата при воспользовании поддельных купюр, вас в состоянии взыскать штраф, и вы столкнетесь с юридическими проблемами. Это может сказаться на вашем будущем, с учетом трудности с трудоустройством и историей кредита.
Общественное и личное благополучие зависят от честности и доверии в денежной области. Приобретение поддельных банкнот противоречит этим принципам и может порождать серьезные последствия. Советуем придерживаться норм и заниматься только законными финансовыми транзакциями.
Very good write ups. Thanks a lot.
ordering prescriptions from canada legally canada pharmaceutical online ordering canadian meds
Kudos, I like this!
my canadian pharmacy https://canadianpharmacylist.com/ canada meds
buying from online mexican pharmacy: order online from a Mexican pharmacy – best online pharmacies in mexico mexicanpharm.shop
mexican border pharmacies shipping to usa: Mexico pharmacy price list – purple pharmacy mexico price list mexicanpharm.shop
After checking out a handful of the blog posts on your web site,
I really appreciate your technique of writing a blog. I saved
as a favorite it to my bookmark website list and will be checking back soon. Take a look at
my website too and tell me what you think.
cozaar drug side effects
You actually reported it superbly.
buy prescription drugs online canada drug pharmacy canada pharmacies
mexican online pharmacies prescription drugs mexico drug stores pharmacies mexican mail order pharmacies mexicanpharm.shop
best online pharmacies in mexico: order online from a Mexican pharmacy – medicine in mexico pharmacies mexicanpharm.shop
citalopram alcohol interactions
You made your position very effectively!.
canadian pharmacies without prescriptions https://canadianpillsusa.com/ pharmacy drug store
depakote pregnancy
ddavp rxlist
http://mexicanpharm24.shop/# mexico drug stores pharmacies mexicanpharm.shop
https://indianpharm24.shop/# cheapest online pharmacy india indianpharm.store
купить фальшивые деньги
Покупка лживых банкнот считается незаконным и рискованным делом, что может привести к серьезным юридическим последствиям иначе постраданию личной денежной надежности. Вот несколько последствий, вследствие чего получение контрафактных купюр является потенциально опасной и недопустимой:
Нарушение законов:
Приобретение и использование фальшивых денег представляют собой правонарушением, нарушающим нормы территории. Вас в состоянии подвергнуть себя юридическим последствиям, что потенциально повлечь за собой задержанию, финансовым санкциям либо лишению свободы.
Ущерб доверию:
Лживые деньги ослабляют доверие по отношению к денежной структуре. Их обращение формирует риск для порядочных гражданских лиц и организаций, которые в состоянии столкнуться с непредвиденными потерями.
Экономический ущерб:
Расширение поддельных купюр влияет на экономику, приводя к рост цен и ухудшающая всеобщую финансовую устойчивость. Это способно повлечь за собой потере доверия к денежной системе.
Риск обмана:
Лица, кто, занимается изготовлением лживых денег, не обязаны поддерживать какие угодно стандарты уровня. Фальшивые купюры могут стать легко обнаружены, что, в конечном итоге закончится потерям для тех, кто попытается воспользоваться ими.
Юридические последствия:
При случае захвата при использовании контрафактных денег, вас могут взыскать штраф, и вы столкнетесь с юридическими трудностями. Это может повлиять на вашем будущем, включая проблемы с получением работы и кредитной историей.
Благосостояние общества и личное благополучие зависят от честности и доверии в финансовой деятельности. Приобретение контрафактных денег противоречит этим принципам и может представлять серьезные последствия. Рекомендуется держаться правил и заниматься только правомерными финансовыми сделками.
Фальшивые 5000 купить
Опасности поддельными 5000 рублей: Распространение фальшивых купюр и его последствия
В нынешнем обществе, где цифровые платежи становятся все более расширенными, мошенники не оставляют без внимания и классические методы преступной деятельности, такие как раскрутка фальшивых банкнот. В последнее время стало известно о незаконной продаже контрафактных 5000 рублевых купюр, что представляет серьезную опасность для финансовых институтов и сообщества в итоге.
Способы торговли:
Нарушители активно используют неявные маршруты сетевого пространства для сбыта контрафактных 5000 рублей. На скрытых веб-ресурсах и неправомерных форумах можно обнаружить предлагаемые условия недостоверных банкнот. К неудовольствию, это создает хорошие условия для дистрибуции недостоверных денег среди граждан.
Консеквенции для общества:
Возможность поддельных денег в обращении может иметь серьезные последствия для финансовой системы и кредитоспособности к национальной валюте. Люди, не замечая, что получили недостоверные купюры, могут использовать их в разнообразных ситуациях, что в финале приводит к потере авторитету к банкнотам конкретного номинала.
Угрозы для населения:
Граждане становятся вероятными потерпевшими недобросовестных лиц, когда они случайно получают недостоверные деньги в сделках или при приобретении. В следствие этого, они могут столкнуться с нелестными ситуациями, такими как отказ от приема коммерсантов принять поддельные купюры или даже вероятность ответной ответственности за труд расплаты поддельными деньгами.
Борьба с дистрибуцией фальшивых денег:
Для предотвращения граждан от подобных преступлений необходимо усилить меры по выявлению и пресечению производственной деятельности поддельных денег. Это включает в себя взаимодействие между полицейскими и банками, а также расширение градуса образования граждан относительно признаков недостоверных банкнот и практик их разгадывания.
Итог:
Диффузия недостоверных 5000 рублей – это серьезная опасность для финансовой устойчивости и безопасности общества. Сохранение авторитета к государственной валюте требует согласованных действий со стороны государственных органов, финансовых организаций и всех. Важно быть осторожным и осведомленным, чтобы предупредить распространение недостоверных денег и обеспечить финансовые активы населения.
Купить фальшивые рубли
Покупка контрафактных банкнот представляет собой недозволенным и рискованным действием, что может повлечь за собой глубоким юридическим наказаниям иначе вреду вашей финансовой устойчивости. Вот некоторые приводов, вследствие чего приобретение фальшивых банкнот приравнивается к потенциально опасной или неприемлемой:
Нарушение законов:
Получение иначе воспользование фальшивых денег являются правонарушением, нарушающим нормы страны. Вас имеют возможность подвергнуться уголовной ответственности, что может повлечь за собой тюремному заключению, денежным наказаниям иначе приводу в тюрьму.
Ущерб доверию:
Лживые банкноты ослабляют доверие к финансовой структуре. Их обращение возникает возможность для надежных гражданских лиц и организаций, которые имеют возможность попасть в неожиданными перебоями.
Экономический ущерб:
Расширение лживых банкнот осуществляет воздействие на экономику, приводя к распределение денег и ухудшая общественную финансовую устойчивость. Это имеет возможность послать в потере доверия в национальной валюте.
Риск обмана:
Люди, те, занимается созданием фальшивых купюр, не обязаны соблюдать какие угодно нормы характеристики. Контрафактные купюры могут стать легко выявлены, что, в конечном итоге закончится убыткам для тех попытается применять их.
Юридические последствия:
В ситуации захвата при воспользовании фальшивых денег, вас имеют возможность наказать штрафом, и вы столкнетесь с юридическими трудностями. Это может повлиять на вашем будущем, включая сложности с трудоустройством и кредитной историей.
Общественное и индивидуальное благосостояние основываются на честности и доверии в финансовой сфере. Закупка поддельных денег противоречит этим принципам и может иметь серьезные последствия. Советуем придерживаться законов и осуществлять только законными финансовыми действиями.
Thanks a lot! Lots of knowledge!
canadian pharmacy no prescription needed buying prescription drugs canada best canadian mail order pharmacies
pharmacies in mexico that ship to usa: Mexico pharmacy online – medicine in mexico pharmacies mexicanpharm.shop
http://canadianpharmlk.com/# canada rx pharmacy world canadianpharm.store
http://indianpharm24.com/# indianpharmacy com indianpharm.store
You said it well.
rx pharmacy https://canadiantabsusa.com/ international pharmacy
http://indianpharm24.com/# Online medicine order indianpharm.store
mexican mail order pharmacies Mexico pharmacy price list purple pharmacy mexico price list mexicanpharm.shop
buying prescription drugs in mexico online: Mexico pharmacy online – best online pharmacies in mexico mexicanpharm.shop
http://indianpharm24.shop/# indianpharmacy com indianpharm.store
https://indianpharm24.shop/# indianpharmacy com indianpharm.store
Обналичивание карт – это неправомерная деятельность, становящаяся все более широко распространенной в нашем современном мире электронных платежей. Этот вид мошенничества представляет значительные вызовы для банков, правоохранительных органов и общества в целом. В данной статье мы рассмотрим частоту встречаемости обналичивания карт, используемые методы и возможные последствия для жертв и общества.
Частота обналичивания карт:
Обналичивание карт является достаточно распространенным явлением, и его частота постоянно растет с увеличением числа электронных транзакций. Киберпреступники применяют разнообразные методы для получения доступа к финансовым средствам, включая фишинг, вредоносное программное обеспечение, скимминг и другие инновационные подходы.
Методы обналичивания карт:
Фишинг: Злоумышленники могут отправлять поддельные электронные сообщения или создавать веб-сайты, имитирующие банковские системы, с целью получения личной информации от владельцев карт.
Скимминг: Злоумышленники устанавливают устройства скиммеры на банкоматах или терминалах для считывания данных с магнитных полос карт.
Вредоносное программное обеспечение: Киберпреступники разрабатывают вредоносные программы, которые заражают компьютеры и мобильные устройства, чтобы получить доступ к личным данным и банковским счетам.
Сетевые атаки: Атаки на системы банков и платежных платформ могут привести к утечке информации о картах и, следовательно, к их обналичиванию.
Последствия обналичивания карт:
Финансовые потери для клиентов: Владельцы карт могут столкнуться с денежными потерями, так как средства могут быть списаны с их счетов без их ведома.
Угроза безопасности данных: Обналичивание карт подчеркивает угрозу безопасности личных данных, что может привести к краже личной и финансовой информации.
Ущерб репутации банков: Банки и другие финансовые учреждения могут столкнуться с утратой доверия со стороны клиентов, если их системы безопасности оказываются уязвимыми.
Проблемы для экономики: Обналичивание карт создает экономический ущерб, поскольку оно стимулирует дополнительные затраты на борьбу с мошенничеством и восстановление утраченных средств.
Борьба с обналичиванием карт:
Совершенствование технологий безопасности: Банки и финансовые институты постоянно совершенствуют свои системы безопасности, чтобы предотвратить несанкционированный доступ к картам.
Образование и информирование: Обучение клиентов о методах мошенничества и том, как защитить свои данные, является важным шагом в борьбе с обналичиванием карт.
Сотрудничество с правоохранительными органами: Банки активно сотрудничают с правоохранительными органами для выявления и пресечения преступных схем.
Заключение:
Обналичивание карт – весомая угроза для финансовой стабильности и безопасности личных данных. Решение этой проблемы требует совместных усилий со стороны банков, правоохранительных органов и общества в целом. Только эффективная борьба с мошенничеством позволит обеспечить безопасность электронных платежей и защитить интересы всех участников финансовой системы.
https://indianpharm24.shop/# india pharmacy mail order indianpharm.store
http://indianpharm24.shop/# indian pharmacy indianpharm.store
buying prescription drugs in mexico: Mexico pharmacy online – reputable mexican pharmacies online mexicanpharm.shop
обнал карт форум
Обналичивание карт – это противозаконная деятельность, становящаяся все более популярной в нашем современном мире электронных платежей. Этот вид мошенничества представляет серьезные вызовы для банков, правоохранительных органов и общества в целом. В данной статье мы рассмотрим частоту встречаемости обналичивания карт, используемые методы и возможные последствия для жертв и общества.
Частота обналичивания карт:
Обналичивание карт является достаточно распространенным явлением, и его частота постоянно растет с увеличением числа электронных транзакций. Киберпреступники применяют разные методы для получения доступа к финансовым средствам, включая фишинг, вредоносное программное обеспечение, скимминг и другие инновационные подходы.
Методы обналичивания карт:
Фишинг: Злоумышленники могут отправлять ложные электронные сообщения или создавать веб-сайты, имитирующие банковские системы, с целью получения личной информации от владельцев карт.
Скимминг: Злоумышленники устанавливают устройства скиммеры на банкоматах или терминалах для считывания данных с магнитных полос карт.
Вредоносное программное обеспечение: Киберпреступники разрабатывают вредоносные программы, которые заражают компьютеры и мобильные устройства, чтобы получить доступ к личным данным и банковским счетам.
Сетевые атаки: Атаки на системы банков и платежных платформ могут привести к утечке информации о картах и, следовательно, к их обналичиванию.
Последствия обналичивания карт:
Финансовые потери для клиентов: Владельцы карт могут столкнуться с денежными потерями, так как средства могут быть списаны с их счетов без их ведома.
Угроза безопасности данных: Обналичивание карт подчеркивает угрозу безопасности личных данных, что может привести к краже личной и финансовой информации.
Ущерб репутации банков: Банки и другие финансовые учреждения могут столкнуться с утратой доверия со стороны клиентов, если их системы безопасности оказываются уязвимыми.
Проблемы для экономики: Обналичивание карт создает экономический ущерб, поскольку оно стимулирует дополнительные затраты на борьбу с мошенничеством и восстановление утраченных средств.
Борьба с обналичиванием карт:
Совершенствование технологий безопасности: Банки и финансовые институты постоянно совершенствуют свои системы безопасности, чтобы предотвратить несанкционированный доступ к картам.
Образование и информирование: Обучение клиентов о методах мошенничества и том, как защитить свои данные, является важным шагом в борьбе с обналичиванием карт.
Сотрудничество с правоохранительными органами: Банки активно сотрудничают с правоохранительными органами для выявления и пресечения преступных схем.
Заключение:
Обналичивание карт – весомая угроза для финансовой стабильности и безопасности личных данных. Решение этой проблемы требует совместных усилий со стороны банков, правоохранительных органов и общества в целом. Только эффективная борьба с мошенничеством позволит обеспечить безопасность электронных платежей и защитить интересы всех участников финансовой системы.
canadian mail order pharmacy: canadian pharmacy – canadian pharmacy 24h com canadianpharm.store
http://canadianpharmlk.shop/# legit canadian pharmacy canadianpharm.store
Покупка поддельных банкнот представляет собой неправомерным или опасительным поступком, которое способно привести к глубоким юридическими последствиям или постраданию личной денежной устойчивости. Вот несколько примет, вследствие чего закупка контрафактных денег считается потенциально опасной и недопустимой:
Нарушение законов:
Получение и воспользование поддельных купюр приравниваются к преступлением, нарушающим нормы страны. Вас в состоянии подвергнуть наказанию, которое может послать в тюремному заключению, взысканиям или тюремному заключению.
Ущерб доверию:
Контрафактные купюры подрывают доверенность по отношению к финансовой механизму. Их использование порождает возможность для надежных граждан и организаций, которые имеют возможность попасть в внезапными потерями.
Экономический ущерб:
Разведение поддельных купюр оказывает воздействие на экономическую сферу, вызывая рост цен и подрывая глобальную финансовую равновесие. Это может послать в потере уважения к национальной валюте.
Риск обмана:
Люди, кто, занимается производством фальшивых купюр, не обязаны соблюдать какие-нибудь параметры степени. Поддельные банкноты могут оказаться легко выявлены, что, в итоге закончится расходам для тех собирается применять их.
Юридические последствия:
В ситуации захвата при использовании контрафактных банкнот, вас в состоянии принудительно обложить штрафами, и вы столкнетесь с юридическими трудностями. Это может сказаться на вашем будущем, включая сложности с трудоустройством и историей кредита.
Общественное и индивидуальное благосостояние зависят от честности и доверии в финансовой деятельности. Приобретение контрафактных банкнот не соответствует этим принципам и может порождать серьезные последствия. Рекомендуем держаться законов и заниматься только законными финансовыми транзакциями.
http://canadianpharmlk.shop/# canada ed drugs canadianpharm.store
http://indianpharm24.com/# indian pharmacy paypal indianpharm.store
mexico pharmacy: order online from a Mexican pharmacy – purple pharmacy mexico price list mexicanpharm.shop
india pharmacy mail order buy medicines online in india buy medicines online in india indianpharm.store
http://indianpharm24.com/# india pharmacy indianpharm.store
Very soon this web page will be famous among all blogging users,
due to it’s pleasant articles or reviews
https://canadianpharmlk.com/# best canadian online pharmacy reviews canadianpharm.store
https://canadianpharmlk.shop/# cheapest pharmacy canada canadianpharm.store
buying prescription drugs in mexico: mexican pharmacy – mexican online pharmacies prescription drugs mexicanpharm.shop
https://canadianpharmlk.com/# canadian pharmacy online canadianpharm.store
77 canadian pharmacy: Canada pharmacy – canadian pharmacy 365 canadianpharm.store
http://indianpharm24.com/# indian pharmacies safe indianpharm.store
where to buy amoxicillin: buy amoxicillin 250mg – generic amoxicillin online
where to get clomid: get generic clomid without rx – order cheap clomid without rx
http://prednisonest.pro/# buy prednisone 1 mg mexico
how can i get clomid without rx: can you buy cheap clomid for sale – can i buy clomid prices
prednisone 1mg purchase: prednisone for sale without a prescription – prednisone 5 mg cheapest
where can i get prednisone prednisone price 10mg prednisone daily
Искусство перевода с иностранных языков имеет огромное значение в современном многоязычном мире. Когда речь идет о переводе с иностранных языков, важно учитывать не только лингвистические аспекты, но и культурные и контекстуальные особенности. Профессиональные специалисты в области перевода с иностранных языков играют ключевую роль в обеспечении точности и адекватности передачи информации.
Один из важных аспектов перевода с иностранных языков – это сохранение аутентичности текста и передача его смысла на язык, на котором он будет воспринят. Это требует глубокого понимания языка, а также контекста и культурных нюансов, которые могут влиять на перевод.
Процесс перевода с иностранных языков включает в себя не только знание языков, но и искусство передачи содержания, стиля и нюансов оригинала. Это требует не только технических навыков, но и тонкого чувства языка и контекста.
Выбор профессиональной компании для перевода с иностранных языков – это гарантия качественной и точной работы. Надежные специалисты в области перевода с иностранных языков могут обеспечить точность и адекватность перевода, учитывая все особенности исходного текста.
В мире многоязычия и глобализации значение перевода с иностранных языков трудно переоценить. Это процесс, который облегчает взаимопонимание и содействует культурному обмену. Надежный и опытный переводчик способен сделать вашу информацию доступной для аудитории на любом языке. Не забывайте о важности профессионального перевода с иностранных языков в вашем международном взаимодействии.
#перевод #иностранныязыки #профессионалывобластиперевода #глобализация
http://clomidst.pro/# order clomid price
where buy clomid pills: clomid vs testosterone – can you get clomid no prescription
I have been browsing online more than 2 hours today, yet I never found any
interesting article like yours. It is pretty worth enough for me.
Personally, if all website owners and bloggers made good content as you did, the web will be a lot more useful than ever before.
price for 15 prednisone: prednisone 2 mg – over the counter prednisone medicine
buy prednisone nz: prednisone cream brand name – prednisone 25mg from canada
augmentin heartburn
https://amoxilst.pro/# amoxicillin 200 mg tablet
buy clomid no prescription: clomid manufacturer coupon – cheap clomid for sale
diclofenac sodico 50mg
clomid pill: how can i get generic clomid without insurance – can i get generic clomid without insurance
ezetimibe outcome study
prednisone 5 mg brand name: price for 15 prednisone – prednisone 5 mg tablet cost
http://clomidst.pro/# where buy generic clomid price
order cheap clomid no prescription can i get cheap clomid prices how can i get generic clomid without insurance
blood pressure medicine diltiazem
buy amoxicillin from canada: amoxicillin 250 mg – amoxil generic
can you get generic clomid pills: clomid twins – how to get generic clomid without prescription
Понимание сущности и угроз привязанных с обналом кредитных карт способствует людям предотвращать атак и защищать свои финансовые состояния. Обнал (отмывание) кредитных карт — это механизм использования украденных или нелегально добытых кредитных карт для совершения финансовых транзакций с целью сокрыть их происхождение и пресечь отслеживание.
Вот некоторые способов, которые могут содействовать в избежании обнала кредитных карт:
Охрана личной информации: Будьте осторожными в контексте предоставления персональной информации, особенно онлайн. Избегайте предоставления номеров карт, кодов безопасности и инных конфиденциальных данных на ненадежных сайтах.
Мощные коды доступа: Используйте надежные и уникальные пароли для своих банковских аккаунтов и кредитных карт. Регулярно изменяйте пароли.
Контроль транзакций: Регулярно проверяйте выписки по кредитным картам и банковским счетам. Это позволит своевременно обнаруживать подозрительных транзакций.
Защита от вирусов: Используйте антивирусное программное обеспечение и актуализируйте его регулярно. Это поможет препятствовать вредоносные программы, которые могут быть использованы для кражи данных.
Осмотрительное поведение в социальных медиа: Будьте осторожными в социальных сетях, избегайте опубликования чувствительной информации, которая может быть использована для взлома вашего аккаунта.
Быстрое сообщение банку: Если вы заметили какие-либо подозрительные операции или утерю карты, сразу свяжитесь с вашим банком для заблокировки карты.
Получение знаний: Будьте внимательными к инновационным подходам мошенничества и обучайтесь тому, как противостоять их.
Избегая легковерия и осуществляя предупредительные действия, вы можете снизить риск стать жертвой обнала кредитных карт.
http://clomidst.pro/# how can i get generic clomid without dr prescription
ТолMuch – ваш надежный партнер в переводе документов. Многие сферы жизни требуют предоставления переведенных документов – образование за рубежом, международные бизнес-соглашения, иммиграционные процессы. Наши специалисты помогут вам с профессиональным переводом документов.
Наш опыт и профессионализм позволяют нам обеспечивать высокое качество перевода документов в самые кратчайшие сроки. Мы понимаем, насколько важна точность и грамотность в этом деле. Каждый проект для нас – это возможность внимательно отнестись к вашим документам.
Сделайте шаг к успешному будущему с нами. Наши услуги по переводу документов помогут вам преодолеть языковые барьеры в любой области. Доверьтесь переводу документов профессионалам. Обращайтесь к ТолMuch – вашему лучшему выбору в мире лингвистики и перевода.
перевод документов
#переводдокументов #ТолMuch #язык #бизнес
amoxicillin for sale: roseola vs amoxicillin rash – order amoxicillin uk
amoxicillin 500mg cost: how long does amoxicillin take to work – purchase amoxicillin 500 mg
best office cleaner in manchester UK
prednisone daily use: prednisone cost canada – best pharmacy prednisone
https://amoxilst.pro/# amoxicillin 500 coupon
cost of generic clomid pills: where to buy clomid – where buy cheap clomid no prescription
amoxicillin 500 mg online: can you drink on amoxicillin – buy amoxil
purchase prednisone no prescription can i buy prednisone from canada without a script 1250 mg prednisone
best ed meds online: online ed medicine – cheap ed meds online
online ed pills: erectile dysfunction online prescription – cheap ed medication
https://onlinepharmacy.cheap/# uk pharmacy no prescription
After I originally left a comment I seem to have clicked the -Notify me when new comments are added- checkbox and now whenever a comment is added
I receive four emails with the exact same comment. There has to be a way you can remove me from that service?
Thank you!
canadian pharmacy coupon: pharmacy online – pharmacy coupons
prescription canada: canada mail order prescription – medications online without prescriptions
Kantorbola adalah situs slot gacor terbaik di indonesia , kunjungi situs RTP kantor bola untuk mendapatkan informasi akurat slot dengan rtp diatas 95% . Kunjungi juga link alternatif kami di kantorbola77 dan kantorbola99 .
how to get ed meds online: affordable ed medication – ed medication online
hoki 1881
online pharmacy no prescription canadian online pharmacy cheapest pharmacy for prescription drugs
https://onlinepharmacy.cheap/# canadian pharmacy without prescription
cheap ed: pills for ed online – boner pills online
flomax norvasc
online ed pharmacy: online erectile dysfunction – affordable ed medication
zinmanga
foreign pharmacy no prescription: online mexican pharmacy – drugstore com online pharmacy prescription drugs
flexeril snort
http://onlinepharmacy.cheap/# online pharmacy no prescription
generic name for effexor
pharmacy with no prescription: buy medications online no prescription – mexico prescription drugs online
does insurance cover contrave
pharmacy coupons: discount pharmacy – canada pharmacy coupon
low cost ed pills: affordable ed medication – online ed prescription
http://pharmnoprescription.pro/# non prescription online pharmacy india
online ed prescription: online erectile dysfunction – best online ed pills
where can i get ed pills: online ed medications – ed drugs online
online pharmacy discount code canada pharmacy online online pharmacy prescription
https://pharmnoprescription.pro/# no prescription canadian pharmacy
online doctor prescription canada: canadian prescription – buy meds online no prescription
offshore pharmacy no prescription: Best online pharmacy – overseas pharmacy no prescription
order ed meds online: ed online pharmacy – best online ed meds
best online pharmacy india: world pharmacy india – indian pharmacy online
hoki 1881
Здравствуйте. С радостью информируем о запуске улучшенного приложения букмекерской конторы Олимп! Контора Олимп на андроид доступно сейчас! Приложение теперь еще удобнее и быстрее, обеспечивая доступ к широкому спектру ставок на спорт с мобильных телефонов. С последним обновлением вы получаете расширенные функции управления вашим счетом, переработанный дизайн для еще более интуитивного использования, а также повышенную скорость работы. Присоединяйтесь к довольным пользователям и совершайте свои ставки с удовольствием и комфортом в любом месте и в любое время. Скачайте последнюю версию приложения букмекерской конторы прямо сейчас и играйте вместе с Олимп!
trustworthy canadian pharmacy: onlinecanadianpharmacy 24 – canada drug pharmacy
http://canadianpharm.guru/# canadian drugs
mexican pharmaceuticals online mexican online pharmacies prescription drugs mexico pharmacies prescription drugs
http://mexicanpharm.online/# medicine in mexico pharmacies
Восторгаемся возможностью анонсировать новейшее обновление приложения от БК Олимп для Android! Ваше умение и опыт со ставками на спорт станет невероятно комфортным благодаря обновленному интерфейсу и ускоренной работе программы. БК Олимп на андроид доступно сегодня! С последней версией приложения вы получите неограниченный доступ к разнообразию спортивных событий прямо с вашего мобильного устройства. Ожидайте расширенные возможности для управления счетом, передовой дизайн для интуитивного пользования и значительное улучшение скорости приложения. Присоединитесь счастливых клиентов БК Олимп и радуйтесь ставкам где угодно и когда угодно. Установите последнюю версию приложения без промедления и начните побеждать вместе с Олимп!
ordering drugs from canada: canadian pharmacy oxycodone – canadian drug prices
http://canadianpharm.guru/# canada drugs online
amitriptyline type of drug
С энтузиазмом сообщаем о дебюте переработанного мобильного приложения БК Олимп для Android устройств! Этот релиз значительно улучшает ваше опыт с ставками, делая его более интуитивным и быстрым. Скачать приложение конторы Олимп возможно сегодня! В новой версии приложения пользователи обретут непосредственный доступ к обширному каталогу спортивных соревнований через свой смартфон. Оптимизированное управление аккаунтом, передовой дизайн для легкого навигации и значительное ускорение работы приложения – всё это ждет вас. Присоединяйтесь к рядам удовлетворенных пользователей и испытывайте радость от ставок в любом уголке мира и в любой момент. Получите обновление приложения БК Олимп сегодня и откройте для себя новый уровень игры!
a nurse will instruct a patient taking allopurinol to take each dose
pharmacy canadian superstore: best canadian pharmacy – legit canadian pharmacy
http://canadianpharm.guru/# canadian world pharmacy
buying prescription drugs online canada: buy pills without prescription – online drugstore no prescription
81mg aspirin
aripiprazole sleep
http://pharmacynoprescription.pro/# buy drugs online no prescription
canadian pharmacy without prescription: meds no prescription – online pharmacy without prescriptions
С огромной радостью разделяем новостью о релизе обновленной версии мобильного приложения от БК Олимп для Android! Это обновление преобразит ваш подход к ставкам на спорт, делая процесс более гладким и быстрым. Скачать Olimp на андроид и вы получите легкий доступ к широкому ассортименту спортивных мероприятий, открытых для ставок прямо с вашего мобильного. Расширенные функции управления профилем, интуитивный дизайн для упрощения навигации и значительное повышение скорости приложения обещают непревзойденный опыт. Присоединяйтесь к сообществу энтузиастичных клиентов и делайте ставки с удовольствием где бы вы ни находились, в любое время. Скачайте последнюю версию приложения БК Олимп уже сейчас и погрузитесь в мир игры с комфортом и стилем!
mexican online pharmacies prescription drugs mexican pharmaceuticals online mexico drug stores pharmacies
http://indianpharm.shop/# cheapest online pharmacy india
no prescription canadian pharmacies: buy medication online with prescription – online canadian pharmacy no prescription
best canadian pharmacy: canadian pharmacy uk delivery – buy drugs from canada
Энергично делимся новостью о запуске новаторской версии приложения для ставок от БК Олимп на Android! Это обновление изменит ваш подход к ставкам, делая процесс более удобным и быстрым. Внедрение современных решений позволяет предоставить прямой доступ к широкому ассортименту спортивных мероприятий с вашего мобильного. Скачать Olimp и благодаря последним обновлениям, вы насладитесь упрощенным управлением аккаунтом, понятным дизайном для оптимальной навигации и значительно ускоренной работой приложения. Становитесь частью сообществу поклонников БК Олимп, радуясь возможностью делать ставки в любом месте и когда угодно. Установите актуальную версию приложения сегодня же и переходите к новым высотам в мире ставок!
טלגראס
תְּמוּנָה המִקוּם עבור טלגראס כיוונים (Telegrass), קָרוֹוּעַ גם בשמות “טלגראס” או “טלגראס כיוונים”, היא אתר המספק מידע, לינקים, קישורים, מדריכים והסברים בנושאי קנאביס בתוך הארץ. באמצעות האתר, משתמשים יכולים למצוא את כל הקישורים המעודכנים עבור ערוצים מומלצים ופעילים בטלגראס כיוונים בכל רחבי הארץ.
טלגראס כיוונים הוא אתר ובוט בתוך פלטפורמת טלגראס, מספק דרכי תקשורת ושירותים מגוונים בתחום רכישת קנאביס וקשורים. באמצעות הבוט, המשתמשים יכולים לבצע מגוון פעולות בקשר לרכישת קנאביס ולשירותים נוספים, תוך כדי תקשורת עם מערכת אוטומטית המבצעת את הפעולות בצורה חכמה ומהירה.
בוט הטלגראס (Telegrass Bot) מציע מגוון פעולות שימושיות למשתמש: הזמנת קנאביס: בצע קנייה דרך הבוט על ידי בחירת סוגי הקנאביס, כמות וכתובת למשלוח.
תובנות ותמיכה: קבל מידע על המוצרים והשירותים, תמיכה טכנית ותשובות לשאלות שונות.
מבחן מלאי: בדוק את המלאי הזמין של קנאביס ובצע הזמנה תוך כדי הקשת הבדיקה.
הכנסת ביקורות: הוסף ביקורות ודירוגים למוצרים שרכשת, כדי לעזור למשתמשים אחרים.
הוספת מוצרים חדשים: הוסף מוצרים חדשים לפלטפורמה והצג אותם למשתמשים.
בקיצור, בוט הטלגראס הוא כלי חשוב ונוח שמקל על השימוש והתקשורת בנושאי קנאביס, מאפשר מגוון פעולות שונות ומספק מידע ותמיכה למשתמשים.
mexico pharmacy: mexican border pharmacies shipping to usa – medication from mexico pharmacy
https://pharmacynoprescription.pro/# canadian pharmacy non prescription
canada pharmacy 24h: canadapharmacyonline com – ed drugs online from canada
indian pharmacies safe: reputable indian online pharmacy – india pharmacy
mexico prescription drugs online: canadian pharmacy online no prescription – mail order prescriptions from canada
https://indianpharm.shop/# top online pharmacy india
https://mexicanpharm.online/# medicine in mexico pharmacies
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
canadian drugs pharmacy canadian online pharmacy reviews canada pharmacy 24h
Best Wedding Venues in Chattarpur and MG Road. List of Farmhouses in Chattarpur, Banquet Halls, Hotels for Party places in Chattarpur and MG Road Ever thought of enjoying a multi-theme Wedding Function while being at just one destination? If no then you must not have visited Chattarpur & MG Road Farmhouses.
prescription drugs online canada: online pharmacy no prescription needed – buy medication online no prescription
canadian medications: is canadian pharmacy legit – canadian pharmacies
http://pharmacynoprescription.pro/# how to order prescription drugs from canada
buy drugs online without a prescription: buy pain meds online without prescription – best no prescription online pharmacy
best online pharmacy india: п»їlegitimate online pharmacies india – indian pharmacy
purple pharmacy mexico price list: mexico drug stores pharmacies – purple pharmacy mexico price list
https://indianpharm.shop/# buy medicines online in india
no prescription online pharmacies: buy drugs online without a prescription – order medication without prescription
https://pharmacynoprescription.pro/# online medicine without prescription
https://pharmacynoprescription.pro/# online pharmacy not requiring prescription
vipps canadian pharmacy canadian pharmacy victoza canada discount pharmacy
mexican online pharmacies prescription drugs: medication from mexico pharmacy – buying prescription drugs in mexico
Pingback: grandpashabet
legitimate online pharmacies india: Online medicine order – top 10 online pharmacy in india
Very soon this web site will be famous amid all blog people, due to it’s good articles
canadian pharmacy reviews: canada pharmacy online legit – canadian pharmacy world
Jokers4d and joker4d is a site that provides online games
of the best quality so that it prioritizes the comfort of
every player who joins to become a subscription to the Dewi Merah JP 4D online gaming
site with a jackpot value of up to hundreds of millions of rupiah every day
https://mexicanpharm.online/# best online pharmacies in mexico
Right here is the right web site for anyone who would like to understand this topic.
You know a whole lot its almost hard to argue with you (not
that I personally will need to…HaHa). You certainly put a new spin on a subject that’s been discussed for decades.
Wonderful stuff, just excellent!
no prescription drugs online: medications online without prescriptions – canadian prescription prices
legitimate canadian online pharmacies: buying drugs from canada – canada drugs reviews
https://indianpharm.shop/# pharmacy website india
indian pharmacy paypal: top 10 pharmacies in india – india pharmacy
Your article helped me a lot, is there any more related content? Thanks!
https://pharmacynoprescription.pro/# online drugs no prescription
canadian pharmacy no scripts: canadian pharmacy antibiotics – canadian pharmacies that deliver to the us
В ассортименте нашего интернет-магазина сантехники представлена только оригинальная продукция таких известных брендов как Джилекс, PRO AQUA, Valfex, LD, СТМ и многих других
pharmacies in mexico that ship to usa mexico drug stores pharmacies mexican drugstore online
buying prescription drugs in mexico: buying from online mexican pharmacy – purple pharmacy mexico price list
http://indianpharm.shop/# online pharmacy india
medicine in mexico pharmacies: mexico drug stores pharmacies – mexican rx online
india pharmacy mail order: indianpharmacy com – indian pharmacy paypal
online pharmacy no prescriptions: canadian pharmacy no prescription – buy medications without a prescription
https://pharmacynoprescription.pro/# mexico prescription drugs online
bupropion withdrawal symptoms
celebrex and kidney function
cheapest online pharmacy india: cheapest online pharmacy india – best india pharmacy
can you drink alcohol on augmentin
http://canadianpharm.guru/# canada pharmacy reviews
canada prescription: medication online without prescription – canada prescription online
baclofen drug test
https://pharmacynoprescription.pro/# online pharmacy without a prescription
indian pharmacy paypal: legitimate online pharmacies india – india pharmacy mail order
no prescription needed online pharmacy ordering prescription drugs from canada canada pharmacy no prescription
top 10 pharmacies in india: mail order pharmacy india – world pharmacy india
Существование даркнет-маркетов – это явление, что привлекает значительный интерес или споры в сегодняшнем окружении. Подпольная часть веба, или подпольная область всемирной сети, отображает приватную инфраструктуру, доступную исключительно с помощью специальные софт или настройки, снабжающие неузнаваемость пользовательских аккаунтов. По данной закрытой сети расположены теневые электронные базары – интернет-ресурсы, где-нибудь продаются разные продукты а сервисы, наиболее часто нелегального типа.
По теневых электронных базарах можно отыскать самые разные вещи: психоактивные препараты, военные средства, похищенная информация, взломанные учетные записи, подделки и многое другое. Такие базары порой магнетизирузивают внимание также уголовников, а также обычных пользовательских аккаунтов, хотящих обходить юриспруденция или же доступить к товары или услуговым предложениям, которые на обыденном всемирной сети были бы не доступны.
Тем не менее стоит помнить, как работа в даркнет-маркетах представляет собой противозаконный характер а способна создать крупные юридические последствия по закону. Органы правопорядка усердно сражаются против такими площадками, но все же в результате инкогнито даркнета это не перманентно легко.
Поэтому, существование скрытых интернет-площадок является сущностью, но все же эти площадки пребывают территорией серьезных угроз как и для пользователей, так и для таких сообщества во в целом и целом.
http://canadianpharm.guru/# canadian family pharmacy
тор маркет
Тор программа – это уникальный веб-браузер, который задуман для обеспечения тайности и устойчивости в сети. Он построен на сети Тор (The Onion Router), позволяющая пользователям пересылать данными через размещенную сеть узлов, что превращает сложным прослушивание их действий и определение их локации.
Основная характеристика Тор браузера заключается в его способности направлять интернет-трафик путем несколько точек сети Тор, каждый из них шифрует информацию перед следующему узлу. Это создает многочисленное количество слоев (поэтому и наименование “луковая маршрутизация” – “The Onion Router”), что создает почти что недостижимым прослушивание и определение пользователей.
Тор браузер регулярно используется для преодоления цензуры в государствах, где запрещен доступ к определенным веб-сайтам и сервисам. Он также позволяет пользователям гарантировать приватность своих онлайн-действий, таких как просмотр веб-сайтов, общение в чатах и отправка электронной почты, предотвращая отслеживания и мониторинга со стороны интернет-провайдеров, государственных агентств и киберпреступников.
Однако стоит запоминать, что Тор браузер не обеспечивает полной анонимности и безопасности, и его выпользование может быть ассоциировано с риском доступа к незаконным контенту или деятельности. Также вероятно замедление скорости интернет-соединения из-за
тор даркнет
Тор теневая часть интернета – это компонент интернета, которая, которая функционирует над стандартнои? сети, однако неприступна для прямого входа через обычные браузеры, такие как Google Chrome или Mozilla Firefox. Для доступа к даннои? сети нуждается специальное программное обеспечение, как, Tor Browser, которыи? обеспечивает скрытность и сафети пользователеи?.
Основнои? принцип работы Тор даркнета основан на использовании маршрутов через разные ноды, которые кодируют и перенаправляют трафик, делая сложным трекинг его источника. Это формирует секретность для пользователеи?, пряча их фактические IP-адреса и местоположение.
Тор даркнет содержит различные источники, включая веб-саи?ты, форумы, рынки, блоги и другие онлаи?н-ресурсы. Некоторые из подобных ресурсов могут быть не доступны или запрещены в обыкновеннои? сети, что делает Тор даркнет площадкои? для трейдинга информациеи? и услугами, включая продукты и услуги, которые могут быть незаконными.
Хотя Тор даркнет применяется несколькими людьми для преодоления цензуры или защиты частнои? жизни, он так же становится платформои? для разнообразных противозаконных активностеи?, таких как курс наркотиками, оружием, кража личных данных, поставка услуг хакеров и остальные уголовные поступки.
Важно осознавать, что использование Тор даркнета не всегда законно и может иметь в себя серьезные угрозы для защиты и законности.
best online pharmacy no prescription: buy drugs without prescription – canadian prescription
canadian pharmacy tampa: canadian pharmacy online – canada drugstore pharmacy rx
hoki1881
Ищете где копия наушников Airpods PRO? Качественные беспроводные наушники в Москве и области. Реплика оригинальных AirPods с шумоподавлением по скидке. Самые надежные гарнитуры по низким ценам. Быстро доставим по России.
В поисках где купить реплику наушников Airpods PRO в Москве? Топовые беспроводные наушники в Москве. Копия оригинальных AirPods с шумоподавлением по цене 2490 рублей. Надежные гаджеты по низким ценам. Быстрая доставка по России.
В поисках где https://el-gusto.ru/? Наилучшие беспроводные наушники в Москве и РФ. Реплика оригинальных AirPods с активным шумоподавлением всего за 2490 рублей. Надежные гарнитуры по приемлимым ценам. Доставка по России.
В поисках где копия наушников Airpods PRO? Топовые беспроводные наушники в Москве и области. Реплика оригинальных AirPods с шумоподавлением со скидкой. Проверенные гаджеты по приемлимым ценам. Быстрая доставка по России.
http://gatesofolympus.auction/# gates of olympus oyna demo
pin up: pin-up casino – pin up casino giris
Не ведитесь на эти высеры от казино зевс там только время убьете.
https://aviatoroyna.bid/# aviator giris
Хватит уже пиарить казино зевс там крутят одни подставные казино. https://globalmsk.ru/firmnews/id/33207/1
Вечно виснет и не грузится этот обзорник зевс техническое отставание. https://actualtraffic.ru/post/post-744002/
Достало это кидалово с казино зевс сборник проплаченных отзывов. http://m.fgis.economy.minregion.ru/publication/5296-aleksey-ivanov-rasskazal-o-populyarnyh-bonusah-v-onlayn-kazino-belarusi.html
https://aviatoroyna.bid/# aviator hilesi ücretsiz
sweet bonanza yorumlar: sweet bonanza yorumlar – sweet bonanza giris
Ищете где реплика наушников Airpods PRO? Качественные беспроводные наушники в Москве и РФ. Копия оригинальных AirPods с активным шумоподавлением всего за 2490 рублей. Только качественные гаджеты по доступным ценам. Быстро доставим по России.
Искали где копия Airpods PRO? Качественные беспроводные наушники в Москве. Реплика оригинальных AirPods с шумоподавлением всего за 2490 рублей. Только качественные гаджеты по доступным ценам. Быстро доставим по России.
Искали где купить реплику Airpods PRO в Москве? Качественные беспроводные наушники в Москве и РФ. Реплика оригинальных AirPods с шумоподавлением по скидке. Проверенные гаджеты по приемлимым ценам. Быстрая доставка по России.
Искали где купить реплику наушников Airpods PRO в Москве? Наилучшие беспроводные наушники в Москве и области. Копия оригинальных AirPods с шумоподавлением со скидкой. Самые качественные гарнитуры по низким ценам. Доставим по России.
aviator oyunu 100 tl: aviator sinyal hilesi apk – aviator oyunu 10 tl
Искали где купить копию Аирподс ПРО? Наилучшие беспроводные наушники в Москве и РФ. Реплика оригинальных AirPods с шумоподавлением всего за 2490 рублей. Надежные гарнитуры по доступным ценам. Быстро доставим по России.
https://slotsiteleri.guru/# slot oyunlari siteleri
Ищете где копия наушников Airpods PRO? Топовые беспроводные наушники в Москве. Реплика оригинальных AirPods с активным шумоподавлением всего за 2490 рублей. Только качественные гаджеты по доступным ценам. Быстрая доставка по России.
В поисках где купить лучшую реплику Airpods PRO? Лучшие беспроводные наушники в Москве и РФ. Копия оригинальных AirPods с шумоподавлением всего за 2490 рублей. Проверенные гаджеты по доступным ценам. Быстрая доставка по России.
hoki1881
В поисках где купить копию Airpods PRO в Москве? Топовые беспроводные наушники в Москве и РФ. Копия оригинальных AirPods с активным шумоподавлением со скидкой. Самые качественные гаджеты по низким ценам. Быстро доставим по России.
http://aviatoroyna.bid/# aviator oyunu 20 tl
gates of olympus oyna demo: gates of olympus demo free spin – gates of olympus guncel
https://sweetbonanza.bid/# pragmatic play sweet bonanza
https://sweetbonanza.bid/# sweet bonanza demo oyna
gates of olympus oyna ucretsiz: pragmatic play gates of olympus – gates of olympus demo
Даркнет заказать
Присутствие скрытых интернет-площадок – это процесс, который вызывает значительный интерес а споры в настоящем мире. Темная часть интернета, или глубокая зона интернета, отображает тайную платформу, доступных только при помощи особые программы и конфигурации, снабжающие неузнаваемость участников. В данной данной закрытой конструкции расположены даркнет-маркеты – интернет-ресурсы, где бы торговля разносторонние продукты или услуги, в большинстве случаев противозаконного степени.
По теневых электронных базарах легко обнаружить самые разнообразные продукты: наркотические препараты, стрелковое оружие, данные, похищенные из систем, взломанные аккаунты, подделки и и многое. Такие площадки часто привлекают восторг также правонарушителей, и обыкновенных субъектов, желающих обходить стороной право или получить доступ к вещам или услугам, те на обычном вебе были бы не доступны.
Однако следует помнить, каким образом деятельность на даркнет-маркетах представляет собой нелегальный тип а может привести к крупные юридические нормы санкции. Органы правопорядка активно сопротивляются против подобными маркетами, но в результате неузнаваемости скрытой сети это далеко не перманентно без проблем.
Поэтому, существование скрытых интернет-площадок есть фактом, однако такие рынки пребывают сферой важных опасностей как для таких, так и для участников, а также для таких, как сообщества во в общем.
pin up casino: aviator pin up – pin-up online
https://pinupgiris.fun/# pin up giris
даркнет площадки
Темные площадки, а также темные рынки, представлены сетевые платформы, доступные лишь при помощи темная сеть – часть интернета, скрытая от обычных систем поиска. Эти платформы допускают клиентам торговать различными товарными единицами и сервисами, наиболее часто противозаконного степени, такими как наркотические препараты, стрелковое оружие, ворованные данные, поддельные документы или иные запрещенные либо незаконные продукты или услуги.
Темные площадки предоставляют инкогнито их собственных пользовательских аккаунтов в результате использования специальных программного обеспечения и настроек, таких как Tor, которые маскируют IP-адреса и распределяют интернет-трафик через разнообразные узловые соединения, делая непростым отследить их действий правоохранительными органами.
Такие торговые площадки время от времени попадают объектом внимания органов правопорядка, какие сопротивляются с ими в границах борьбы против компьютерной преступностью и противозаконной торговлей.
Одни проблемы. Программа бк леон не устанавливается и с чем связана данная проблема я не знаю. Но лучше поискать другой источник для скачивания данной программы. Тут тратить свое время не советую.
Одни проблемы. Букмекерская контора леон не работает и с чем связана данная проблема я не знаю. Но лучше поискать другой источник для скачивания данной программы. Тут тратить свое время не советую.
Одни проблемы. Букмекерская контора леон не работает и с чем связана данная проблема я не знаю. Но лучше поискать другой источник для скачивания данной программы. Тут тратить свое время не советую.
даркнет россия
России, как и в других территориях, даркнет показывает собой отрезок интернета, неприступную для регулярного поискавания и осмотра через регулярные навигаторы. В отличие от публичной поверхностной инфраструктуры, даркнет считается тайным куском интернета, доступ к какому часто осуществляется через эксклюзивные программы, подобные как Tor Browser, и анонимные инфраструктуры, подобные как Tor.
В теневой сети собраны различные ресурсы, включая конференции, торговые площадки, логи и прочие интернет-ресурсы, которые могут недоступимы или запрещены в стандартной коммуникации. Здесь допускается найти различные продукты и сервисы, включая незаконные, например наркотические вещества, вооружение, компрометированные сведения, а также услуги хакеров и прочие.
В России теневая сеть также применяется для пересечения цензуры и мониторинга со партии. Некоторые клиенты могут применять его для обмена информацией в условиях, когда свобода слова заблокирована или информационные источники подвергнуты цензуре. Однако, также стоит отметить, что в теневой сети есть много не Законной процесса и потенциально опасных условий, включая мошенничество и киберпреступления
Одни проблемы. Почему не работает бк леон сегодня и с чем связана данная проблема я не знаю. Но лучше поискать другой источник для скачивания данной программы. Тут тратить свое время не советую.
Одни проблемы. Приложение бк леон вылетает и с чем связана данная проблема я не знаю. Но лучше поискать другой источник для скачивания данной программы. Тут тратить свое время не советую.
Одни проблемы. БК леон не могу войти и с чем связана данная проблема я не знаю. Но лучше поискать другой источник для скачивания данной программы. Тут тратить свое время не советую.
slot casino siteleri: yeni slot siteleri – deneme bonusu veren siteler
Жаждешь моды и самореализации? Присоединяйся к мастер-классу по шитью свитшотов! Освой искусство создания стильных вещей и открой для себя новые возможности за 2 часа!
Регистрация здесь https://u.to/zQWJIA
Одни проблемы. Леон не работает приложение и с чем связана данная проблема я не знаю. Но лучше поискать другой источник для скачивания данной программы. Тут тратить свое время не советую.
Одни проблемы. Леон не работает приложение и с чем связана данная проблема я не знаю. Но лучше поискать другой источник для скачивания данной программы. Тут тратить свое время не советую.
В поисках где купить реплику Airpods PRO в Москве? Топовые беспроводные наушники в Москве и РФ. Копия оригинальных AirPods с активным шумоподавлением по скидке. Самые надежные гарнитуры по низким ценам. Быстрая доставка по России.
Ищете где реплика Airpods PRO? Качественные беспроводные наушники в Москве и РФ. Реплика оригинальных AirPods с активным шумоподавлением по цене 2490 рублей. Проверенные гаджеты по доступным ценам. Доставим по России.
https://pinupgiris.fun/# pin-up giris
Искали где реплика наушников Airpods PRO? Лучшие беспроводные наушники в Москве и области. Реплика оригинальных AirPods с активным шумоподавлением со скидкой. Только проверенные гаджеты по приемлимым ценам. Доставим по России.
Ищете где купить копию наушников Airpods PRO? Качественные беспроводные наушники в Москве. Реплика оригинальных AirPods с активным шумоподавлением всего за 2490 рублей. Самые надежные гаджеты по низким ценам. Доставим по России.
http://slotsiteleri.guru/# slot siteleri güvenilir
Искали где копия Airpods PRO? Наилучшие беспроводные наушники в Москве и области. Реплика оригинальных AirPods с шумоподавлением по цене 2490 рублей. Самые надежные гарнитуры по низким ценам. Быстро доставим по России.
iv buspirone
В поисках где купить реплику Аирподс ПРО? Наилучшие беспроводные наушники в Москве и РФ. Копия оригинальных AirPods с шумоподавлением по цене 2490 рублей. Проверенные гарнитуры по низким ценам. Быстрая доставка по России.
Покупки в Даркнете: Заблуждения и Факты
Скрытая часть веба, загадочная секция сети, привлекает интерес участников своей тайностью и возможностью приобрести различные продукты и предметы без лишних вопросов. Однако, путешествие в тот мрак темных торгов связано с набором опасностей и сложностей, о чем желательно понимать перед совершением транзакций.
Что значит темный интернет и как оно действует?
Для того, кому незнакомо с этим понятием, темный интернет – это часть веба, невидимая от обычных поисковых систем. В скрытой части веба имеются специальные онлайн-рынки, где можно найти практически все виды : от наркотиков и оружия и перехваченных учётных записей и поддельных документов.
Иллюзии о приобретении товаров в скрытой части веба
Скрытность обеспечена: При всём том, использование анонимных технологий, таких как Tor, способствует скрыть свою действия в сети, тайность в скрытой части веба не является. Существует опасность, что вашу личные данные могут обнаружить обманщики или даже сотрудники правоохранительных органов.
Все товары – качественные товары: В подпольной сети можно найти множество продавцов, продающих продукцию и услуги. Однако, невозможно гарантировать качество или подлинность товаров, поскольку нет возможности провести проверку до совершения покупки.
Легальные сделки без ответственности: Многие участники неправильно думают, что заказывая товары в темном интернете, они подвергают себя риску меньшим риском, чем в реальном мире. Однако, заказывая запрещенные вещи или сервисы, вы рискуете наказания.
Реальность приобретений в подпольной сети
Опасности мошенничества и афер: В подпольной сети множество мошенников, которые готовы обмануть пользователей, которые недостаточно бдительны. Они могут предложить поддельную продукцию или просто исчезнуть, оставив вас без денег.
Опасность легальных органов: Пользователи темного интернета рискуют попасть к ответственности перед законом за приобретение и заказ незаконных товаров и услуг.
Непредсказуемость результатов: Не каждая сделка в скрытой части веба заканчиваются удачно. Качество товаров может оказаться низким, а
процесс заказа может послужить источником неприятностей.
Советы для безопасных сделок в скрытой части веба
Проводите тщательное исследование продавца и товара перед приобретением.
Используйте безопасные программы и сервисы для защиты вашей анонимности и безопасности.
Платите только безопасными методами, например, криптовалютами, и избегайте предоставления персональных данных.
Будьте бдительны и очень внимательны во всех совершаемых действиях и выбранных вариантах.
Заключение
Сделки в скрытой части веба могут быть как интересным, так и опасным путешествием. Понимание рисков и принятие соответствующих мер предосторожности помогут уменьшить риск негативных последствий и обеспечить безопасность при покупках в этом неизведанном мире интернета.
Искали где купить лучшую реплику Airpods PRO? Топовые беспроводные наушники в Москве и РФ. Копия оригинальных AirPods с активным шумоподавлением со скидкой. Самые надежные гаджеты по приемлимым ценам. Доставим по России.
Покупки в скрытой части веба: Мифы и Факты
Скрытая часть веба, таинственная область интернета, заинтересовывает интерес пользователей своим анонимностью и возможностью приобрести различные товары и предметы без лишних вопросов. Однако, путешествие в этот вселенная скрытых рынков сопряжено с набором опасностей и сложностей, о чём необходимо понимать перед осуществлением покупок.
Что такое темный интернет и как оно действует?
Для того, кому не знакомо с термином, темный интернет – это сектор интернета, невидимая от стандартных поисков. В скрытой части веба имеются специальные онлайн-рынки, где можно найти возможность почти все, что угодно : от запрещённых веществ и боеприпасов до взломанных аккаунтов и фальшивых документов.
Иллюзии о приобретении товаров в скрытой части веба
Тайность защищена: Хотя, применение технологий анонимности, таких как Tor, способно помочь скрыть свою активность в сети, анонимность в подпольной сети не является абсолютной. Существует возможность, что может вашу информацию о вас могут выявить обманщики или даже сотрудники правоохранительных органов.
Все товары – качественные: В Даркнете можно обнаружить много продавцов, предоставляющих продукты и сервисы. Однако, нельзя обеспечить качество или подлинность товаров, так как невозможно проверить до того, как вы сделаете заказ.
Легальные транзакции без последствий: Многие пользователи ошибочно считают, что заказывая товары в Даркнете, они подвергают себя низкому риску, чем в обычной жизни. Однако, приобретая противоправные продукцию или сервисы, вы рискуете уголовной ответственности.
Реальность покупок в подпольной сети
Негативные стороны обмана и мошенничества: В подпольной сети много мошенников, которые готовы обмануть пользователей, которые недостаточно бдительны. Они могут предложить поддельную продукцию или просто исчезнуть, оставив вас без денег.
Опасность правоохранительных органов: Пользователи темного интернета рискуют к ответственности перед законом за приобретение и заказ незаконной продукции и сервисов.
Непредвиденность исходов: Не каждая сделка в скрытой части веба завершаются благополучно. Качество продукции может оставлять желать лучшего, а
процесс заказа может привести к неприятным последствиям.
Советы для безопасных сделок в подпольной сети
Проведите полное изучение поставщика и продукции перед совершением покупки.
Используйте безопасные программы и сервисы для защиты вашей анонимности и безопасности.
Используйте только безопасные способы оплаты, такими как криптовалюты, и не раскрывайте личные данные.
Будьте предельно внимательны и осторожны во всех совершаемых действиях и выбранных вариантах.
Заключение
Покупки в Даркнете могут быть как захватывающим, так и опасным путешествием. Понимание рисков и принятие соответствующих мер предосторожности помогут минимизировать вероятность негативных последствий и обеспечить безопасность при совершении покупок в этом неизведанном мире интернета.
Искали где купить реплику наушников Airpods PRO? Топовые беспроводные наушники в Москве и РФ. Копия оригинальных AirPods с активным шумоподавлением всего за 2490 рублей. Проверенные гаджеты по приемлимым ценам. Быстрая доставка по России.
pin-up casino giris: pin up casino – pin-up casino giris
Искали где купить реплику Airpods PRO? Наилучшие беспроводные наушники в Москве. Копия оригинальных AirPods с шумоподавлением по скидке. Только качественные гарнитуры по доступным ценам. Быстрая доставка по России.
Искали где https://el-gusto.ru/? Наилучшие беспроводные наушники в Москве и РФ. Реплика оригинальных AirPods с активным шумоподавлением по скидке. Самые надежные гаджеты по приемлимым ценам. Доставим по России.
http://aviatoroyna.bid/# aviator sinyal hilesi
Искали где купить реплику наушников Airpods PRO? Качественные беспроводные наушники в Москве и РФ. Реплика оригинальных AirPods с активным шумоподавлением всего за 2490 рублей. Только качественные гарнитуры по приемлимым ценам. Быстро доставим по России.
celecoxib is contraindicated in
В поисках где https://el-gusto.ru/? Лучшие беспроводные наушники в Москве и РФ. Реплика оригинальных AirPods с шумоподавлением со скидкой. Надежные гаджеты по приемлимым ценам. Быстро доставим по России.
Электронная регистрация в Росреестре – Сделки онлайн – Центр “Недвижимость и право”
Электронная регистрация в Росреестре сделок с недвижимостью. Ускоренные сроки – 3-7 дней. Выписки из ЕГРН.
Ищете где копия Airpods PRO? Качественные беспроводные наушники в Москве и области. Копия оригинальных AirPods с шумоподавлением со скидкой. Самые качественные гаджеты по приемлимым ценам. Быстрая доставка по России.
Искали где купить копию Airpods PRO в Москве? Качественные беспроводные наушники в Москве и области. Копия оригинальных AirPods с активным шумоподавлением всего за 2490 рублей. Самые качественные гаджеты по низким ценам. Доставим по России.
Лучшие Квартиры посуточно в Симферополе
ashwagandha and pregnancy
celexa high
В поисках где купить реплику Airpods PRO в Москве? Лучшие беспроводные наушники в Москве и РФ. Копия оригинальных AirPods с активным шумоподавлением всего за 2490 рублей. Только проверенные гаджеты по приемлимым ценам. Быстро доставим по России.
Ищете где mdou41orel.ru? Лучшие беспроводные наушники в Москве и области. Реплика оригинальных AirPods с активным шумоподавлением по скидке. Надежные гаджеты по приемлимым ценам. Быстро доставим по России.
https://slotsiteleri.guru/# slot siteleri bonus veren
pin-up casino: pin-up bonanza – pin up casino
gates of olympus 1000 demo: gates of olympus hilesi – gates of olympus guncel
קזינו אונליין
המימורים ברשת – הימורי ספורטאים, קזינו מקוון, משחקי קלפים.
הימורים באינטרנט הופכים ל לקטגוריה מבוקש במיוחדים בעידן המחשב.
מיליוני משתתפים ממנסים את מזלם באפשרויות מימורים השונות.
הפעולה הזהה משנה את את הרגע הניסיון וההתרגשות השחקנים.
גם מעסיק בשאלות אתיות וחברתיות השמורות מאחורי המימורים ברשת.
בתקופת המחשב, המימונים ברשת הם חלק מתרבות הספורט, הפנאי והבידור והחברה ה העכשווית.
המימונים בפלטפורמת האינטרנט כוללים אפשרויות רחב של פעילויות, כולל מימונים על תוצאות ספורטיות, פוליטי, ו- תוצאות מזג האוויר.
ההימורים הם הם מתבצעים באמצע
http://sweetbonanza.bid/# slot oyunlari
Одни проблемы. Букмекерская контора леон не работает и с чем связана данная проблема я не знаю. Но лучше поискать другой источник для скачивания данной программы. Тут тратить свое время не советую.
даркнет запрещён
Подпольная часть сети: запретная территория интернета
Теневой уровень интернета, тайная зона интернета продолжает привлекать внимание и граждан, так и правоохранительных органов. Данный засекреченный уровень интернета известен своей анонимностью и возможностью совершения незаконных операций под прикрытием теней.
Сущность подпольной части сети состоит в том, что он недоступен для обычных браузеров. Для доступа к нему требуются специализированные программные средства и инструменты, которые обеспечивают анонимность пользователей. Это создает идеальную среду для различных незаконных действий, среди которых торговлю наркотическими веществами, торговлю огнестрельным оружием, хищение персональной информации и другие незаконные манипуляции.
В виде реакции на растущую угрозу, многие страны приняли законодательные инициативы, задача которых состоит в запрещение доступа к темному интернету и преследование лиц занимающихся незаконными деяниями в этой нелегальной области. Впрочем, несмотря на предпринятые шаги, борьба с теневым уровнем интернета представляет собой трудную задачу.
Важно подчеркнуть, что полное запрещение теневого уровня интернета практически невыполнима. Даже при принятии строгих контрмер, доступ к этому уровню интернета все еще осуществим с использованием разнообразных технических средств и инструментов, применяемые для обхода ограничений.
Помимо законодательных мер, действуют также проекты сотрудничества между правоохранительными органами и технологическими компаниями с целью пресечения противозаконных действий в теневом уровне интернета. Однако, для эффективного противодействия необходимы не только технологические решения, но также улучшения методов выявления и предотвращения противозаконных манипуляций в данной среде.
В заключение, несмотря на запреты и усилия в борьбе с незаконными деяниями, темный интернет остается серьезной проблемой, нуждающейся в комплексных подходах и коллективных усилиях со стороны правоохранительных структур, так и технологических компаний.
Одни проблемы. Программа бк леон не устанавливается и с чем связана данная проблема я не знаю. Но лучше поискать другой источник для скачивания данной программы. Тут тратить свое время не советую.
Одни проблемы. Букмекерская контора леон не работает и с чем связана данная проблема я не знаю. Но лучше поискать другой источник для скачивания данной программы. Тут тратить свое время не советую.
http://sweetbonanza.bid/# sweet bonanza demo turkce
pin up: aviator pin up – pin-up online
Одни проблемы. Не работает приложение бк леон и с чем связана данная проблема я не знаю. Но лучше поискать другой источник для скачивания данной программы. Тут тратить свое время не советую.
Одни проблемы. Леон не работает приложение и с чем связана данная проблема я не знаю. Но лучше поискать другой источник для скачивания данной программы. Тут тратить свое время не советую.
http://aviatoroyna.bid/# uçak oyunu bahis aviator
Одни проблемы. Леон не работает приложение и с чем связана данная проблема я не знаю. Но лучше поискать другой источник для скачивания данной программы. Тут тратить свое время не советую.
Одни проблемы. БК леон не могу войти и с чем связана данная проблема я не знаю. Но лучше поискать другой источник для скачивания данной программы. Тут тратить свое время не советую.
Одни проблемы. Почему не работает приложение леон и с чем связана данная проблема я не знаю. Но лучше поискать другой источник для скачивания данной программы. Тут тратить свое время не советую.
Одни проблемы. Приложение бк леон вылетает и с чем связана данная проблема я не знаю. Но лучше поискать другой источник для скачивания данной программы. Тут тратить свое время не советую.
sweet bonanza kazanc: sweet bonanza slot demo – pragmatic play sweet bonanza
https://gatesofolympus.auction/# pragmatic play gates of olympus
aviator oyunu 100 tl: aviator oyunu 10 tl – aviator mostbet
I love it when individuals get together and share thoughts.
Great blog, continue the good work!
http://aviatoroyna.bid/# aviator nasil oynanir
https://www.avito.ru/novokuznetsk/predlozheniya_uslug/podem_domov._perenos_domov._zamena_ventsov_2135286827
sweet bonanza slot: sweet bonanza hilesi – sweet bonanza bahis
elementor
elementor
http://pinupgiris.fun/# pin up casino giris
hi!,I really like your writing so so much!
percentage we communicate extra about your post
on AOL? I need a specialist on this area to unravel my problem.
Maybe that’s you! Looking ahead to peer you.
gates of olympus demo free spin: gates of olympus demo free spin – gates of olympus demo
http://sweetbonanza.bid/# sweet bonanza
best online pharmacies in mexico cheapest mexico drugs pharmacies in mexico that ship to usa
Bathroom renovation Dubai
medication from mexico pharmacy Mexican Pharmacy Online reputable mexican pharmacies online
http://canadianpharmacy24.store/# canada pharmacy world
indianpharmacy com: Cheapest online pharmacy – indian pharmacy paypal
india online pharmacy indian pharmacy delivery world pharmacy india
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
canadian drugs: canadian pharmacy 24h com – canadian world pharmacy
https://indianpharmacy.icu/# top 10 online pharmacy in india
legitimate online pharmacies india: Healthcare and medicines from India – top 10 online pharmacy in india
online shopping pharmacy india Cheapest online pharmacy india online pharmacy
canadian pharmacy checker: Licensed Canadian Pharmacy – canadian pharmacy ratings
the canadian pharmacy: Certified Canadian Pharmacy – canadapharmacyonline
https://www.avito.ru/kemerovskaya_oblast_mezhdurechensk/predlozheniya_uslug/podem_domov._perenos_domov._zamena_ventsov_3831125828
india pharmacy mail order: Healthcare and medicines from India – cheapest online pharmacy india
mexican online pharmacies prescription drugs: Online Pharmacies in Mexico – best mexican online pharmacies
legit canadian online pharmacy pills now even cheaper trusted canadian pharmacy
buying drugs from canada: pills now even cheaper – vipps canadian pharmacy
prescription drugs canada buy online: Large Selection of Medications – canadian pharmacy uk delivery
canada discount pharmacy pharmacy canadian canadian family pharmacy
https://canadianpharmacy24.store/# best rated canadian pharmacy
mexican online pharmacies prescription drugs: cheapest mexico drugs – medicine in mexico pharmacies
canadian pharmacy 365: canadian pharmacy india – legitimate canadian online pharmacies
indian pharmacy online: indian pharmacy delivery – Online medicine home delivery
canadian pharmacy: pills now even cheaper – canadian online drugs
Great material. With thanks!
top rated canadian pharmacies online viagra online canadian pharmacy discount prescription drug
buying prescription drugs in mexico Mexican Pharmacy Online mexican pharmaceuticals online
сеть даркнет
Подпольная часть сети: запрещённое пространство виртуальной сети
Темный интернет, скрытый сегмент сети продолжает привлекать интерес и общественности, и также служб безопасности. Этот скрытый уровень сети примечателен своей анонимностью и возможностью осуществления преступных деяний под маской анонимности.
Суть подпольной части сети заключается в том, что данный уровень не доступен обычным популярных браузеров. Для доступа к нему требуются специальные инструменты и программы, предоставляющие анонимность пользователям. Это формирует прекрасные условия для различных незаконных действий, среди которых сбыт наркотиков, оружием, хищение персональной информации и другие незаконные манипуляции.
В виде реакции на растущую угрозу, ряд стран приняли законодательные инициативы, целью которых является ограничение доступа к теневому уровню интернета и привлечение к ответственности тех, кто совершающих противозаконные действия в этой скрытой среде. Тем не менее, несмотря на принятые меры, борьба с подпольной частью сети представляет собой сложную задачу.
Важно подчеркнуть, что запретить темный интернет полностью практически невыполнимо. Даже при принятии строгих контрмер, возможность доступа к данному уровню сети все еще осуществим с использованием разнообразных технических средств и инструментов, используемые для обхода блокировок.
В дополнение к законодательным инициативам, имеются также проекты сотрудничества между правоохранительными органами и технологическими компаниями для противодействия незаконным действиям в подпольной части сети. Однако, для успешной борьбы требуется не только техническая сторона, но и улучшения методов обнаружения и пресечения незаконных действий в этой среде.
В итоге, несмотря на введенные запреты и предпринятые усилия в борьбе с преступностью, подпольная часть сети остается серьезной проблемой, нуждающейся в комплексных подходах и коллективных усилиях со стороны правоохранительных служб, а также технологических организаций.
https://www.avito.ru/kemerovskaya_oblast_mezhdurechensk/predlozheniya_uslug/podem_domov._perenos_domov._zamena_ventsov_3831125828
judi rakyat
https://canadianpharmacy24.store/# canadapharmacyonline
canadian pharmacy world Large Selection of Medications best online canadian pharmacy
Hey there! I knoᴡ this is somеwhat off topic but I ѡas wondering іf
yоu knew wһere I coulɗ ցet a captcha plugin for my comment form?
I’m usіng tһе same blog platform as yοurs and I’m havіng prblems finding оne?
Thanks a lot!
reputable indian pharmacies: buy medicines online in india – india online pharmacy
indian pharmacy online: Cheapest online pharmacy – best india pharmacy
mail order pharmacy india: indian pharmacy delivery – Online medicine home delivery
reputable mexican pharmacies online Online Pharmacies in Mexico п»їbest mexican online pharmacies
where can i buy clomid without rx where can i buy clomid without a prescription order generic clomid pills
https://zithromaxall.shop/# generic zithromax medicine
how to buy generic clomid online: clomid generics – buy cheap clomid without prescription
https://prednisoneall.com/# generic prednisone online
prednisone 20mg by mail order: purchase prednisone from india – prednisone nz
Всем привет! Предлагаем где можно взять деньги в долг рядом с вами. Вы можете получить займ без лишних вопросов и документов. Достойные условия кредитования и срочное получение в любом городе. Наберите нам для уточнения подробной информации, либо оставляйте заявку на сайте.
buy prednisone 10mg online 20 mg of prednisone prednisone 2.5 tablet
Всем привет! Предлагаем получить займ в Минске в любое время. Вы можете получить займ без избыточных вопросов и документов. Достойные условия займа и моментальное получение в любом городе. Звоните для уточнения подробной информации, или оставляйте заявку на сайте.
Всем привет! Предлагаем деньги срочно на карту в любое время. Вы можете получить заем без избыточных вопросов и документов. Доступные условия кредитования и быстрое получение в вашем городе. Звоните для уточнения подробной информации, либо оставляйте заявку на сайте.
Здравствуйте! Предлагаем где можно взять деньги в долг рядом с вами. Вы можете получить заем без избыточных вопросов и документов. Доступные условия займа и быстрое получение в любом городе. Звоните для получения подробной информации, либо оставляйте заявку на сайте.
https://vk.com/zamena_venzov
https://zithromaxall.com/# buy zithromax no prescription
Приветствую! Возник вопрос про [url=https://dengizaimy.by/]получить займ[/url]? Предлагаем надежный источник финансовой помощи. Вы можете получить средства в долг без излишних вопросов и документов? Тогда обратитесь к нам! Мы готовы предоставить высокоприбыльные условия кредитования, быстрое решение и гарантию конфиденциальности. Не откладывайте свои планы и мечты, воспользуйтесь предложенным предложением прямо сейчас!
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Приветствую! Возник вопрос про взять денег в долг в интернете? Предоставляем безопасный источник финансовой помощи. Вы можете получить средства в долг без излишних вопросов и документов? Тогда обратитесь к нам! Мы готовы предоставить высокоприбыльные условия кредитования, оперативное решение и обеспечение конфиденциальности. Не откладывайте свои планы и мечты, воспользуйтесь предложенным предложением прямо сейчас!
Здравствуйте! Появился вопрос про взять деньги в долг срочно? Предлагаем стабильный источник финансовой помощи. Вы можете получить средства в долг без излишних вопросов и документов? Тогда обратитесь к нам! Мы предлагаем привлекательные условия займа, быстрое решение и обеспечение конфиденциальности. Не откладывайте свои планы и мечты, воспользуйтесь доступным предложением прямо сейчас!
zithromax cost canada where can i get zithromax over the counter zithromax 500mg
Всем привет! Появился вопрос про где взять деньги? Предлагаем надежный источник финансовой помощи. Вы можете получить деньги в займ без избыточных вопросов и документов? Тогда обратитесь к нам! Мы готовы предоставить высокоприбыльные условия займа, быстрое решение и гарантию конфиденциальности. Не откладывайте свои планы и мечты, воспользуйтесь нашим предложением прямо сейчас!
https://amoxilall.shop/# order amoxicillin online
Приветствую! Предлагаем взять деньги в долг на карту в любое время. Вы можете получить деньги без лишних вопросов и документов. Привлекательные условия заема и срочное получение в любом городе. Наберите нам для получения подробной информации, или оставляйте заявку на сайте.
Здравствуйте! Предлагаю деньги в долг сегодня срочно в любое время. Вы можете получить заем без избыточных вопросов и документов. Достойные условия кредитования и быстрое получение рядом с вами. Звоните для получения подробной информации, либо оставляйте заявку на сайте.
Всем привет! Предлагаю где получить деньги в любом городе. Вы можете получить финансирование без избыточных вопросов и документов. Привлекательные условия займа и быстрое получение рядом с вами. Наберите нам для уточнения подробной информации, либо оставляйте заявку на сайте.
https://clomidall.com/# cost cheap clomid without dr prescription
Здравствуйте! Предлагаю быстрый займ онлайн в любое время. Вы можете получить финансирование без лишних вопросов и документов. Достойные условия кредитования и срочное получение в любом городе. Набирайте нам для уточнения подробной информации, или оставляйте заявку на сайте.
Всем привет! Возник вопрос про получить деньги прямо сейчас? Предлагаем надежный источник финансовой помощи. Вы можете получить деньги в долг без излишних вопросов и документов? Тогда обратитесь к нам! Мы готовы предоставить высокоприбыльные условия займа, быстрое решение и обеспечение конфиденциальности. Не откладывайте свои планы и мечты, воспользуйтесь предложенным предложением прямо сейчас!
Приветствую! Возник вопрос про получить деньги срочно на карту? Предоставляем стабильный источник финансовой помощи. Вы можете получить финансирование в займ без лишних вопросов и документов? Тогда обратитесь к нам! Мы предоставляем привлекательные условия займа, оперативное решение и гарантию конфиденциальности. Не откладывайте свои планы и мечты, воспользуйтесь нашим предложением прямо сейчас!
where can i buy prednisone without prescription 40 mg daily prednisone 50 mg prednisone tablet
Здравствуйте! Возник вопрос про взять деньгибез банка в Минске? Предлагаем безопасный источник финансовой помощи. Вы можете получить деньги в займ без излишних вопросов и документов? Тогда обратитесь к нам! Мы предлагаем выгодные условия займа, быстрое решение и обеспечение конфиденциальности. Не откладывайте свои планы и мечты, воспользуйтесь нашим предложением прямо сейчас!
https://zithromaxall.com/# can you buy zithromax over the counter in mexico
https://zithromaxall.com/# zithromax online no prescription
zithromax over the counter: zithromax over the counter uk – generic zithromax india
замена венцов
zithromax 500mg over the counter: generic zithromax medicine – zithromax generic cost
prednisone 0.5 mg buy prednisone 50 mg average price of prednisone
http://clomidall.shop/# where to get clomid pills
can i buy generic clomid without insurance can i order cheap clomid for sale cost clomid without insurance
Thanks on your marvelous posting! I definitely
enjoyed reading it, you are a great author.I will always bookmark your blog and definitely will come back very soon. I
want to encourage that you continue your great posts, have a nice evening!
http://prednisoneall.com/# over the counter prednisone cream
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
http://zithromaxall.com/# zithromax for sale 500 mg
buy prednisone 10 mg prednisone online pharmacy prednisone without prescription 10mg
http://prednisoneall.com/# cost of prednisone
https://clomidall.shop/# clomid online
how can i get cheap clomid online how can i get cheap clomid without prescription can i get generic clomid prices
zithromax price south africa: can you buy zithromax over the counter in mexico – zithromax drug
amoxicillin tablet 500mg: price for amoxicillin 875 mg – generic for amoxicillin
http://prednisoneall.shop/# can you buy prednisone in canada
actos compound
amoxicillin online canada amoxil pharmacy amoxicillin where to get
п»їabilify
http://clomidall.com/# get cheap clomid no prescription
acarbose amylase
замена венцов
super kamagra super kamagra Kamagra 100mg price
Cheap Viagra 100mg: cheapest viagra – viagra canada
semaglutide for weight loss in non diabetics dosage
Pingback: child porn
buy Kamagra: Kamagra Iq – Kamagra 100mg price
Generic Viagra online best price on viagra Generic Viagra online
Viagra online price: Sildenafil 100mg price – Cheap generic Viagra online
generic sildenafil: sildenafil iq – buy Viagra online
https://kamagraiq.shop/# buy kamagra online usa
Noгmally I don’t leɑrn рost on blogs, howeveг I would like
to say that this write-up very compelⅼed me to check out and do so!
Your wгiting style hhas been surpriseԀ me. Thank you, quite great article.
Generic Tadalafil 20mg price cheapest cialis buy cialis pill
Sildenafil Citrate Tablets 100mg: sildenafil iq – Viagra generic over the counter
buy Kamagra Kamagra Oral Jelly Price Kamagra Oral Jelly
Kamagra 100mg price: Kamagra Iq – Kamagra 100mg price
Cialis without a doctor prescription: cheapest cialis – Cialis 20mg price
Pingback: porn
https://elementor.com/
Saved as a favorite, Ӏ likee your site!
Generic Cialis without a doctor prescription: Cialis 20mg price – Buy Cialis online
Buy Viagra online cheap best price on viagra best price for viagra 100mg
http://tadalafiliq.shop/# Buy Cialis online
Tadalafil price: tadalafil iq – Generic Cialis without a doctor prescription
buy Viagra online: buy Viagra over the counter – buy viagra here
http://sildenafiliq.xyz/# Buy Viagra online cheap
п»їkamagra Sildenafil Oral Jelly Kamagra tablets
Tadalafil Tablet: cialis best price – Buy Tadalafil 20mg
https://kamagraiq.shop/# buy Kamagra
cheap kamagra: kamagra best price – Kamagra 100mg
Cialis without a doctor prescription Generic Tadalafil 20mg price Buy Tadalafil 5mg
Cheap Viagra 100mg: generic ed pills – viagra canada
подъем домов
best price for viagra 100mg: buy viagra online – buy Viagra online
https://kamagraiq.com/# cheap kamagra
http://sildenafiliq.com/# viagra without prescription
Cialis 20mg price Cheap Cialis Buy Cialis online
Cheap Cialis: Buy Cialis online – Generic Cialis price
http://sildenafiliq.xyz/# sildenafil online
viagra canada: Generic Viagra for sale – buy viagra here
over the counter sildenafil sildenafil iq Viagra online price
Hi there would you mind stating which blog platform you’re using?
I’m going to start my own blog in the near future but I’m having a
hard time deciding between BlogEngine/Wordpress/B2evolution and Drupal.
The reason I ask is because your design seems different then most blogs
and I’m looking for something completely unique.
P.S My apologies for getting off-topic but I had to ask!
Buy Tadalafil 5mg: Buy Cialis online – buy cialis pill
http://kamagraiq.shop/# buy Kamagra
Kamagra 100mg price: Kamagra gel – Kamagra 100mg
generic sildenafil Viagra Tablet price viagra canada
Cialis 20mg price: Buy Tadalafil 10mg – cialis generic
Heya i’m for the first time here. I came across this board and I find It truly useful & it
helped me out much. I hope to give something back and aid others like you
helped me.
https://tadalafiliq.com/# Tadalafil Tablet
http://kamagraiq.shop/# п»їkamagra
Order Viagra 50 mg online: Generic Viagra for sale – Viagra without a doctor prescription Canada
Kamagra 100mg Sildenafil Oral Jelly п»їkamagra
indian pharmacies safe indian pharmacy delivery best online pharmacy india
http://canadianpharmgrx.xyz/# 77 canadian pharmacy
online canadian pharmacy Canadian pharmacy prices canadian drugs online
best canadian pharmacy: Cheapest drug prices Canada – canadian pharmacy prices
http://indianpharmgrx.shop/# reputable indian pharmacies
Ԍreat weblog һere! Additionally your web site
гather ɑ lot սp fast! Ꮃhat webb host ɑre yօu
the use of? Cɑn I get your affilikate hyperlink inn уour host?
I desire mʏ website loaded up ass fɑst as yourts lol
canadian online pharmacy: Cheapest drug prices Canada – ordering drugs from canada
buying prescription drugs in mexico Mexico drugstore medication from mexico pharmacy
https://mexicanpharmgrx.com/# mexican pharmaceuticals online
repaglinide bioavailability
is remeron an ssri
http://mexicanpharmgrx.shop/# mexican rx online
india pharmacy mail order indian pharmacy world pharmacy india
ремонт фундамента
what is protonix for
https://mexicanpharmgrx.com/# mexican border pharmacies shipping to usa
is robaxin a muscle relaxer
mexican border pharmacies shipping to usa Mexico drugstore mexico drug stores pharmacies
medicine in mexico pharmacies: mexican pharmacy – mexican pharmaceuticals online
https://canadianpharmgrx.xyz/# safe canadian pharmacy
situs kantorbola
KANTORBOLA situs gamin online terbaik 2024 yang menyediakan beragam permainan judi online easy to win , mulai dari permainan slot online , taruhan judi bola , taruhan live casino , dan toto macau . Dapatkan promo terbaru kantor bola , bonus deposit harian , bonus deposit new member , dan bonus mingguan . Kunjungi link kantorbola untuk melakukan pendaftaran .
mexican drugstore online: Pills from Mexican Pharmacy – buying from online mexican pharmacy
online pharmacy india indian pharmacy buy medicines online in india
http://indianpharmgrx.shop/# legitimate online pharmacies india
Informasi RTP Live Hari Ini Dari Situs RTPKANTORBOLA
Situs RTPKANTORBOLA merupakan salah satu situs yang menyediakan informasi lengkap mengenai RTP (Return to Player) live hari ini. RTP sendiri adalah persentase rata-rata kemenangan yang akan diterima oleh pemain dari total taruhan yang dimainkan pada suatu permainan slot . Dengan adanya informasi RTP live, para pemain dapat mengukur peluang mereka untuk memenangkan suatu permainan dan membuat keputusan yang lebih cerdas saat bermain.
Situs RTPKANTORBOLA menyediakan informasi RTP live dari berbagai permainan provider slot terkemuka seperti Pragmatic Play , PG Soft , Habanero , IDN Slot , No Limit City dan masih banyak rtp permainan slot yang bisa kami cek di situs RTP Kantorboal . Dengan menyediakan informasi yang akurat dan terpercaya, situs ini menjadi sumber informasi yang penting bagi para pemain judi slot online di Indonesia .
Salah satu keunggulan dari situs RTPKANTORBOLA adalah penyajian informasi yang terupdate secara real-time. Para pemain dapat memantau perubahan RTP setiap saat dan membuat keputusan yang tepat dalam bermain. Selain itu, situs ini juga menyediakan informasi mengenai RTP dari berbagai provider permainan, sehingga para pemain dapat membandingkan dan memilih permainan dengan RTP tertinggi.
Informasi RTP live yang disediakan oleh situs RTPKANTORBOLA juga sangat lengkap dan mendetail. Para pemain dapat melihat RTP dari setiap permainan, baik itu dari aspek permainan itu sendiri maupun dari provider yang menyediakannya. Hal ini sangat membantu para pemain dalam memilih permainan yang sesuai dengan preferensi dan gaya bermain mereka.
Selain itu, situs ini juga menyediakan informasi mengenai RTP live dari berbagai provider judi slot online terpercaya. Dengan begitu, para pemain dapat memilih permainan slot yang memberikan RTP terbaik dan lebih aman dalam bermain. Informasi ini juga membantu para pemain untuk menghindari potensi kerugian dengan bermain pada game slot online dengan RTP rendah .
Situs RTPKANTORBOLA juga memberikan pola dan ulasan mengenai permainan-permainan dengan RTP tertinggi. Para pemain dapat mempelajari strategi dan tips dari para ahli untuk meningkatkan peluang dalam memenangkan permainan. Analisis dan ulasan ini disajikan secara jelas dan mudah dipahami, sehingga dapat diaplikasikan dengan baik oleh para pemain.
Informasi RTP live yang disediakan oleh situs RTPKANTORBOLA juga dapat membantu para pemain dalam mengelola keuangan mereka. Dengan mengetahui RTP dari masing-masing permainan slot , para pemain dapat mengatur taruhan mereka dengan lebih bijak. Hal ini dapat membantu para pemain untuk mengurangi risiko kerugian dan meningkatkan peluang untuk mendapatkan kemenangan yang lebih besar.
Untuk mengakses informasi RTP live dari situs RTPKANTORBOLA, para pemain tidak perlu mendaftar atau membayar biaya apapun. Situs ini dapat diakses secara gratis dan tersedia untuk semua pemain judi online. Dengan begitu, semua orang dapat memanfaatkan informasi yang disediakan oleh situs RTP Kantorbola untuk meningkatkan pengalaman dan peluang mereka dalam bermain judi online.
Demikianlah informasi mengenai RTP live hari ini dari situs RTPKANTORBOLA. Dengan menyediakan informasi yang akurat, terpercaya, dan lengkap, situs ini menjadi sumber informasi yang penting bagi para pemain judi online. Dengan memanfaatkan informasi yang disediakan, para pemain dapat membuat keputusan yang lebih cerdas dan meningkatkan peluang mereka untuk memenangkan permainan. Selamat bermain dan semoga sukses!
http://mexicanpharmgrx.com/# buying prescription drugs in mexico online
online pharmacy india indian pharmacy delivery best online pharmacy india
ремонт фундамента
http://canadianpharmgrx.com/# canadian world pharmacy
mexico drug stores pharmacies mexican pharmacy mexico drug stores pharmacies
Pingback: animal porn
Online medicine home delivery: Healthcare and medicines from India – buy medicines online in india
http://mexicanpharmgrx.shop/# mexican border pharmacies shipping to usa
http://indianpharmgrx.shop/# online pharmacy india
indian pharmacy paypal Healthcare and medicines from India top 10 online pharmacy in india
mexican mail order pharmacies: mexican border pharmacies shipping to usa – mexican mail order pharmacies
Итак почему наши тоговые сигналы – всегда наилучший вариант:
Наша группа 24 часа в сутки в тренде последних тенденций и событий, которые воздействуют на криптовалюты. Это позволяет нашей команде мгновенно реагировать и подавать новые сообщения.
Наш состав владеет профундным пониманием анализа и способен выявлять устойчивые и слабые аспекты для присоединения в сделку. Это способствует минимизации опасностей и увеличению прибыли.
Мы применяем собственные боты для анализа данных для анализа графиков на все периодах времени. Это помогает нашим специалистам доставать всю картину рынка.
Прежде приведением подача в нашем канале Telegram мы делаем внимательную проверку все аспектов и подтверждаем возможный долгий или краткий. Это обеспечивает надежность и качественность наших подач.
Присоединяйтесь к нашей группе прямо сейчас и получите доступ к подтвержденным торговым сигналам, которые содействуют вам достигнуть финансового успеха на рынке криптовалют!
https://t.me/Investsany_bot
Kantorbola Situs slot Terbaik, Modal 10 Ribu Menang Puluhan Juta
Kantorbola merupakan salah satu situs judi online terbaik yang saat ini sedang populer di kalangan pecinta taruhan bola , judi live casino dan judi slot online . Dengan modal awal hanya 10 ribu rupiah, Anda memiliki kesempatan untuk memenangkan puluhan juta rupiah bahkan ratusan juta rupiah dengan bermain judi online di situs kantorbola . Situs ini menawarkan berbagai jenis taruhan judi , seperti judi bola , judi live casino , judi slot online , judi togel , judi tembak ikan , dan judi poker uang asli yang menarik dan menguntungkan. Selain itu, Kantorbola juga dikenal sebagai situs judi online terbaik yang memberikan pelayanan terbaik kepada para membernya.
Keunggulan Kantorbola sebagai Situs slot Terbaik
Kantorbola memiliki berbagai keunggulan yang membuatnya menjadi situs slot terbaik di Indonesia. Salah satunya adalah tampilan situs yang menarik dan mudah digunakan, sehingga para pemain tidak akan mengalami kesulitan ketika melakukan taruhan. Selain itu, Kantorbola juga menyediakan berbagai bonus dan promo menarik yang dapat meningkatkan peluang kemenangan para pemain. Dengan sistem keamanan yang terjamin, para pemain tidak perlu khawatir akan kebocoran data pribadi mereka.
Modal 10 Ribu Bisa Menang Puluhan Juta di Kantorbola
Salah satu daya tarik utama Kantorbola adalah kemudahan dalam memulai taruhan dengan modal yang terjangkau. Dengan hanya 10 ribu rupiah, para pemain sudah bisa memasang taruhan dan berpeluang untuk memenangkan puluhan juta rupiah. Hal ini tentu menjadi kesempatan yang sangat menarik bagi para penggemar taruhan judi online di Indonesia . Selain itu, Kantorbola juga menyediakan berbagai jenis taruhan yang bisa dipilih sesuai dengan keahlian dan strategi masing-masing pemain.
Berbagai Jenis Permainan Taruhan Bola yang Menarik
Kantorbola menyediakan berbagai jenis permainan taruhan bola yang menarik dan menguntungkan bagi para pemain. Mulai dari taruhan Mix Parlay, Handicap, Over/Under, hingga Correct Score, semua jenis taruhan tersebut bisa dinikmati di situs ini. Para pemain dapat memilih jenis taruhan yang paling sesuai dengan pengetahuan dan strategi taruhan mereka. Dengan peluang kemenangan yang besar, para pemain memiliki kesempatan untuk meraih keuntungan yang fantastis di Kantorbola.
Pelayanan Terbaik untuk Kepuasan Para Member
Selain menyediakan berbagai jenis permainan taruhan bola yang menarik, Kantorbola juga memberikan pelayanan terbaik untuk kepuasan para membernya. Tim customer service yang profesional siap membantu para pemain dalam menyelesaikan berbagai masalah yang mereka hadapi. Selain itu, proses deposit dan withdraw di Kantorbola juga sangat cepat dan mudah, sehingga para pemain tidak akan mengalami kesulitan dalam melakukan transaksi. Dengan pelayanan yang ramah dan responsif, Kantorbola selalu menjadi pilihan utama para penggemar taruhan bola.
Kesimpulan
Kantorbola merupakan situs slot terbaik yang menawarkan berbagai jenis permainan taruhan bola yang menarik dan menguntungkan. Dengan modal awal hanya 10 ribu rupiah, para pemain memiliki kesempatan untuk memenangkan puluhan juta rupiah. Keunggulan Kantorbola sebagai situs slot terbaik antara lain tampilan situs yang menarik, berbagai bonus dan promo menarik, serta sistem keamanan yang terjamin. Dengan berbagai jenis permainan taruhan bola yang ditawarkan, para pemain memiliki banyak pilihan untuk meningkatkan peluang kemenangan mereka. Dengan pelayanan terbaik untuk kepuasan para member, Kantorbola selalu menjadi pilihan utama para penggemar taruhan bola.
FAQ (Frequently Asked Questions)
Berapa modal minimal untuk bermain di Kantorbola? Modal minimal untuk bermain di Kantorbola adalah 10 ribu rupiah.
Bagaimana cara melakukan deposit di Kantorbola? Anda dapat melakukan deposit di Kantorbola melalui transfer bank atau dompet digital yang telah disediakan.
Apakah Kantorbola menyediakan bonus untuk new member? Ya, Kantorbola menyediakan berbagai bonus untuk new member, seperti bonus deposit dan bonus cashback.
Apakah Kantorbola aman digunakan untuk bermain taruhan bola online? Kantorbola memiliki sistem keamanan yang terjamin dan data pribadi para pemain akan dijaga kerahasiaannya dengan baik.
http://canadianpharmgrx.com/# best canadian pharmacy to buy from
Итак почему наши сигналы на вход – ваш наилучший вариант:
Мы постоянно в тренде текущих курсов и ситуаций, которые воздействуют на криптовалюты. Это способствует команде сразу отвечать и давать актуальные сигналы.
Наш коллектив имеет глубинным пониманием технического анализа и может выявлять мощные и слабые факторы для входа в сделку. Это содействует уменьшению потерь и повышению прибыли.
Мы же применяем личные боты-анализаторы для изучения графиков на любых временных промежутках. Это помогает нам получить полноценную картину рынка.
Прежде опубликованием подача в нашем канале Telegram мы проводим детальную проверку все фасадов и подтверждаем возможное лонг или период короткой торговли. Это обеспечивает достоверность и качество наших сигналов.
Присоединяйтесь к нашей команде к нашему Telegram каналу прямо сейчас и достаньте доступ к подтвержденным торговым подачам, которые помогут вам добиться успеха в финансах на рынке криптовалют!
https://t.me/Investsany_bot
Итак почему наши сигналы на вход – всегда идеальный вариант:
Наша команда утром и вечером, днём и ночью на волне актуальных трендов и моментов, которые воздействуют на криптовалюты. Это позволяет нам мгновенно действовать и подавать актуальные подачи.
Наш состав имеет предельным знанием анализа и может обнаруживать крепкие и слабые стороны для вступления в сделку. Это способствует минимизации угроз и максимизации прибыли.
Мы же внедряем собственные боты для анализа для просмотра графиков на всех временных промежутках. Это помогает нам доставать всю картину рынка.
Прежде опубликованием подача в нашем Telegram команда осуществляем педантичную проверку всех фасадов и подтверждаем возможное лонг или краткий. Это обеспечивает предсказуемость и качество наших сигналов.
Присоединяйтесь к нашей команде к нашему прямо сейчас и достаньте доступ к подтвержденным торговым подачам, которые помогут вам вам достигнуть финансового успеха на крипторынке!
https://t.me/Investsany_bot
Итак почему наши тоговые сигналы – всегда оптимальный выбор:
Мы все время в курсе современных тенденций и событий, которые воздействуют на криптовалюты. Это дает возможность коллективу незамедлительно действовать и давать новые сообщения.
Наш состав имеет предельным пониманием анализа и способен выявлять сильные и незащищенные факторы для присоединения в сделку. Это содействует уменьшению угроз и максимизации прибыли.
Мы же применяем собственные боты для анализа данных для анализа графиков на любых периодах времени. Это помогает нам достать понятную картину рынка.
Перед подачей подачи в нашем канале Telegram мы осуществляем детальную проверку все фасадов и подтверждаем допустимая длинный или короткий. Это обеспечивает достоверность и качественные характеристики наших подач.
Присоединяйтесь к нашей команде к нашей группе прямо сейчас и достаньте доступ к подтвержденным торговым подачам, которые содействуют вам добиться успеха в финансах на крипторынке!
https://t.me/Investsany_bot
mexico pharmacy Mexico drugstore mexico pharmacies prescription drugs
https://indianpharmgrx.shop/# buy prescription drugs from india
http://canadianpharmgrx.xyz/# buying drugs from canada
northwest canadian pharmacy: Pharmacies in Canada that ship to the US – canadian pharmacy king
who should take tamoxifen femara vs tamoxifen tamoxifen brand name
buy cipro online without prescription: buy cipro cheap – buy cipro online canada
doxycycline pills online doxycycline price of doxycycline
kantorbola
Mengenal Situs Gaming Online Terbaik Kantorbola
Kantorbola merupakan situs gaming online terbaik yang menawarkan pengalaman bermain yang seru dan mengasyikkan bagi para pecinta game. Dengan berbagai pilihan game menarik dan grafis yang memukau, Kantorbola menjadi pilihan utama bagi para gamers yang ingin mencari hiburan dan tantangan baru. Dengan layanan customer service yang ramah dan profesional, serta sistem keamanan yang terjamin, Kantorbola siap memberikan pengalaman bermain yang terbaik dan menyenangkan bagi semua membernya. Jadi, tunggu apalagi? Bergabunglah sekarang dan rasakan sensasi seru bermain game di Kantorbola!
Situs kantor bola menyediakan beberapa link alternatif terbaru
Situs kantor bola merupakan salah satu situs gaming online terbaik yang menyediakan berbagai link alternatif terbaru untuk memudahkan para pengguna dalam mengakses situs tersebut. Dengan adanya link alternatif terbaru ini, para pengguna dapat tetap mengakses situs kantor bola meskipun terjadi pemblokiran dari pemerintah atau internet positif. Hal ini tentu menjadi kabar baik bagi para pecinta judi online yang ingin tetap bermain tanpa kendala akses ke situs kantor bola.
Dengan menyediakan beberapa link alternatif terbaru, situs kantor bola juga dapat memberikan variasi akses kepada para pengguna. Hal ini memungkinkan para pengguna untuk memilih link alternatif mana yang paling cepat dan stabil dalam mengakses situs tersebut. Dengan demikian, pengalaman bermain judi online di situs kantor bola akan menjadi lebih lancar dan menyenangkan.
Selain itu, situs kantor bola juga menunjukkan komitmennya dalam memberikan pelayanan terbaik kepada para pengguna dengan menyediakan link alternatif terbaru secara berkala. Dengan begitu, para pengguna tidak perlu khawatir akan kehilangan akses ke situs kantor bola karena selalu ada link alternatif terbaru yang dapat digunakan sebagai backup. Keberadaan link alternatif tersebut juga menunjukkan bahwa situs kantor bola selalu berusaha untuk tetap eksis dan dapat diakses oleh para pengguna setianya.
Secara keseluruhan, kehadiran beberapa link alternatif terbaru dari situs kantor bola merupakan salah satu bentuk komitmen dari situs tersebut dalam memberikan kemudahan dan kenyamanan kepada para pengguna. Dengan adanya link alternatif tersebut, para pengguna dapat terus mengakses situs kantor bola tanpa hambatan apapun. Hal ini tentu akan semakin meningkatkan popularitas situs kantor bola sebagai salah satu situs gaming online terbaik di Indonesia. Berikut beberapa link alternatif dari situs kantorbola , diantaranya .
1. Link Kantorbola77
Link Kantorbola77 merupakan salah satu situs gaming online terbaik yang saat ini banyak diminati oleh para pecinta judi online. Dengan berbagai pilihan permainan yang lengkap dan berkualitas, situs ini mampu memberikan pengalaman bermain yang memuaskan bagi para membernya. Selain itu, Kantorbola77 juga menawarkan berbagai bonus dan promo menarik yang dapat meningkatkan peluang kemenangan para pemain.
Salah satu keunggulan dari Link Kantorbola77 adalah sistem keamanan yang sangat terjamin. Dengan teknologi enkripsi yang canggih, situs ini menjaga data pribadi dan transaksi keuangan para membernya dengan sangat baik. Hal ini membuat para pemain merasa aman dan nyaman saat bermain di Kantorbola77 tanpa perlu khawatir akan adanya kebocoran data atau tindakan kecurangan yang merugikan.
Selain itu, Link Kantorbola77 juga menyediakan layanan pelanggan yang siap membantu para pemain 24 jam non-stop. Tim customer service yang profesional dan responsif siap membantu para member dalam menyelesaikan berbagai kendala atau pertanyaan yang mereka hadapi saat bermain. Dengan layanan yang ramah dan efisien, Kantorbola77 menempatkan kepuasan para pemain sebagai prioritas utama mereka.
Dengan reputasi yang baik dan pengalaman yang telah teruji, Link Kantorbola77 layak untuk menjadi pilihan utama bagi para pecinta judi online. Dengan berbagai keunggulan yang dimilikinya, situs ini memberikan pengalaman bermain yang memuaskan dan menguntungkan bagi para membernya. Jadi, jangan ragu untuk bergabung dan mencoba keberuntungan Anda di Kantorbola77.
2. Link Kantorbola88
Link kantorbola88 adalah salah satu situs gaming online terbaik yang harus dikenal oleh para pecinta judi online. Dengan menyediakan berbagai jenis permainan seperti judi bola, casino, slot online, poker, dan banyak lagi, kantorbola88 menjadi pilihan utama bagi para pemain yang ingin mencoba keberuntungan mereka. Link ini memberikan akses mudah dan cepat untuk para pemain yang ingin bermain tanpa harus repot mencari situs judi online yang terpercaya.
Selain itu, kantorbola88 juga dikenal sebagai situs yang memiliki reputasi baik dalam hal pelayanan dan keamanan. Dengan sistem keamanan yang canggih dan profesional, para pemain dapat bermain tanpa perlu khawatir akan kebocoran data pribadi atau transaksi keuangan mereka. Selain itu, layanan pelanggan yang ramah dan responsif juga membuat pengalaman bermain di kantorbola88 menjadi lebih menyenangkan dan nyaman.
Selain itu, link kantorbola88 juga menawarkan berbagai bonus dan promosi menarik yang dapat dinikmati oleh para pemain. Mulai dari bonus deposit, cashback, hingga bonus referral, semua memberikan kesempatan bagi pemain untuk mendapatkan keuntungan lebih saat bermain di situs ini. Dengan adanya bonus-bonus tersebut, kantorbola88 terus berusaha memberikan yang terbaik bagi para pemainnya agar selalu merasa puas dan senang bermain di situs ini.
Dengan reputasi yang baik, pelayanan yang prima, keamanan yang terjamin, dan bonus yang menggiurkan, link kantorbola88 adalah pilihan yang tepat bagi para pemain judi online yang ingin merasakan pengalaman bermain yang seru dan menguntungkan. Dengan bergabung di situs ini, para pemain dapat merasakan sensasi bermain judi online yang berkualitas dan terpercaya, serta memiliki peluang untuk mendapatkan keuntungan besar. Jadi, jangan ragu untuk mencoba keberuntungan Anda di kantorbola88 dan nikmati pengalaman bermain yang tak terlupakan.
3. Link Kantorbola88
Kantorbola99 merupakan salah satu situs gaming online terbaik yang dapat menjadi pilihan bagi para pecinta judi online. Situs ini menawarkan berbagai permainan menarik seperti judi bola, casino online, slot online, poker, dan masih banyak lagi. Dengan berbagai pilihan permainan yang disediakan, para pemain dapat menikmati pengalaman berjudi yang seru dan mengasyikkan.
Salah satu keunggulan dari Kantorbola99 adalah sistem keamanan yang sangat terjamin. Situs ini menggunakan teknologi enkripsi terbaru untuk melindungi data pribadi dan transaksi keuangan para pemain. Dengan demikian, para pemain bisa bermain dengan tenang tanpa perlu khawatir tentang kebocoran data pribadi atau kecurangan dalam permainan.
Selain itu, Kantorbola99 juga menawarkan berbagai bonus dan promo menarik bagi para pemain setianya. Mulai dari bonus deposit, bonus cashback, hingga bonus referral yang dapat meningkatkan peluang para pemain untuk meraih kemenangan. Dengan adanya bonus dan promo ini, para pemain dapat merasa lebih diuntungkan dan semakin termotivasi untuk bermain di situs ini.
Dengan reputasi yang baik dan pengalaman yang telah terbukti, Kantorbola99 menjadi pilihan yang tepat bagi para pecinta judi online. Dengan pelayanan yang ramah dan responsif, para pemain juga dapat mendapatkan bantuan dan dukungan kapan pun dibutuhkan. Jadi, tidak heran jika Kantorbola99 menjadi salah satu situs gaming online terbaik yang banyak direkomendasikan oleh para pemain judi online.
Promo Terbaik Dari Situs kantorbola
Kantorbola merupakan salah satu situs gaming online terbaik yang menyediakan berbagai jenis permainan menarik seperti judi bola, casino, poker, slots, dan masih banyak lagi. Situs ini telah menjadi pilihan utama bagi para pecinta judi online karena reputasinya yang terpercaya dan kualitas layanannya yang prima. Selain itu, Kantorbola juga seringkali memberikan promo-promo menarik kepada para membernya, salah satunya adalah promo terbaik yang dapat meningkatkan peluang kemenangan para pemain.
Promo terbaik dari situs Kantorbola biasanya berupa bonus deposit, cashback, maupun event-event menarik yang diadakan secara berkala. Dengan adanya promo-promo ini, para pemain memiliki kesempatan untuk mendapatkan keuntungan lebih besar dan juga kesempatan untuk memenangkan hadiah-hadiah menarik. Selain itu, promo-promo ini juga menjadi daya tarik bagi para pemain baru yang ingin mencoba bermain di situs Kantorbola.
Salah satu promo terbaik dari situs Kantorbola yang paling diminati adalah bonus deposit new member sebesar 100%. Dengan bonus ini, para pemain baru bisa mendapatkan tambahan saldo sebesar 100% dari jumlah deposit yang mereka lakukan. Hal ini tentu saja menjadi kesempatan emas bagi para pemain untuk bisa bermain lebih lama dan meningkatkan peluang kemenangan mereka. Selain itu, Kantorbola juga selalu memberikan promo-promo menarik lainnya yang dapat dinikmati oleh semua membernya.
Dengan berbagai promo terbaik yang ditawarkan oleh situs Kantorbola, para pemain memiliki banyak kesempatan untuk meraih kemenangan besar dan mendapatkan pengalaman bermain judi online yang lebih menyenangkan. Jadi, jangan ragu untuk bergabung dan mencoba keberuntungan Anda di situs gaming online terbaik ini. Dapatkan promo-promo menarik dan nikmati berbagai jenis permainan seru hanya di Kantorbola.
Deposit Kilat Di Kantorbola Melalui QRIS
Deposit kilat di Kantorbola melalui QRIS merupakan salah satu fitur yang mempermudah para pemain judi online untuk melakukan transaksi secara cepat dan aman. Dengan menggunakan QRIS, para pemain dapat melakukan deposit dengan mudah tanpa perlu repot mencari nomor rekening atau melakukan transfer manual.
QRIS sendiri merupakan sistem pembayaran digital yang memanfaatkan kode QR untuk memfasilitasi transaksi pembayaran. Dengan menggunakan QRIS, para pemain judi online dapat melakukan deposit hanya dengan melakukan pemindaian kode QR yang tersedia di situs Kantorbola. Proses deposit pun dapat dilakukan dalam waktu yang sangat singkat, sehingga para pemain tidak perlu menunggu lama untuk bisa mulai bermain.
Keunggulan deposit kilat di Kantorbola melalui QRIS adalah kemudahan dan kecepatan transaksi yang ditawarkan. Para pemain judi online tidak perlu lagi repot mencari nomor rekening atau melakukan transfer manual yang memakan waktu. Cukup dengan melakukan pemindaian kode QR, deposit dapat langsung terproses dan saldo akun pemain pun akan langsung bertambah.
Dengan adanya fitur deposit kilat di Kantorbola melalui QRIS, para pemain judi online dapat lebih fokus pada permainan tanpa harus terganggu dengan urusan transaksi. QRIS memungkinkan para pemain untuk melakukan deposit kapan pun dan di mana pun dengan mudah, sehingga pengalaman bermain judi online di Kantorbola menjadi lebih menyenangkan dan praktis.
Dari ulasan mengenai mengenal situs gaming online terbaik Kantorbola, dapat disimpulkan bahwa situs tersebut menawarkan berbagai jenis permainan yang menarik dan populer di kalangan para penggemar game. Dengan tampilan yang menarik dan user-friendly, Kantorbola memberikan pengalaman bermain yang menyenangkan dan memuaskan bagi para pemain. Selain itu, keamanan dan keamanan privasi pengguna juga menjadi prioritas utama dalam situs tersebut sehingga para pemain dapat bermain dengan tenang tanpa perlu khawatir akan data pribadi mereka.
Selain itu, Kantorbola juga memberikan berbagai bonus dan promo menarik bagi para pemain, seperti bonus deposit dan cashback yang dapat meningkatkan keuntungan bermain. Dengan pelayanan customer service yang responsif dan profesional, para pemain juga dapat mendapatkan bantuan yang dibutuhkan dengan cepat dan mudah. Dengan reputasi yang baik dan banyaknya testimonial positif dari para pemain, Kantorbola menjadi pilihan situs gaming online terbaik bagi para pecinta game di Indonesia.
Frequently Asked Question ( FAQ )
A : Apa yang dimaksud dengan Situs Gaming Online Terbaik Kantorbola?
Q : Situs Gaming Online Terbaik Kantorbola adalah platform online yang menyediakan berbagai jenis permainan game yang berkualitas dan menarik untuk dimainkan.
A : Apa saja jenis permainan yang tersedia di Situs Gaming Online Terbaik Kantorbola?
Q : Di Situs Gaming Online Terbaik Kantorbola, anda dapat menemukan berbagai jenis permainan seperti game slot, poker, roulette, blackjack, dan masih banyak lagi.
A : Bagaimana cara mendaftar di Situs Gaming Online Terbaik Kantorbola?
Q : Untuk mendaftar di Situs Gaming Online Terbaik Kantorbola, anda hanya perlu mengakses situs resmi mereka, mengklik tombol “Daftar” dan mengisi formulir pendaftaran yang disediakan.
A : Apakah Situs Gaming Online Terbaik Kantorbola aman digunakan untuk bermain game?
Q : Ya, Situs Gaming Online Terbaik Kantorbola telah memastikan keamanan dan kerahasiaan data para penggunanya dengan menggunakan sistem keamanan terkini.
A : Apakah ada bonus atau promo menarik yang ditawarkan oleh Situs Gaming Online Terbaik Kantorbola?
Q : Tentu saja, Situs Gaming Online Terbaik Kantorbola seringkali menawarkan berbagai bonus dan promo menarik seperti bonus deposit, cashback, dan bonus referral untuk para membernya. Jadi pastikan untuk selalu memeriksa promosi yang sedang berlangsung di situs mereka.
buy doxycycline without prescription uk: buy doxycycline cheap – buy doxycycline cheap
http://ciprofloxacin.guru/# antibiotics cipro
odering doxycycline doxycycline 200 mg doxycycline without a prescription
перевод с иностранных языков
doxycycline 100mg tablets: doxycycline 100mg capsules – doxycycline 100mg capsules
ciprofloxacin generic price: ciprofloxacin generic – ciprofloxacin over the counter
buy cipro cipro 500mg best prices ciprofloxacin mail online
Итак почему наши тоговые сигналы – всегда наилучший вариант:
Мы утром и вечером, днём и ночью в тренде современных курсов и моментов, которые влияют на криптовалюты. Это дает возможность нам мгновенно отвечать и предоставлять свежие трейды.
Наш коллектив имеет глубоким знанием теханализа и может выделить устойчивые и уязвимые стороны для присоединения в сделку. Это способствует для снижения угроз и способствует для растущей прибыли.
Мы же применяем личные боты анализа для просмотра графиков на всех интервалах. Это содействует нашим специалистам завоевать полную картину рынка.
Прежде подачей подачи в нашем Telegram мы делаем внимательную проверку всех аспектов и подтверждаем допустимый длинный или период короткой торговли. Это обеспечивает достоверность и качественность наших подач.
Присоединяйтесь к нашей команде к нашему Telegram каналу прямо сейчас и достаньте доступ к проверенным торговым подачам, которые помогут вам получить финансовых результатов на рынке криптовалют!
https://t.me/Investsany_bot
antibiotics cipro: ciprofloxacin over the counter – buy cipro online canada
diflucan pill for sale diflucan oral buy diflucan online uk
purchase cytotec: buy cytotec in usa – buy cytotec over the counter
doxycycline: doxycycline mono – doxycycline order online
diflucan best price: diflucan candida – diflucan tablet 100 mg
order doxycycline online buy doxycycline cheap doxycycline 50 mg
https://ciprofloxacin.guru/# ciprofloxacin order online
JDBslot
JDB slot | The first bonus to rock the slot world
Exclusive event to earn real money and slot game points
JDB demo slot games for free = ?? Lucky Spin Lucky Draw!
How to earn reels free 2000? follow jdb slot games for free
#jdbslot
Demo making money : https://jdb777.com
#jdbslot #slotgamesforfree #howtoearnreels #cashreels
#slotgamepoint #demomakingmoney
Cash reels only at slot games for free
More professional jdb game bonus knowledge
Ways to Earn Rotations Points Gratis 2000: Your Final Instruction to Triumphant Huge with JDB One-armed bandits
Are you ready to embark on an electrifying voyage into the globe of online slot games? Seek no farther, just twist to JDB777 FreeGames, where enthusiasm and big wins look forward to you at each spin of the reel. In this all-encompassing manual, we’ll demonstrate you methods to earn reels credit gratis 2000 and open the exciting world of JDB slots.
Feel the Thrill of Machine Games for Free
At JDB777 FreeGames, we provide a broad selection of captivating slot games that are certain to keep you entertained for hours on end. From classic fruit machines to immersive themed slots, there’s something for every single type of player to enjoy. And the top part? You can play all of our slot games for free and gain real cash prizes!
Release Free Cash Reels and Achieve Big
One of the most stimulating features of JDB777 FreeGames is the opportunity to earn reels points free 2000, which can be exchanged for real cash. Easily sign up for an account, and you’ll get your complimentary bonus to commence spinning and winning. With our bountiful promotions and bonuses, the sky’s the boundary when it comes to your winnings!
Direct Approaches and Scores System
To optimize your winnings and unlock the full potential of our slot games, it’s important to comprehend the approaches and points system. Our professional guides will take you through everything you have to have to know, from choosing out the right games to apprehending how to acquire bonus points and cash prizes.
Distinctive Promotions and Specific Offers
As a member of JDB777 FreeGames, you’ll have access to exclusive promotions and special offers that are guaranteed to enhance your gaming experience. From welcome bonuses to daily rebates, there are plenty of possibilities to enhance your winnings and take your gameplay to the upcoming level.
Join Us Today and Begin Winning
Don’t miss out on your chance to win big with JDB777 FreeGames. Sign up now to assert your complimentary bonus of 2000 credits and commence spinning the reels for your chance to win real cash prizes. With our stimulating range of slot games and generous promotions, the potentialities are endless. Join us today and initiate winning!
Intro
betvisa vietnam
Betvisa vietnam | Grand Prize Breakout!
Betway Highlights | 499,000 Extra Bonus on betvisa com!
Cockfight to win up to 3,888,000 on betvisa game
Daily Deposit, Sunday Bonus on betvisa app 888,000!
#betvisavietnam
200% Bonus on instant deposits—start your win streak!
200% welcome bonus! Slots and Fishing Games
https://www.betvisa.com/
#betvisavietnam #betvisagame #betvisaapp
#betvisacom #betvisacasinoapp
Birthday bash? Up to 1,800,000 in prizes! Enjoy!
Friday Shopping Frenzy betvisa vietnam 100,000 VND!
Betvisa Casino App Daily Login 12% Bonus Up to 1,500,000VND!
Tìm hiểu Thế Giới Cá Cược Trực Tuyến với BetVisa!
Hệ thống BetVisa, một trong những nền tảng hàng đầu tại châu Á, được thành lập vào năm 2017 và hoạt động dưới phê chuẩn của Curacao, đã thu hút hơn 2 triệu người dùng trên toàn thế giới. Với cam kết đem đến trải nghiệm cá cược đảm bảo và tin cậy nhất, BetVisa sớm trở thành lựa chọn hàng đầu của người chơi trực tuyến.
BetVisa không dừng lại ở việc cung cấp các trò chơi phong phú như xổ số, sòng bạc trực tiếp, thể thao trực tiếp và thể thao điện tử, mà còn mang đến cho người chơi những ưu đãi hấp dẫn. Thành viên mới đăng ký sẽ được tặng ngay 5 cơ hội miễn phí và có cơ hội giành giải thưởng lớn.
Đặc biệt, BetVisa hỗ trợ nhiều phương thức thanh toán linh hoạt như Betvisa Vietnam, cùng với các ưu đãi độc quyền như thưởng chào mừng lên đến 200%. Bên cạnh đó, hàng tuần còn có các chương trình khuyến mãi độc đáo như chương trình giải thưởng Sinh Nhật và Chủ Nhật Mua Sắm Điên Cuồng, mang đến cho người chơi cơ hội thắng lớn.
Nhờ vào sự cam kết về kinh nghiệm cá cược tinh vi nhất và dịch vụ khách hàng chuyên trách, BetVisa hoàn toàn tự tin là điểm đến lý tưởng cho những ai đam mê trò chơi trực tuyến. Hãy gắn bó ngay hôm nay và bắt đầu hành trình của bạn tại BetVisa – nơi niềm vui và may mắn chính là điều không thể thiếu được.
where can i purchase diflucan over the counter: diflucan 125mg – diflucan 6 tabs
doxycycline prices doxycycline prices doxycycline hyclate 100 mg cap
doxycycline hyclate: doxy 200 – order doxycycline online
перевод с иностранных языков
ciprofloxacin generic purchase cipro buy cipro cheap
buy cipro online: buy cipro online canada – antibiotics cipro
Intro
betvisa philippines
Betvisa philippines | The Filipino Carnival, Spinning for Treasures!
Betvisa Philippines Surprises | Spin daily and win ₱8,888 Grand Prize!
Register for a chance to win ₱8,888 Bonus Tickets! Explore Betvisa.com!
Wild All Over Grab 58% YB Bonus at Betvisa Casino! Take the challenge!
#betvisaphilippines
Get 88 on your first 50 Experience Betvisa Online’s Bonus Gift!
Weekend Instant Daily Recharge at betvisa.com
https://www.88betvisa.com/
#betvisaphilippines #betvisaonline #betvisacasino
#betvisacom #betvisa.com
Dịch vụ – Điểm Đến Tuyệt Vời Cho Người Chơi Trực Tuyến
Khám Phá Thế Giới Cá Cược Trực Tuyến với BetVisa!
BetVisa được thành lập vào năm 2017 và tiến hành theo giấy phép trò chơi Curacao với hơn 2 triệu người dùng. Với tính cam kết đem đến trải nghiệm cá cược chắc chắn và tin cậy nhất, BetVisa nhanh chóng trở thành lựa chọn hàng đầu của người chơi trực tuyến.
Cổng chơi không chỉ đưa ra các trò chơi phong phú như xổ số, sòng bạc trực tiếp, thể thao trực tiếp và thể thao điện tử, mà còn mang lại cho người chơi những phần thưởng hấp dẫn. Thành viên mới đăng ký sẽ được tặng ngay 5 vòng quay miễn phí và có cơ hội giành giải thưởng lớn.
BetVisa hỗ trợ nhiều hình thức thanh toán linh hoạt như Betvisa Vietnam, kết hợp với các ưu đãi độc quyền như thưởng chào mừng lên đến 200%. Bên cạnh đó, hàng tuần còn có chương trình ưu đãi độc đáo như chương trình giải thưởng Sinh Nhật và Chủ Nhật Mua Sắm Điên Cuồng, mang lại cho người chơi thời cơ thắng lớn.
Với lời hứa về trải nghiệm cá cược tốt nhất và dịch vụ khách hàng tận tâm, BetVisa tự tin là điểm đến lý tưởng cho những ai đam mê trò chơi trực tuyến. Hãy đăng ký ngay hôm nay và bắt đầu hành trình của bạn tại BetVisa – nơi niềm vui và may mắn chính là điều tất yếu!
cytotec online: cytotec pills online – buy misoprostol over the counter
Your way of telling all in this article is actually fastidious, all can without difficulty
know it, Thanks a lot.
tamoxifen benefits: tamoxifen and uterine thickening – tamoxifen generic
Misoprostol 200 mg buy online buy cytotec online Abortion pills online
https://misoprostol.top/# buy cytotec in usa
В настоящее время наши дни могут содержать неожиданные расходы и экономические трудности, и в такие моменты каждый ищет надежную поддержку. На сайте взять деньги в долг вам помогут без лишних сложностей. В своей роли агента я стремлюсь поделиться этими сведениями, чтобы помочь людям в сложной ситуации. Наша система обеспечивает честные условия и быструю обработку заявок, чтобы каждый мог разрешить свои финансовые вопросы оперативно и без лишних затрат времени.
В настоящее время наши дни могут содержать неожиданные расходы и финансовые вызовы, и в такие моменты каждый ищет помощь. На сайте займ в беларуси вам помогут без избыточной бюрократии. В своей роли представителя я стремлюсь поделиться этими сведениями, чтобы помочь людям в сложной ситуации. Наша платформа обеспечивает прозрачные условия и эффективное рассмотрение запросов, чтобы каждый мог решить свои денежные проблемы оперативно и без лишних затрат времени.
В настоящее время наши дни могут содержать неожиданные расходы и экономические трудности, и в такие моменты каждый ищет помощь. На сайте взять денег в долг срочно вам помогут без избыточной бюрократии. В своей роли представителя я стремлюсь поделиться этими сведениями, чтобы помочь тем, кто столкнулся с временными трудностями. Наша система обеспечивает прозрачные условия и быструю обработку заявок, чтобы каждый мог разрешить свои финансовые вопросы оперативно и без лишних затрат времени.
В настоящее время наши дни могут содержать внезапные издержки и финансовые вызовы, и в такие моменты каждый ищет надежную поддержку. На сайте займ онлайн вам помогут без лишних сложностей. В своей роли агента я стремлюсь поделиться этими сведениями, чтобы помочь людям в сложной ситуации. Наша платформа обеспечивает прозрачные условия и эффективное рассмотрение запросов, чтобы каждый мог разрешить свои финансовые вопросы быстро и без лишних хлопот.
does tamoxifen cause bone loss: tamoxifen postmenopausal – raloxifene vs tamoxifen
App cá độ:Hướng dẫn tải app cá cược uy tín RG777 đúng cách
Bạn có biết? Tải app cá độ đúng cách sẽ giúp tiết kiệm thời gian đăng nhập, tăng tính an toàn và bảo mật cho tài khoản của bạn! Vậy đâu là cách để tải một app cá cược uy tín dễ dàng và chính xác? Xem ngay bài viết này nếu bạn muốn chơi cá cược trực tuyến an toàn!
tải về ngay lập tức
RG777 – Nhà Cái Uy Tín Hàng Đầu Việt Nam
Link tải app cá độ nét nhất 2023:RG777
Để đảm bảo việc tải ứng dụng cá cược của bạn an toàn và nhanh chóng, người chơi có thể sử dụng đường link sau.
tải về ngay lập tức
buy cipro cheap buy cipro online without prescription buy cipro cheap
高雄外送茶
現代社會,快遞已成為大眾化的服務業,吸引了許多人的注意和參與。 與傳統夜店、酒吧不同,外帶提供了更私密、便捷的服務方式,讓人們有機會在家中或特定地點與美女共度美好時光。
多樣化選擇
從台灣到日本,馬來西亞到越南,外送業提供了多樣化的女孩選擇,以滿足不同人群的需求和喜好。 無論你喜歡什麼類型的女孩,你都可以在外賣行業找到合適的女孩。
不同的價格水平
價格範圍從實惠到豪華。 無論您的預算如何,您都可以找到適合您需求的女孩,享受優質的服務並度過愉快的時光。
快遞業高度重視安全和隱私保護,提供多種安全措施和保障,讓客戶放心使用服務,無需擔心個人資訊外洩或安全問題。
如果你想成為一名經驗豐富的外包司機,外包產業也將為你提供廣泛的選擇和專屬服務。 只需按照步驟操作,您就可以輕鬆享受快遞行業帶來的樂趣和便利。
蓬勃發展的快遞產業為人們提供了一種新的娛樂休閒方式,讓人們在忙碌的生活中得到放鬆,享受美好時光。
robot 88
В наше время многие из нас сталкиваются с непредвиденными расходами и денежными трудностями, и в такие моменты важно иметь возможность взять кредит. На сайте dengizaimy.ru вам помогут быстро и удобно. В качестве представителя Брокерс Групп, я рад делиться этой информацией, чтобы помочь людям, кто столкнулся с финансовыми трудностями. Наша система гарантирует честные условия и быструю обработку заявок, чтобы каждый мог решить свои финансовые вопросы с минимальными временными затратами.
В наше время многие из нас сталкиваются с непредвиденными расходами и экономическими вызовами, и в такие моменты важно иметь доступ к дополнительным средствам. На сайте займ денег вам помогут быстро и удобно. В качестве официального представителя Брокерс Групп, я с удовольствием делиться этой важной информацией, чтобы помочь людям, кто нуждается в финансовой поддержке. Наша система гарантирует прозрачные условия и быструю обработку заявок, чтобы каждый мог решить свои финансовые вопросы быстро и эффективно.
Abortion pills online: buy cytotec online – buy cytotec
В наше время многие из нас сталкиваются с внезапными затратами и денежными трудностями, и в такие моменты важно иметь возможность взять кредит. На сайте получить деньги вам помогут с минимальными усилиями. В качестве представителя Брокерс Групп, я рад делиться этой информацией, чтобы помочь людям, кто нуждается в финансовой поддержке. Наша платформа гарантирует честные условия и оперативное рассмотрение запросов, чтобы каждый мог решить свои финансовые вопросы с минимальными временными затратами.
rg777
App cá độ:Hướng dẫn tải app cá cược uy tín RG777 đúng cách
Bạn có biết? Tải app cá độ đúng cách sẽ giúp tiết kiệm thời gian đăng nhập, tăng tính an toàn và bảo mật cho tài khoản của bạn! Vậy đâu là cách để tải một app cá cược uy tín dễ dàng và chính xác? Xem ngay bài viết này nếu bạn muốn chơi cá cược trực tuyến an toàn!
tải về ngay lập tức
RG777 – Nhà Cái Uy Tín Hàng Đầu Việt Nam
Link tải app cá độ nét nhất 2023:RG777
Để đảm bảo việc tải ứng dụng cá cược của bạn an toàn và nhanh chóng, người chơi có thể sử dụng đường link sau.
tải về ngay lập tức
App cá độ:Hướng dẫn tải app cá cược uy tín RG777 đúng cách
Bạn có biết? Tải app cá độ đúng cách sẽ giúp tiết kiệm thời gian đăng nhập, tăng tính an toàn và bảo mật cho tài khoản của bạn! Vậy đâu là cách để tải một app cá cược uy tín dễ dàng và chính xác? Xem ngay bài viết này nếu bạn muốn chơi cá cược trực tuyến an toàn!
tải về ngay lập tức
RG777 – Nhà Cái Uy Tín Hàng Đầu Việt Nam
Link tải app cá độ nét nhất 2023:RG777
Để đảm bảo việc tải ứng dụng cá cược của bạn an toàn và nhanh chóng, người chơi có thể sử dụng đường link sau.
tải về ngay lập tức
В наше время многие из нас сталкиваются с непредвиденными расходами и экономическими вызовами, и в такие моменты важно иметь возможность взять кредит. На сайте займ в беларуси вам помогут быстро и удобно. В качестве представителя Брокерс Групп, я рад делиться этой информацией, чтобы помочь людям, кто нуждается в финансовой поддержке. Наша платформа гарантирует прозрачные условия и быструю обработку заявок, чтобы каждый мог решить свои финансовые вопросы с минимальными временными затратами.
doxylin doxycycline 100mg online doxycycline without prescription
В настоящей эпохе финансовые сложности встречаются часто, и каждый из нас может оказаться в ситуации, когда необходима дополнительная финансовая поддержка. На сайте МаниБел помогут решить эти проблемы, предоставляя простой и лёгкий метод займа. Мы понимаем, что время играет ключевую роль, поэтому мы обрабатываем заявки оперативно и эффективно. В роли представителя Манибел, наша цель – помочь каждому клиенту преодолеть финансовые затруднения, предоставив прозрачные и выгодные условия кредитования. Доверьтесь нашей компании, и мы решим ваши финансовые проблемы.
diflucan brand name: diflucan prescription australia – where can i get diflucan over the counter
В настоящей эпохе финансовые сложности не редкость, и каждый человек может оказаться в ситуации, когда потребуется дополнительная финансовая помощь. На сайте срочно взять деньги помогут преодолеть эти трудности, предоставляя простой и лёгкий метод займа. Мы осознаём, что время играет ключевую роль, поэтому наш процесс обработки заявок максимально быстр и эффективен. В роли представителя Манибел, наша цель – помочь каждому клиенту преодолеть финансовые затруднения, предложив ясные и выгодные условия займа. Доверьтесь нашей компании, и мы поможем вам в решении ваших финансовых проблем.
В сегодняшнем обществе финансовые трудности встречаются часто, и каждый человек может оказаться в ситуации, когда потребуется дополнительная финансовая помощь. На сайте деньги в долг Минск помогут преодолеть эти трудности, принося простой и удобный способ получения кредита. Мы понимаем, что время играет ключевую роль, поэтому наш процесс обработки заявок максимально быстр и эффективен. В качестве представителя Манибел, мы нацелены на то, чтобы помочь каждому клиенту преодолеть свои денежные трудности, предоставив прозрачные и выгодные условия кредитования. Доверьтесь нам, и мы поможем вам в решении ваших финансовых проблем.
В настоящей эпохе финансовые трудности не редкость, и каждый человек может оказаться в ситуации, когда необходима дополнительная финансовая поддержка. На сайте взять деньги в долг помогут решить эти проблемы, принося простой и удобный способ получения кредита. Мы понимаем, что время играет ключевую роль, поэтому наш процесс обработки заявок максимально быстр и эффективен. В роли представителя Манибел, мы нацелены на то, чтобы помочь каждому клиенту преодолеть свои денежные трудности, предложив ясные и выгодные условия займа. Доверьтесь нашей компании, и мы решим ваши финансовые проблемы.
Intro
betvisa vietnam
Betvisa vietnam | Grand Prize Breakout!
Betway Highlights | 499,000 Extra Bonus on betvisa com!
Cockfight to win up to 3,888,000 on betvisa game
Daily Deposit, Sunday Bonus on betvisa app 888,000!
#betvisavietnam
200% Bonus on instant deposits—start your win streak!
200% welcome bonus! Slots and Fishing Games
https://www.betvisa.com/
#betvisavietnam #betvisagame #betvisaapp
#betvisacom #betvisacasinoapp
Birthday bash? Up to 1,800,000 in prizes! Enjoy!
Friday Shopping Frenzy betvisa vietnam 100,000 VND!
Betvisa Casino App Daily Login 12% Bonus Up to 1,500,000VND!
Khám phá Thế Giới Cá Cược Trực Tuyến với BetVisa!
Hệ thống BetVisa, một trong những công ty hàng đầu tại châu Á, ra đời vào năm 2017 và thao tác dưới bằng của Curacao, đã có hơn 2 triệu người dùng trên toàn thế giới. Với lời hứa đem đến trải nghiệm cá cược đảm bảo và tin cậy nhất, BetVisa nhanh chóng trở thành lựa chọn hàng đầu của người chơi trực tuyến.
BetVisa không dừng lại ở việc cung cấp các trò chơi phong phú như xổ số, sòng bạc trực tiếp, thể thao trực tiếp và thể thao điện tử, mà còn mang đến cho người chơi những ưu đãi hấp dẫn. Thành viên mới đăng ký sẽ được tặng ngay 5 vòng quay miễn phí và có cơ hội giành giải thưởng lớn.
Đặc biệt, BetVisa hỗ trợ nhiều phương thức thanh toán linh hoạt như Betvisa Vietnam, cùng với các ưu đãi độc quyền như thưởng chào mừng lên đến 200%. Bên cạnh đó, hàng tuần còn có các chương trình khuyến mãi độc đáo như chương trình giải thưởng Sinh Nhật và Chủ Nhật Mua Sắm Điên Cuồng, mang đến cho người chơi cơ hội thắng lớn.
Nhờ vào lời hứa về trải nghiệm cá cược hoàn hảo nhất và dịch vụ khách hàng chuyên trách, BetVisa tự tin là điểm đến lý tưởng cho những ai phấn khích trò chơi trực tuyến. Hãy ghi danh ngay hôm nay và bắt đầu cuộc hành trình của bạn tại BetVisa – nơi niềm vui và may mắn chính là điều không thể thiếu.
апостиль в новосибирске
В настоящей экономической обстановке, где неожиданные финансовые обязательства могут возникнуть в любое время, поиск надежного и удобного источника финансовой помощи становится все более критическим. Предложение займ на карту предлагает возможность рассчитывать на быстрое и беззаботное получение необходимых средств без лишних трудностей. Мы ценим ваше время и обеспечиваем оперативную обработку всех запросов. В качестве вашего финансового партнера, наша главная задача состоит в том, чтобы помочь вам преодолеть текущие финансовые препятствия, предоставляя ясные и выгодные условия кредитования. Доверьтесь нам в вашем финансовом путешествии, и мы обеспечим вас надежной поддержкой на каждом этапе.
prednisone 5 mg cheapest prednisone 500 mg tablet prednisone 10mg
В настоящей экономической обстановке, где неожиданные финансовые обязательства могут возникнуть в любое время, поиск надежного и удобного источника финансовой помощи становится все более критическим. Предложение zaim-minsk.ru предлагает возможность рассчитывать на быстрое и беззаботное получение необходимых средств без лишних трудностей. Мы ценим ваше время и обеспечиваем оперативную обработку всех запросов. В качестве вашего финансового партнера, наша главная задача состоит в том, чтобы помочь вам преодолеть текущие финансовые препятствия, предоставляя ясные и выгодные условия кредитования. Доверьтесь нам в вашем финансовом путешествии, и мы обеспечим вас надежной поддержкой на каждом этапе.
Intro
betvisa bangladesh
Betvisa bangladesh | Super Cricket Carnival with Betvisa!
IPL Cricket Mania | Kick off Super Cricket Carnival with bet visa.com
IPL Season | Exclusive 1,50,00,000 only at Betvisa Bangladesh!
Crash Games Heroes | Climb to the top of the 1,00,00,000 bonus pool!
#betvisabangladesh
Preview IPL T20 | Follow Betvisa BD on Facebook, Instagram for awards!
betvisa affiliate Dream Maltese Tour | Sign up now to win the ultimate prize!
https://www.bvthethao.com/
#betvisabangladesh #betvisabd #betvisaaffiliate
#betvisaaffiliatesignup #betvisa.com
Nhờ vào lời hứa về kinh nghiệm cá cược tốt nhất và dịch vụ khách hàng chuyên môn, BetVisa tự hào là điểm đến lý tưởng cho những ai phấn khích trò chơi trực tuyến. Hãy gắn bó ngay hôm nay và bắt đầu cuộc hành trình của bạn tại BetVisa – nơi niềm vui và may mắn chính là điều tất yếu.
Khám phá Thế Giới Cá Cược Trực Tuyến với BetVisa!
Dịch vụ BetVisa, một trong những công ty trò chơi hàng đầu tại châu Á, ra đời vào năm 2017 và hoạt động dưới phê chuẩn của Curacao, đã thu hút hơn 2 triệu người dùng trên toàn thế giới. Với lời hứa đem đến trải nghiệm cá cược an toàn và tin cậy nhất, BetVisa sớm trở thành lựa chọn hàng đầu của người chơi trực tuyến.
BetVisa không chỉ cung cấp các trò chơi phong phú như xổ số, sòng bạc trực tiếp, thể thao trực tiếp và thể thao điện tử, mà còn mang đến cho người chơi những ưu đãi hấp dẫn. Thành viên mới đăng ký sẽ được tặng ngay 5 cơ hội miễn phí và có cơ hội giành giải thưởng lớn.
Đặc biệt, BetVisa hỗ trợ nhiều hình thức thanh toán linh hoạt như Betvisa Vietnam, cùng với các ưu đãi độc quyền như thưởng chào mừng lên đến 200%. Bên cạnh đó, hàng tuần còn có các chương trình khuyến mãi độc đáo như chương trình giải thưởng Sinh Nhật và Chủ Nhật Mua Sắm Điên Cuồng, mang đến cho người chơi cơ hội thắng lớn.
В настоящей экономической обстановке, где неожиданные финансовые обязательства могут возникнуть в любое время, поиск надежного и удобного источника финансовой помощи становится все более критическим. Предложение займ на карту предлагает возможность рассчитывать на быстрое и беззаботное получение необходимых средств без лишних трудностей. Мы ценим ваше время и обеспечиваем оперативную обработку всех запросов. В качестве вашего финансового партнера, наша главная задача состоит в том, чтобы помочь вам преодолеть текущие финансовые препятствия, предоставляя ясные и выгодные условия кредитования. Доверьтесь нам в вашем финансовом путешествии, и мы обеспечим вас надежной поддержкой на каждом этапе.
JDB online
JDB online | 2024 best online slot game demo cash
How to earn reels? jdb online accumulate spin get bonus
Hot demo fun: Quick earn bonus for ranking demo
JDB demo for win? JDB reward can be exchanged to real cash
#jdbonline
777 sign up and get free 2,000 cash: https://www.jdb777.io/
#jdbonline #democash #demofun #777signup
#rankingdemo #demoforwin
2000 cash: Enter email to verify, enter verify, claim jdb bonus
Play with JDB games an online platform in every countries.
Enjoy the Pleasure of Gaming!
Costless to Join, Complimentary to Play.
Enroll and Get a Bonus!
JOIN NOW AND OBTAIN 2000?
We dare you to obtain a sample entertaining welcome bonus for all new members! Plus, there are other particular promotions waiting for you!
Discover more
JDB – FREE TO JOIN
Effortless to play, real profit
Engage in JDB today and indulge in fantastic games without any investment! With a wide array of free games, you can savor pure entertainment at any time.
Speedy play, quick join
Value your time and opt for JDB’s swift games. Just a few easy steps and you’re set for an amazing gaming experience!
Sign Up now and generate money
Experience JDB: Instant play with no investment and the opportunity to win cash. Designed for effortless and lucrative play.
Submerge into the World of Online Gaming Adventure with Fun Slots Online!
Are you set to experience the thrill of online gaming like never before? Scour no further than Fun Slots Online, your ultimate hub for exhilarating gameplay, endless entertainment, and stimulating winning opportunities!
At Fun Slots Online, we take pride ourselves on providing a wide array of engaging games designed to keep you engaged and amused for hours on end. From classic slot machines to innovative new releases, there’s something for everybody to appreciate. Plus, with our user-friendly interface and effortless gameplay experience, you’ll have no problem diving straight into the thrill and savoring every moment.
But that’s not all – we also present a selection of unique promotions and bonuses to honor our loyal players. From welcome bonuses for new members to privileged rewards for our top players, there’s always something exciting happening at Fun Slots Online. And with our secure payment system and 24-hour customer support, you can experience peace of mind cognizant that you’re in good hands every step of the way.
So why wait? Register with Fun Slots Online today and initiate your journey towards heart-pounding victories and jaw-dropping prizes. Whether you’re a seasoned gamer or just starting out, there’s never been a better time to join the fun and thrills at Fun Slots Online. Sign up now and let the games begin!
В настоящей экономической обстановке, где неожиданные финансовые обязательства могут возникнуть в любое время, поиск надежного и удобного источника финансовой помощи становится все более критическим. Предложение деньги в долг предлагает возможность рассчитывать на быстрое и беззаботное получение необходимых средств без лишних трудностей. Мы ценим ваше время и обеспечиваем оперативную обработку всех запросов. В качестве вашего финансового партнера, наша главная задача состоит в том, чтобы помочь вам преодолеть текущие финансовые препятствия, предоставляя ясные и выгодные условия кредитования. Доверьтесь нам в вашем финансовом путешествии, и мы обеспечим вас надежной поддержкой на каждом этапе.
can i buy cheap clomid without prescription: cost clomid pills – can you buy clomid without a prescription
cost cheap clomid pills get clomid buy clomid
В настоящее время наши дни могут содержать внезапные издержки и финансовые вызовы, и в такие моменты каждый ищет надежную поддержку. На сайте деньги в долг вам помогут без избыточной бюрократии. В своей роли агента я стремлюсь поделиться этими сведениями, чтобы помочь тем, кто столкнулся с временными трудностями. Наша платформа обеспечивает прозрачные условия и быструю обработку заявок, чтобы каждый мог разрешить свои финансовые вопросы оперативно и без лишних затрат времени.
В настоящее время наши дни могут содержать внезапные издержки и финансовые вызовы, и в такие моменты каждый ищет помощь. На сайте деньги в долг в Минске срочно вам помогут без лишних сложностей. В своей роли представителя я стремлюсь распространить эту информацию, чтобы помочь тем, кто столкнулся с временными трудностями. Наша система обеспечивает прозрачные условия и быструю обработку заявок, чтобы каждый мог решить свои денежные проблемы быстро и без лишних хлопот.
price for 15 prednisone: order prednisone with mastercard debit – prednisone 12 mg
В настоящее время наши дни могут содержать внезапные издержки и экономические трудности, и в такие моменты каждый ищет надежную поддержку. На сайте займы онлайн на карту вам помогут без избыточной бюрократии. В своей роли агента я стремлюсь распространить эту информацию, чтобы помочь людям в сложной ситуации. Наша платформа обеспечивает честные условия и быструю обработку заявок, чтобы каждый мог решить свои денежные проблемы оперативно и без лишних затрат времени.
В настоящее время наши дни могут содержать внезапные издержки и экономические трудности, и в такие моменты каждый ищет надежную поддержку. На сайте деньги в долг в Минске вам помогут без лишних сложностей. В своей роли представителя я стремлюсь поделиться этими сведениями, чтобы помочь людям в сложной ситуации. Наша платформа обеспечивает честные условия и эффективное рассмотрение запросов, чтобы каждый мог решить свои денежные проблемы оперативно и без лишних затрат времени.
buy oral ivermectin: stromectol uk buy – ivermectin 20 mg
https://prednisonea.store/# prednisone 20mg tablets where to buy
В наше время многие из нас сталкиваются с непредвиденными расходами и денежными трудностями, и в такие моменты важно иметь доступ к дополнительным средствам. На сайте ДеньгиЗаймы вам помогут быстро и удобно. В качестве официального представителя Брокерс Групп, я с удовольствием делиться этой информацией, чтобы помочь людям, кто столкнулся с финансовыми трудностями. Наша система гарантирует честные условия и быструю обработку заявок, чтобы каждый мог разрешить свои денежные проблемы с минимальными временными затратами.
robot88
how to buy generic clomid cost of generic clomid where can i get clomid no prescription
В наше время многие из нас сталкиваются с непредвиденными расходами и экономическими вызовами, и в такие моменты важно иметь возможность взять кредит. На сайте деньги в долг вам помогут с минимальными усилиями. В качестве официального представителя Брокерс Групп, я с удовольствием делиться этой важной информацией, чтобы помочь людям, кто столкнулся с финансовыми трудностями. Наша система гарантирует прозрачные условия и быструю обработку заявок, чтобы каждый мог решить свои финансовые вопросы быстро и эффективно.
where to buy zithromax in canada: zithromax antibiotic without prescription – can i buy zithromax over the counter
В наше время многие из нас сталкиваются с внезапными затратами и экономическими вызовами, и в такие моменты важно иметь возможность взять кредит. На сайте деньги в долг на карту вам помогут с минимальными усилиями. В качестве официального представителя Брокерс Групп, я рад делиться этой важной информацией, чтобы помочь людям, кто нуждается в финансовой поддержке. Наша система гарантирует честные условия и оперативное рассмотрение запросов, чтобы каждый мог разрешить свои денежные проблемы с минимальными временными затратами.
В наше время многие из нас сталкиваются с непредвиденными расходами и денежными трудностями, и в такие моменты важно иметь возможность взять кредит. На сайте займ денег минск вам помогут с минимальными усилиями. В качестве официального представителя Брокерс Групп, я рад делиться этой информацией, чтобы помочь людям, кто нуждается в финансовой поддержке. Наша платформа гарантирует прозрачные условия и оперативное рассмотрение запросов, чтобы каждый мог разрешить свои денежные проблемы быстро и эффективно.
http://amoxicillina.top/# amoxicillin without a prescription
Intro
betvisa india
Betvisa india | IPL 2024 Heat Wave
IPL 2024 Big bets, big prizes With Betvisa India
Exclusive for Sports Fans Betvisa Online Casino 50% Welcome Bonus
Crash Game Supreme Compete for 1,00,00,000 pot Betvisa.com
#betvisaindia
Accurate Predictions IPL T20 Tournament, Winner Takes All!
More than just a game | Betvisa dreams invites you to fly to malta
https://www.b3tvisapro.com/
#betvisaindia #betvisalogin #betvisaonlinecasino
#betvisa.com #betvisaapp
D?ch v? – Di?m D?n Tuy?t V?i Cho Ngu?i Choi Tr?c Tuy?n
Kham Pha Th? Gi?i Ca Cu?c Tr?c Tuy?n v?i BetVisa!
BetVisa du?c thi?t l?p vao nam 2017 va v?n hanh theo ch?ng ch? tro choi Curacao v?i hon 2 tri?u ngu?i dung. V?i tinh cam k?t dem d?n tr?i nghi?m ca cu?c an toan va tin c?y nh?t, BetVisa nhanh chong tr? thanh l?a ch?n hang d?u c?a ngu?i choi tr?c tuy?n.
N?n t?ng ca cu?c khong ch? cung c?p cac tro choi phong phu nhu x? s?, song b?c tr?c ti?p, th? thao tr?c ti?p va th? thao di?n t?, ma con mang l?i cho ngu?i choi nh?ng ph?n thu?ng h?p d?n. Thanh vien m?i dang ky s? du?c t?ng ngay 5 vong quay mi?n phi va co co h?i gianh gi?i thu?ng l?n.
N?n t?ng ca cu?c h? tr? nhi?u phuong th?c thanh toan linh ho?t nhu Betvisa Vietnam, k?t h?p v?i cac uu dai d?c quy?n nhu thu?ng chao m?ng len d?n 200%. Ben c?nh do, hang tu?n con co cac chuong trinh khuy?n mai d?c dao nhu chuong trinh gi?i thu?ng Sinh Nh?t va Ch? Nh?t Mua S?m Dien Cu?ng, mang l?i cho ngu?i choi co h?i th?ng l?n.
V?i tinh cam k?t v? tr?i nghi?m ca cu?c t?t nh?t va d?ch v? khach hang t?n tam, BetVisa t? tin la di?m d?n ly tu?ng cho nh?ng ai dam me tro choi tr?c tuy?n. Hay dang ky ngay hom nay va b?t d?u hanh trinh c?a b?n t?i BetVisa – noi ni?m vui va may m?n chinh la di?u t?t y?u!
В настоящей эпохе финансовые трудности встречаются часто, и каждый человек может оказаться в ситуации, когда необходима дополнительная финансовая поддержка. На сайте взять деньги в кредит помогут решить эти проблемы, предоставляя простой и удобный способ получения кредита. Мы осознаём, что время играет ключевую роль, поэтому наш процесс обработки заявок максимально быстр и эффективен. В роли представителя Манибел, наша цель – помочь каждому клиенту преодолеть финансовые затруднения, предоставив прозрачные и выгодные условия кредитования. Доверьтесь нам, и мы поможем вам в решении ваших финансовых проблем.
40 mg daily prednisone: prednisone brand name india – can you buy prednisone in canada
В сегодняшнем обществе финансовые сложности встречаются часто, и каждый человек может оказаться в ситуации, когда необходима дополнительная финансовая поддержка. На сайте МаниБел помогут преодолеть эти трудности, принося простой и удобный способ получения кредита. Мы осознаём, что время играет ключевую роль, поэтому наш процесс обработки заявок максимально быстр и эффективен. В качестве представителя Манибел, мы нацелены на то, чтобы помочь каждому клиенту преодолеть свои денежные трудности, предоставив прозрачные и выгодные условия кредитования. Доверьтесь нашей компании, и мы поможем вам в решении ваших финансовых проблем.
перевод документов
В настоящей эпохе финансовые трудности не редкость, и каждый из нас может оказаться в ситуации, когда необходима дополнительная финансовая поддержка. На сайте взять денег в долг срочно помогут решить эти проблемы, принося простой и лёгкий метод займа. Мы осознаём, что время играет ключевую роль, поэтому наш процесс обработки заявок максимально быстр и эффективен. В качестве представителя Манибел, мы нацелены на то, чтобы помочь каждому клиенту преодолеть свои денежные трудности, предоставив прозрачные и выгодные условия кредитования. Доверьтесь нам, и мы поможем вам в решении ваших финансовых проблем.
can you buy generic clomid without prescription generic clomid without a prescription where can i buy clomid pills
В настоящей эпохе финансовые сложности встречаются часто, и каждый человек может оказаться в ситуации, когда потребуется дополнительная финансовая помощь. На сайте деньги в долг помогут решить эти проблемы, предоставляя простой и лёгкий метод займа. Мы понимаем, что время играет ключевую роль, поэтому наш процесс обработки заявок максимально быстр и эффективен. В качестве представителя Манибел, мы нацелены на то, чтобы помочь каждому клиенту преодолеть свои денежные трудности, предоставив прозрачные и выгодные условия кредитования. Доверьтесь нашей компании, и мы решим ваши финансовые проблемы.
http://amoxicillina.top/# 875 mg amoxicillin cost
prednisone 50 mg coupon: pharmacy cost of prednisone – prednisone pills for sale
В настоящей экономической обстановке, где неожиданные финансовые обязательства могут возникнуть в любое время, поиск надежного и удобного источника финансовой помощи становится все более критическим. Предложение получить займ предлагает возможность рассчитывать на быстрое и беззаботное получение необходимых средств без лишних трудностей. Мы ценим ваше время и обеспечиваем оперативную обработку всех запросов. В качестве вашего финансового партнера, наша главная задача состоит в том, чтобы помочь вам преодолеть текущие финансовые препятствия, предоставляя ясные и выгодные условия кредитования. Доверьтесь нам в вашем финансовом путешествии, и мы обеспечим вас надежной поддержкой на каждом этапе.
В настоящей экономической обстановке, где неожиданные финансовые обязательства могут возникнуть в любое время, поиск надежного и удобного источника финансовой помощи становится все более критическим. Предложение взять деньги предлагает возможность рассчитывать на быстрое и беззаботное получение необходимых средств без лишних трудностей. Мы ценим ваше время и обеспечиваем оперативную обработку всех запросов. В качестве вашего финансового партнера, наша главная задача состоит в том, чтобы помочь вам преодолеть текущие финансовые препятствия, предоставляя ясные и выгодные условия кредитования. Доверьтесь нам в вашем финансовом путешествии, и мы обеспечим вас надежной поддержкой на каждом этапе.
В настоящей экономической обстановке, где неожиданные финансовые обязательства могут возникнуть в любое время, поиск надежного и удобного источника финансовой помощи становится все более критическим. Предложение займ в Минске предлагает возможность рассчитывать на быстрое и беззаботное получение необходимых средств без лишних трудностей. Мы ценим ваше время и обеспечиваем оперативную обработку всех запросов. В качестве вашего финансового партнера, наша главная задача состоит в том, чтобы помочь вам преодолеть текущие финансовые препятствия, предоставляя ясные и выгодные условия кредитования. Доверьтесь нам в вашем финансовом путешествии, и мы обеспечим вас надежной поддержкой на каждом этапе.
В настоящей экономической обстановке, где неожиданные финансовые обязательства могут возникнуть в любое время, поиск надежного и удобного источника финансовой помощи становится все более критическим. Предложение деньги в долг предлагает возможность рассчитывать на быстрое и беззаботное получение необходимых средств без лишних трудностей. Мы ценим ваше время и обеспечиваем оперативную обработку всех запросов. В качестве вашего финансового партнера, наша главная задача состоит в том, чтобы помочь вам преодолеть текущие финансовые препятствия, предоставляя ясные и выгодные условия кредитования. Доверьтесь нам в вашем финансовом путешествии, и мы обеспечим вас надежной поддержкой на каждом этапе.
cheap amoxicillin 500mg buying amoxicillin in mexico amoxicillin 500mg price
prednisone rx coupon: 5 mg prednisone daily – prednisone 10 mg canada
http://azithromycina.pro/# zithromax 500 mg lowest price pharmacy online
Внимание, любители ставок! БК Олимп представляет с гордостью последнюю версию своего приложения для Android, которое обещает изменить ваш мир ставок на радость. Мы обновили приложение, чтобы гарантировать несравненный опыт от ставок на спорт. Приложение Olimp на андроид и откройте просмотр разнообразных спортивных событий, который стал удобнее благодаря новому дизайну и ускоренной обработке данных. Присоединяйтесь к сообществу БК Олимп и пользуйтесь возможностью делать ставки в любой точке мира, будь то на диване или в путешествии. Получите это обновление приложения без задержек и погрузитесь в мир ставок с БК Олимп, где выигрыши становятся реальностью!
synthroid protocol
Внимание, любители ставок! БК Олимп представляет с гордостью последнюю версию своего приложения для Android, которое обещает изменить ваш мир ставок на радость. Мы обновили приложение, чтобы гарантировать несравненный опыт от ставок на спорт. Загрузить файл apk Olimp и откройте доступ к широкому спектру спортивных событий, который стал проще благодаря новому дизайну и ускоренной обработке данных. Присоединяйтесь к сообществу БК Олимп и наслаждайтесь возможностью делать ставки где угодно, будь то дома или в отпуске. Загрузите новую версию приложения без задержек и погрузитесь в мир ставок с БК Олимп, где победы становятся реальностью!
can sitagliptin cause diarrhea
Внимание, любители ставок! БК Олимп представляет с гордостью новейшую версию своего приложения для Android, которое обещает перевернуть ваш мир ставок на радость. Мы обновили приложение, чтобы гарантировать несравненный впечатление от ставок на спорт. БК Олимп для андроид и откройте доступ к широкому спектру спортивных событий, который стал удобнее благодаря улучшенному интерфейсу и ускоренной обработке данных. Подключайтесь к нам и пользуйтесь возможностью делать ставки в любой точке мира, будь то дома или в отпуске. Получите это обновление приложения без задержек и откройте для себя мир ставок с БК Олимп, где победы становятся реальностью!
Внимание, любители ставок! БК Олимп представляет с гордостью последнюю версию своего приложения для Android, которое обещает изменить ваш мир ставок к лучшему. Мы обновили приложение, чтобы гарантировать несравненный опыт от ставок на спорт. Скачать апк файл Олимп Бет и откройте доступ к широкому спектру спортивных событий, который стал проще благодаря новому дизайну и оптимизированной производительности данных. Подключайтесь к нам и пользуйтесь возможностью делать ставки где угодно, будь то на диване или в отпуске. Загрузите это обновление приложения прямо сейчас и откройте для себя мир ставок с БК Олимп, где победы становятся реальностью!
JDB demo
JDB demo | The easiest bet software to use (jdb games)
JDB bet marketing: The first bonus that players care about
Most popular player bonus: Daily Play 2000 Rewards
Game developers online who are always with you
#jdbdemo
Where to find the best game developer? https://www.jdbgaming.com/
#gamedeveloperonline #betsoftware #betmarketing
#developerbet #betingsoftware #gamedeveloper
Supports hot jdb demo beting software jdb angry bird
JDB slot demo supports various competition plans
Opening Achievement with JDB Gaming: Your Ultimate Bet Software Resolution
In the universe of online gaming, finding the correct wager software is vital for success. Introducing JDB Gaming – a premier supplier of innovative gaming solutions tailored to boost the player experience and propel revenue for operators. With a concentration on easy-to-use interfaces, enticing bonuses, and a varied selection of games, JDB Gaming stands out as a leading choice for both players and operators alike.
JDB Demo presents a glimpse into the realm of JDB Gaming, giving players with an opportunity to feel the excitement of betting without any risk. With user-friendly interfaces and seamless navigation, JDB Demo enables it straightforward for players to explore the extensive selection of games on offer, from classic slots to immersive arcade titles.
When it regards bonuses, JDB Bet Marketing is at the forefront with appealing offers that draw players and keep them coming back for more. From the favored Daily Play 2000 Rewards to special promotions, JDB Bet Marketing guarantees that players are recognized for their faithfulness and dedication.
With so several game developers online, finding the best can be a challenging task. However, JDB Gaming emerges from the pack with its commitment to excellence and innovation. With over 150 online casino games to select, JDB Gaming offers something special for every player, whether you’re a fan of slots, fish shooting games, arcade titles, card games, or bingo.
At the center of JDB Gaming lies a dedication to providing the finest possible gaming experience for players. With a focus on Asian culture and impressive 3D animations, JDB Gaming stands out as a pioneer in the industry. Whether you’re a gamer in search of excitement or an provider in need of a dependable partner, JDB Gaming has you covered.
API Integration: Effortlessly link with all platforms for ultimate business opportunities. Big Data Analysis: Keep ahead of market trends and understand player habits with extensive data analysis. 24/7 Technical Support: Experience peace of mind with professional and dependable technical support on hand around the clock.
In conclusion, JDB Gaming offers a victorious combination of advanced technology, appealing bonuses, and unequaled support. Whether you’re a gamer or an provider, JDB Gaming has everything you need to excel in the world of online gaming. So why wait? Join the JDB Gaming family today and unlock your full potential!
prednisone over the counter south africa: 50mg prednisone tablet – buy prednisone canadian pharmacy
Вот оно, свежее веяние от БК Олимп для всех энтузиастов ставок с Android устройствами! Преобразив наше приложение, мы стремимся предоставить вам уникальный опыт, делая ставки не только простыми, но и захватывающими. Скачать на андроид букмекерскую Олимп доступно сегодня! С новым дизайном и ускоренной производительностью, доступ к огромному спектру событий стал проще простого. Испытайте радость от оптимизированной работы с аккаунтом и интуитивной навигации, которые делают каждую ставку особым событием. Забудьте о пропущенных возможностях – скачайте последнее обновление сейчас же и присоединитесь к довольных пользователей, радующихся каждой ставке с БК Олимп, где каждый шанс на победу ценится.
Вот оно, свежее веяние от БК Олимп для всех энтузиастов ставок с Android устройствами! Преобразив наше приложение, мы стремимся предоставить вам непревзойденный опыт, делая ставки не только удобными, но и захватывающими. Olimp bet приложение доступно сейчас! С новым дизайном и ускоренной производительностью, доступ к огромному спектру событий стал проще простого. Испытайте радость от улучшенного управления счетом и интуитивной навигации, которые делают каждую ставку волнующим моментом. Забудьте о пропущенных возможностях – скачайте последнее обновление немедленно и вступите в ряды довольных пользователей, празднующих каждой ставке с БК Олимп, где каждый шанс на победу ценится.
zithromax generic price: zithromax 250 mg tablet price – generic zithromax medicine
https://amoxicillina.top/# amoxicillin without rx
Вот оно, свежее веяние от БК Олимп для всех энтузиастов ставок с Android устройствами! Изменив наше приложение, мы целимся предоставить вам уникальный опыт, делая ставки не только простыми, но и захватывающими. Скачать приложение Олимп бет доступное для игроков! С улучшенным интерфейсом и быстрой обработкой данных, доступ к большому разнообразию событий стал легким делом. Ощутите радость от улучшенного управления счетом и интуитивной навигации, которые делают каждую ставку волнующим моментом. Забудьте о пропущенных возможностях – установите последнее обновление немедленно и присоединитесь к довольных пользователей, радующихся каждой ставке с БК Олимп, где каждый шанс на победу высоко оценивается.
http://stromectola.top/# stromectol for sale
Intro
betvisa vietnam
Betvisa vietnam | Grand Prize Breakout!
Betway Highlights | 499,000 Extra Bonus on betvisa com!
Cockfight to win up to 3,888,000 on betvisa game
Daily Deposit, Sunday Bonus on betvisa app 888,000!
#betvisavietnam
200% Bonus on instant deposits—start your win streak!
200% welcome bonus! Slots and Fishing Games
https://www.betvisa.com/
#betvisavietnam #betvisagame #betvisaapp
#betvisacom #betvisacasinoapp
Birthday bash? Up to 1,800,000 in prizes! Enjoy!
Friday Shopping Frenzy betvisa vietnam 100,000 VND!
Betvisa Casino App Daily Login 12% Bonus Up to 1,500,000VND!
Khám phá Thế Giới Cá Cược Trực Tuyến với BetVisa!
BetVisa Vietnam, một trong những công ty hàng đầu tại châu Á, được thành lập vào năm 2017 và hoạt động dưới giấy phép của Curacao, đã thu hút hơn 2 triệu người dùng trên toàn thế giới. Với cam kết đem đến trải nghiệm cá cược đảm bảo và tin cậy nhất, BetVisa sớm trở thành lựa chọn hàng đầu của người chơi trực tuyến.
BetVisa không dừng lại ở việc cung cấp các trò chơi phong phú như xổ số, sòng bạc trực tiếp, thể thao trực tiếp và thể thao điện tử, mà còn mang đến cho người chơi những ưu đãi hấp dẫn. Thành viên mới đăng ký sẽ được tặng ngay 5 phần quà miễn phí và có cơ hội giành giải thưởng lớn.
Đặc biệt, BetVisa hỗ trợ nhiều cách thức thanh toán linh hoạt như Betvisa Vietnam, cùng với các ưu đãi độc quyền như thưởng chào mừng lên đến 200%. Bên cạnh đó, hàng tuần còn có các chương trình khuyến mãi độc đáo như chương trình giải thưởng Sinh Nhật và Chủ Nhật Mua Sắm Điên Cuồng, mang đến cho người chơi cơ hội thắng lớn.
Với tính cam kết về trải thảo cá cược tốt nhất và dịch vụ khách hàng chuyên trách, BetVisa tự hào là điểm đến lý tưởng cho những ai nhiệt huyết trò chơi trực tuyến. Hãy đăng ký ngay hôm nay và bắt đầu chuyến đi của bạn tại BetVisa – nơi niềm vui và may mắn chính là điều quan trọng.
how does spironolactone work
prednisone 10 mg prednisone 5 mg brand name prednisone 2 mg
http://medicationnoprescription.pro/# cheap drugs no prescription
Не пропустите новинку от БК Олимп для Android! Скачать Олимп бесплатно уже сегодня. Мы обновили наше приложение, чтобы ваш опыт ставок стал ещё лучше. С переработанным дизайном и ускоренной обработкой данных, вы получите доступ к широкому ассортименту спортивных событий без усилий. Оцените удобством ведения счета и интуитивной навигацией, делая каждую ставку особым моментом. Установите это приложение сегодня и начните выигрывать с БК Олимп, где каждая ставка приносит удовольствие!
Не пропустите обновление от БК Олимп для Android! Приложение букмекерской конторы Олимп уже сегодня. Мы обновили наше приложение, чтобы ваш опыт ставок стал ещё удобнее. С переработанным дизайном и повышенной скоростью, вы получите доступ к многообразию спортивных событий без усилий. Оцените простотой управления аккаунтом и лёгкостью использования, делая каждую ставку особым моментом. Загрузите это обновление сегодня и стартуйте побеждать с БК Олимп, где каждая ставка приносит радость!
Не пропустите обновление от БК Олимп для Android! Olimp для андроид доступное для игроков. Мы пересмотрели наше приложение, чтобы ваш опыт ставок стал ещё удобнее. С новым интерфейсом и повышенной скоростью, вы получите доступ к широкому ассортименту спортивных событий без усилий. Оцените удобством ведения счета и интуитивной навигацией, делая каждую ставку особым моментом. Установите это приложение прямо сейчас и стартуйте побеждать с БК Олимп, где каждая ставка приносит радость!
JDBslot
JDB slot | The first bonus to rock the slot world
Exclusive event to earn real money and slot game points
JDB demo slot games for free = ?? Lucky Spin Lucky Draw!
How to earn reels free 2000? follow jdb slot games for free
#jdbslot
Demo making money : https://jdb777.com
#jdbslot #slotgamesforfree #howtoearnreels #cashreels
#slotgamepoint #demomakingmoney
Cash reels only at slot games for free
More professional jdb game bonus knowledge
Ways to Acquire Spins Credit Gratis 2000: Your Supreme Instruction to Victorious Big with JDB Slots
Are you prepared to embark on an thrilling expedition into the universe of online slot games? Search no more, only spin to JDB777 FreeGames, where thrills and big wins expect you at each spin of the reel. In this all-encompassing handbook, we’ll reveal you how to secure reels points gratis 2000 and open the thrilling world of JDB slots.
Live through the Adrenaline rush of Machine Games for Free
At JDB777 FreeGames, we supply a broad choice of captivating slot games that are positive to keep you entertained for hours on end. From vintage fruit machines to immersive themed slots, there’s something for every type of player to enjoy. And the greatest part? You can play all of our slot games for free and achieve real cash prizes!
Unlock Free Cash Reels and Attain Big
One of the most thrilling features of JDB777 FreeGames is the option to earn reels credit costless 2000, which can be exchanged for real cash. Plainly sign up for an account, and you’ll receive your gratis bonus to start spinning and winning. With our generous promotions and bonuses, the sky’s the ceiling when it comes to your winnings!
Steer Strategies and Points System
To maximize your winnings and uncover the full potential of our slot games, it’s essential to apprehend the strategies and points system. Our skilled guides will take you through everything you require to know, from picking the right games to understanding how to acquire bonus points and cash prizes.
Exclusive Promotions and Exclusive Offers
As a member of JDB777 FreeGames, you’ll have access to exclusive promotions and special offers that are positive to boost your gaming experience. From welcome bonuses to daily rebates, there are a lot of possibilities to enhance your winnings and take your gameplay to the next level.
Join Us Today and Begin Winning
Don’t miss out on your opportunity to win big with JDB777 FreeGames. Sign up now to declare your costless bonus of 2000 credits and start spinning the reels for your opportunity to win real cash prizes. With our thrilling choice of slot games and generous promotions, the possibilities are endless. Join us today and start winning!
Не пропустите новинку от БК Олимп для Android! Olimp bet на андроид доступно сейчас. Мы обновили наше приложение, чтобы ваш опыт ставок стал ещё лучше. С переработанным дизайном и ускоренной обработкой данных, вы получите доступ к широкому ассортименту спортивных событий без усилий. Наслаждайтесь удобством ведения счета и лёгкостью использования, делая каждую ставку значимым событием. Установите это обновление сегодня и стартуйте выигрывать с БК Олимп, где каждая ставка приносит радость!
low cost ed meds: online ed pharmacy – erectile dysfunction drugs online
Intro
betvisa india
Betvisa india | IPL 2024 Heat Wave
IPL 2024 Big bets, big prizes With Betvisa India
Exclusive for Sports Fans Betvisa Online Casino 50% Welcome Bonus
Crash Game Supreme Compete for 1,00,00,000 pot Betvisa.com
#betvisaindia
Accurate Predictions IPL T20 Tournament, Winner Takes All!
More than just a game | Betvisa dreams invites you to fly to malta
https://www.b3tvisapro.com/
#betvisaindia #betvisalogin #betvisaonlinecasino
#betvisa.com #betvisaapp
Khám phá Thế Giới Cá Cược Trực Tuyến với BetVisa!
BetVisa Vietnam, một trong những công ty hàng đầu tại châu Á, được thành lập vào năm 2017 và hoạt động dưới phê chuẩn của Curacao, đã thu hút hơn 2 triệu người dùng trên toàn thế giới. Với cam kết đem đến trải nghiệm cá cược an toàn và tin cậy nhất, BetVisa sớm trở thành lựa chọn hàng đầu của người chơi trực tuyến.
BetVisa không dừng lại ở việc cung cấp các trò chơi phong phú như xổ số, sòng bạc trực tiếp, thể thao trực tiếp và thể thao điện tử, mà còn mang đến cho người chơi những ưu đãi hấp dẫn. Thành viên mới đăng ký sẽ được tặng ngay 5 cơ hội miễn phí và có cơ hội giành giải thưởng lớn.
Đặc biệt, BetVisa hỗ trợ nhiều phương thức thanh toán linh hoạt như Betvisa Vietnam, cùng với các ưu đãi độc quyền như thưởng chào mừng lên đến 200%. Bên cạnh đó, hàng tuần còn có các chương trình khuyến mãi độc đáo như chương trình giải thưởng Sinh Nhật và Chủ Nhật Mua Sắm Điên Cuồng, mang đến cho người chơi cơ hội thắng lớn.
Nhờ vào lời hứa về trải nghiệm thú vị cá cược tốt nhất và dịch vụ khách hàng chuyên nghiệp, BetVisa hoàn toàn tự hào là điểm đến lý tưởng cho những ai nhiệt tình trò chơi trực tuyến. Hãy ghi danh ngay hôm nay và bắt đầu cuộc hành trình của bạn tại BetVisa – nơi niềm vui và may mắn chính là điều tất yếu.
https://onlinepharmacyworld.shop/# offshore pharmacy no prescription
Запуск переделанной версии приложения БК Олимп для Android уже здесь! Модернизировав функционал, мы сделали процесс ставок невероятно простым. БК Олимп для андроид доступно для ставочников. С обновленным дизайном и ускоренной загрузкой данных, доступ к разнообразию спортивных событий станет легкостью. Ощутите удобство управления счетом и интуитивно понятной навигацией, превращая каждую ставку в важное событие. Не задерживайтесь, получите последнюю версию прямо сейчас и присоединяйтесь к победителям с БК Олимп, где ставки приносят наслаждение и победы!
Запуск обновленной версии приложения БК Олимп для Android уже здесь! Модернизировав функционал, мы сделали процесс ставок невероятно простым. Скачать Olimp доступно для ставочников. С передовым интерфейсом и ускоренной загрузкой данных, доступ к разнообразию спортивных событий станет легкостью. Наслаждайтесь простотой управления счетом и интуитивно понятной навигацией, превращая каждую ставку в важное событие. Не задерживайтесь, получите последнюю версию прямо сейчас и присоединяйтесь к удовлетворенным пользователям с БК Олимп, где ставки приносят наслаждение и победы!
cheapest ed online ed drugs online erectile dysfunction online
Запуск обновленной версии приложения БК Олимп для Android уже здесь! Переосмыслив функционал, мы сделали процесс ставок еще более увлекательным. Скачать приложение БК Олимп доступное для игроков. С обновленным дизайном и ускоренной загрузкой данных, доступ к всему спектру спортивных событий станет игрой. Ощутите удобство управления счетом и легкой навигацией, превращая каждую ставку в особенный момент. Не задерживайтесь, получите последнюю версию без отлагательств и присоединяйтесь к победителям с БК Олимп, где ставки приносят удовольствие и победы!
Запуск переделанной версии приложения БК Олимп для Android уже здесь! Переосмыслив функционал, мы сделали процесс ставок еще более увлекательным. Скачать бесплатно Olimp на андроид доступное для игроков. С обновленным дизайном и ускоренной загрузкой данных, доступ к всему спектру спортивных событий станет легкостью. Ощутите удобство управления счетом и легкой навигацией, превращая каждую ставку в особенный момент. Не теряйте времени, скачайте последнюю версию без отлагательств и присоединяйтесь к победителям с БК Олимп, где ставки приносят наслаждение и победы!
http://edpill.top/# online ed treatments
cheapest pharmacy to fill prescriptions with insurance: canada drugs coupon code – non prescription medicine pharmacy
cheapest ed medication: ed pills cheap – online ed prescription
Откройте для себя последние новшества в приложении БК Олимп для Android! Программа Олимп доступно сегодня. Мы улучшили наше приложение, чтобы сделать ваше взаимодействие с ставками более приятным. Благодаря усовершенствованному интерфейсу и ускоренной обработке данных, вы теперь имеете легкий доступ к широкому спектру спортивных событий. Оцените удобство использования своим аккаунтом и интуитивную навигацию, превращая каждую вашу ставку в уникальное приключение. Загрузите обновление прямо сегодня и начните зарабатывать на своих победах вместе с БК Олимп, где каждая ставка принесет успех.
Откройте для себя последние новшества в приложении БК Олимп для Android! Контора Олимп на андроид доступно сегодня. Мы улучшили наше приложение, чтобы сделать ваше взаимодействие с ставками удобным. Благодаря усовершенствованному интерфейсу и быстрой загрузке данных, вы теперь имеете легкий доступ к широкому спектру спортивных событий. Научитесь наслаждаться простоту управления своим аккаунтом и интуитивную навигацию, превращая каждую вашу ставку в значимое событие. Получите приложение прямо сегодня и начните получать удовольствие от побед вместе с БК Олимп, где каждая ставка несет радость.
http://edpill.top/# cheap ed drugs
Откройте для себя новейшие обновления в приложении БК Олимп для Android! Приложение букмекерской конторы Олимп доступно для игроков. Мы совершенствовали наше приложение, чтобы сделать ваше взаимодействие с ставками удобным. С новым дизайном и ускоренной обработке данных, вы теперь имеете легкий доступ к широкому ассортименту спортивных событий. Оцените удобство использования своим аккаунтом и легкость управления, превращая каждую вашу ставку в значимое событие. Загрузите обновление прямо сегодня и начните получать удовольствие от побед вместе с БК Олимп, где каждая ставка принесет успех.
Откройте для себя последние новшества в приложении БК Олимп для Android! Приложение букмекера Олимп доступное для игроков. Мы улучшили наше приложение, чтобы сделать ваше взаимодействие с ставками более приятным. С новым дизайном и быстрой загрузке данных, вы теперь имеете легкий доступ к широкому спектру спортивных событий. Оцените простоту управления своим аккаунтом и легкость управления, превращая каждую вашу ставку в уникальное приключение. Получите приложение прямо сегодня и начните зарабатывать на своих победах вместе с БК Олимп, где каждая ставка принесет успех.
canadian pharmacy discount code best online pharmacy no prescription canada pharmacy coupon
http://medicationnoprescription.pro/# no prescription medicine
Откройте для себя революцию в мире ставок с новейшей версией приложения БК Олимп для Android! Букмекерская контора Олимп для андроид уже сейчас. Мы освежили приложение, обеспечивая неимоверную простоту использования и быстроту загрузки. Теперь разнообразие спортивных событий находится у вас под рукой с новым дизайном и интуитивной навигацией. Прочувствуйте на себе простоту ведения финансов и сделайте каждую ставку незабываемым моментом. Установите это обновление немедленно и поднимайте свой опыт ставок с БК Олимп, где каждый выбор может принести успех!
Откройте для себя революцию в мире ставок с последним обновлением приложения БК Олимп для Android! Скачать контору Олимп на андроид сегодня и сейчас. Мы освежили приложение, обеспечивая беспрецедентный уровень удобства и быстроту загрузки. Теперь разнообразие спортивных событий находится у вас под рукой с улучшенным дизайном и интуитивной навигацией. Прочувствуйте на себе простоту ведения финансов и сделайте каждую ставку незабываемым моментом. Установите это обновление сегодня и выходите на новый уровень ставок с БК Олимп, где каждый выбор может принести успех!
canadian prescription drugstore review: canada pharmacy online no prescription – canadian prescription drugstore reviews
Pingback: ananızın amı sıkılmadınız mı
Откройте для себя новшество в мире ставок с новейшей версией приложения БК Олимп для Android! Скачать сайт Олимп прямо сейчас. Мы полностью переработали приложение, обеспечивая неимоверную простоту использования и быстроту загрузки. Теперь разнообразие спортивных событий находится у вас под рукой с улучшенным дизайном и легкой навигацией. Прочувствуйте на себе простоту ведения финансов и сделайте каждую ставку значительным событием. Загрузите это приложение сегодня и выходите на новый уровень ставок с БК Олимп, где каждый выбор может принести успех!
Откройте для себя новшество в мире ставок с новейшей версией приложения БК Олимп для Android! Скачать Olimp на андроид сегодня и сейчас. Мы полностью переработали приложение, обеспечивая неимоверную простоту использования и быстроту загрузки. Теперь разнообразие спортивных событий находится у вас под рукой с новым дизайном и легкой навигацией. Испытайте на себе легкость управления счетом и сделайте каждую ставку значительным событием. Установите это обновление сегодня и поднимайте свой опыт ставок с БК Олимп, где каждый выбор может принести успех!
After looking at a few of the blog articles on your blog, I seriously appreciate your way of
blogging. I saved it to my bookmark website list and will be
checking back soon. Take a look at my web site as well and let me
know what you think.
https://edpill.top/# affordable ed medication
Познакомьтесь с свежим обновлением приложения БК Олимп для Android, преобразующим ваш опыт в мире ставок! Скачать бесплатно Олимп бет доступны для всех ставочников. Передовой дизайн и быстрая загрузка данных гарантируют легкий доступ к множеству спортивных событий. Кастомизируйте свой аккаунт с непревзойденной легкостью и навигацией, превращая каждую ставку в волнующее приключение. Скачайте прямо сегодня и начните получать удовольствие от ставок на новом уровне с БК Олимп, где каждое событие – это шанс на выигрыш!
Познакомьтесь с новейшим обновлением приложения БК Олимп для Android, преобразующим ваш опыт в мире ставок! Скачать БК Олимп для андроид доступны для всех ставочников. Инновационный дизайн и ускоренная обработка данных гарантируют легкий доступ к множеству спортивных событий. Кастомизируйте свой аккаунт с уникальной простотой и навигацией, превращая каждую ставку в волнующее приключение. Скачайте сейчас и начните получать удовольствие от ставок на новом уровне с БК Олимп, где каждое событие – это шанс на выигрыш!
Познакомьтесь с новейшим обновлением приложения БК Олимп для Android, изменяющим ваш опыт в мире ставок! Скачать сайт Олимп доступны для всех игроков. Передовой дизайн и быстрая загрузка данных гарантируют легкий доступ к множеству спортивных событий. Настройте свой аккаунт с непревзойденной легкостью и навигацией, превращая каждую ставку в захватывающий опыт. Скачайте сейчас и начните наслаждаться от ставок на новом уровне с БК Олимп, где каждое событие – это шанс на успех!
Jeetwin Affiliate
Jeetwin Affiliate
Join Jeetwin now! | Jeetwin sign up for a ?500 free bonus
Spin & fish with Jeetwin club! | 200% welcome bonus
Bet on horse racing, get a 50% bonus! | Deposit at Jeetwin live for rewards
#JeetwinAffiliate
Casino table fun at Jeetwin casino login | 50% deposit bonus on table games
Earn Jeetwin points and credits, enhance your play!
https://www.jeetwin-affiliate.com/hi
#JeetwinAffiliate #jeetwinclub #jeetwinsignup #jeetwinresult
#jeetwinlive #jeetwinbangladesh #jeetwincasinologin
Daily recharge bonuses at Jeetwin Bangladesh!
25% recharge bonus on casino games at jeetwin result
15% bonus on Crash Games with Jeetwin affiliate!
Twist to Win Authentic Funds and Voucher Codes with JeetWin’s Referral Program
Are you a fan of internet gaming? Do you actually enjoy the thrill of rotating the roulette wheel and triumphing big-time? If so, therefore the JeetWin’s Partner Program is ideal for you! With JeetWin Casino, you not just get to partake in enthralling games but as well have the chance to make genuine currency and voucher codes simply by promoting the platform to your friends, family, or digital audience.
How Is it Operate?
Signing up for the JeetWin’s Partner Program is fast and easy. Once you transform into an associate, you’ll acquire a distinctive referral link that you can share with others. Every time someone joins or makes a deposit using your referral link, you’ll get a commission for their activity.
Fantastic Bonuses Await!
As a member of JeetWin’s affiliate program, you’ll have access to a assortment of attractive bonuses:
500 Welcome Bonus: Receive a abundant sign-up bonus of INR 500 just for joining the program.
Deposit Bonus: Get a enormous 200% bonus when you fund and play fruit machine and fish games on the platform.
Unlimited Referral Bonus: Acquire unlimited INR 200 bonuses and rebates for every friend you invite to play on JeetWin.
Exhilarating Games to Play
JeetWin offers a broad range of the most played and most popular games, including Baccarat, Dice, Liveshow, Slot, Fishing, and Sabong. Whether you’re a fan of classic casino games or prefer something more modern and interactive, JeetWin has something for everyone.
Take part in the Greatest Gaming Experience
With JeetWin Live, you can enhance your gaming experience to the next level. Participate in thrilling live games such as Lightning Roulette, Lightning Dice, Crazytime, and more. Sign up today and embark on an unforgettable gaming adventure filled with excitement and limitless opportunities to win.
Effortless Payment Methods
Depositing funds and withdrawing your winnings on JeetWin is fast and hassle-free. Choose from a variety of payment methods, including E-Wallets, Net Banking, AstroPay, and RupeeO, for seamless transactions.
Don’t Pass Up on Exclusive Promotions
As a JeetWin affiliate, you’ll gain access to exclusive promotions and special offers designed to maximize your earnings. From cash rebates to lucrative bonuses, there’s always something exciting happening at JeetWin.
Install the App
Take the fun with you wherever you go by downloading the JeetWin Mobile Casino App. Available for both iOS and Android devices, the app features a wide range of entertaining games that you can enjoy anytime, anywhere.
Become a part of the JeetWin’s Affiliate Scheme Today!
Don’t wait any longer to start earning real cash and exciting rewards with the JeetWin Affiliate Program. Sign up now and become a part of the thriving online gaming community at JeetWin.
online ed medications ed medications cost online ed drugs
Познакомьтесь с свежим обновлением приложения БК Олимп для Android, преобразующим ваш опыт в мире ставок! Олимп на андроид доступны всем игрокам. Инновационный дизайн и быстрая загрузка данных обеспечивают легкий доступ к широкому ассортименту спортивных событий. Настройте свой аккаунт с непревзойденной легкостью и навигацией, превращая каждую ставку в захватывающий опыт. Загрузите прямо сегодня и начните получать удовольствие от ставок на новом уровне с БК Олимп, где каждое событие – это шанс на успех!
rx pharmacy no prescription: online pharmacy no prescription – cheapest pharmacy to fill prescriptions without insurance
https://edpill.top/# cheap boner pills
Встречайте обновление от БК Олимп для Android, которое полностью преобразит ваш подход к ставкам! С усовершенствованным интерфейсом и оптимизированной работой, вы обретете доступ к бесконечному множеству спортивных мероприятий буквально в несколько касаний. Скачать приложение Olimp доступны для игроков. Легкое управление аккаунтом и понятная навигация сделают процесс ставок наслаждением. Не упустите возможность обновиться уже сегодня и разгадайте секреты успешных ставок с БК Олимп, где каждый ваш выбор может привести к победе!
Встречайте новинку от БК Олимп для Android, которое кардинально изменит ваш подход к ставкам! С усовершенствованным интерфейсом и ускоренной работой, вы обретете доступ к огромному количеству спортивных мероприятий буквально в несколько касаний. Olimp bet на андроид доступны для игроков. Легкое управление аккаунтом и понятная навигация сделают процесс ставок наслаждением. Не упустите возможность обновиться уже сегодня и откройте секреты успешных ставок с БК Олимп, где каждый ваш выбор может привести к успеху!
Встречайте новинку от БК Олимп для Android, которое кардинально изменит ваш подход к ставкам! С усовершенствованным интерфейсом и ускоренной работой, вы обретете доступ к бесконечному множеству спортивных мероприятий буквально в несколько касаний. Olimp на андроид доступны для всех. Легкое управление аккаунтом и понятная навигация сделают процесс ставок удовольствием. Не упустите возможность обновиться уже сегодня и разгадайте секреты успешных ставок с БК Олимп, где каждый ваш выбор может привести к успеху!
Встречайте обновление от БК Олимп для Android, которое кардинально изменит ваш подход к ставкам! С усовершенствованным интерфейсом и оптимизированной работой, вы обретете доступ к бесконечному множеству спортивных мероприятий буквально в несколько касаний. Скачать Олимп бет на андроид доступны для всех. Легкое управление аккаунтом и понятная навигация сделают процесс ставок удовольствием. Не упустите возможность обновиться уже сегодня и разгадайте секреты успешных ставок с БК Олимп, где каждый ваш выбор может привести к победе!
замена венцов
http://medicationnoprescription.pro/# canadian prescription drugstore reviews
non prescription online pharmacy india best online pharmacy without prescription legitimate online pharmacy no prescription
best online pharmacy without prescription: canada online prescription – canadian prescription drugstore review
Анонсируем выход новой версии мобильного приложения БК Лига Ставок для Android! Этот шаг полностью преобразует ваш пользовательский опыт, делая его более понятным и динамичным. Лига ставок установить на андроид для всех сейчас! В обновлении вы найдете свободу доступа к огромному ассортименту спортивных мероприятий из любой точки с помощью вашего устройства. Улучшенное управление профилем, инновационная концепция дизайна для простой навигации и увеличенная скорость работы приложения – всё это создано для вас. Присоединяйтесь к числу довольных пользователей и получайте удовольствие от ставок в любой точке планеты и в любой момент. Скачайте обновление приложения БК Лига Ставок уже сегодня и переходите к новому этапу ставок!
Рады представить запуск обновленной мобильного приложения БК Лига Ставок для Android! Этот шаг существенно улучшает ваш пользовательский опыт, делая его ещё удобнее и динамичным. Мобильное приложение лига ставок на андроид для игроков без исключения! В обновлении вы найдете прямой доступ к огромному ассортименту спортивных мероприятий прямо с вашего смартфона. Усовершенствованное управление профилем, инновационная концепция дизайна для удобной навигации и значительно более высокая скорость работы приложения – всё это создано для вас. Станьте частью воодушевленных пользователей и получайте удовольствие от ставок в любой точке планеты и в любой момент. Скачайте обновление приложения БК Лига Ставок уже сегодня и выходите на новый уровень ставок!
Рады представить запуск новой версии мобильного приложения БК Лига Ставок для Android! Этот шаг существенно улучшает ваш досуг с ставками, делая его ещё удобнее и динамичным. Лига ставок скачать приложение на телефон бесплатно сейчас же! В обновлении вы найдете свободу доступа к многообразию спортивных мероприятий из любой точки с помощью вашего устройства. Улучшенное управление профилем, инновационная концепция дизайна для удобной навигации и значительно более высокая скорость работы приложения – всё это создано для вас. Присоединяйтесь к числу воодушевленных пользователей и получайте удовольствие от ставок в любой точке планеты и в любое время. Установите обновление приложения БК Лига Ставок уже сегодня и переходите к новому этапу ставок!
best online ed medication: cheap ed medication – cheap ed pills online
Анонсируем запуск новой версии мобильного приложения БК Лига Ставок для Android! Этот выпуск существенно улучшает ваш пользовательский опыт, делая его ещё удобнее и динамичным. Букмекерская контора лига ставок на андроид сейчас же! В обновлении вы найдете прямой доступ к многообразию спортивных мероприятий прямо с вашего смартфона. Улучшенное управление профилем, передовая концепция дизайна для удобной навигации и увеличенная скорость работы приложения – всё это создано для вас. Станьте частью довольных пользователей и наслаждайтесь возможностями от ставок в любой точке планеты и в любое время. Установите обновление приложения БК Лига Ставок прямо сейчас и выходите на новый уровень ставок!
Pingback: animal porn
http://onlinepharmacyworld.shop/# pharmacy coupons
https://onlinepharmacyworld.shop/# offshore pharmacy no prescription
Вашему вниманию предлагается эксклюзивное предложение от БК Лига Ставок – фрибет для новых игроков! Это фрибет позволяет вам испытать удачу без риска потери собственных средств, открывая новые горизонты для выигрыша с первых же шагов в мире ставок. Лига ставок условия фрибета новым пользователям после регистрации! С фрибетом от БК Лига Ставок, вы имеете возможность испытать все преимущества ставок без каких-либо финансовых обязательств. Это идеальный старт для тех, кто хочет погрузиться в мир ставок с минимальными рисками. Воспользуйтесь этим предложением и начните своё приключение в БК Лига Ставок с нашим фрибетом. Заберите свой фрибет сейчас же и стартуйте к выигрышам!
Вашему вниманию предлагается эксклюзивное предложение от БК Лига Ставок – фрибет для новых игроков! Это бесплатная ставка позволяет вам сделать ставку без риска потери собственных средств, открывая новые горизонты для выигрыша с первых же шагов в мире ставок. Фрибет за регистрацию без депозита лига ставок для всех новичков после регистрации! С фрибетом от БК Лига Ставок, вы получаете шанс ознакомиться с платформой без каких-либо финансовых обязательств. Это отличный способ начать для тех, кто хочет стать частью мира спортивных ставок с минимальными рисками. Воспользуйтесь этим предложением и сделайте первый шаг к большим выигрышам в БК Лига Ставок с нашим фрибетом. Активируйте ваш фрибет уже сегодня и откройте для себя мир ставок без рисков!
casino tr?c tuy?n casino tr?c tuy?n uy tin casino tr?c tuy?n vi?t nam
Знакомьтесь с эксклюзивное предложение от БК Лига Ставок – фрибет для новых игроков! Это фрибет даёт возможность вам сделать ставку без риска потери собственных средств, предоставляя широкие возможности для получения призов с первых же шагов в мире ставок. Лига ставок фрибеты новым пользователям после регистрации! С фрибетом от БК Лига Ставок, вы получаете шанс ознакомиться с платформой без каких-либо финансовых обязательств. Это идеальный старт для тех, кто хочет погрузиться в мир ставок с минимальными рисками. Воспользуйтесь этим предложением и сделайте первый шаг к большим выигрышам в БК Лига Ставок с нашим фрибетом. Заберите свой фрибет сейчас же и стартуйте к выигрышам!
Знакомьтесь с эксклюзивное предложение от БК Лига Ставок – фрибет для новых игроков! Это фрибет позволяет вам испытать удачу без риска потери собственных средств, открывая новые горизонты для выигрыша с первых же шагов в мире ставок. Лига ставок фрибет за регистрацию без депозита новым пользователям после регистрации! С фрибетом от БК Лига Ставок, вы получаете шанс ознакомиться с платформой без каких-либо финансовых обязательств. Это идеальный старт для тех, кто хочет стать частью мира спортивных ставок с минимальными рисками. Не упускайте свой шанс и начните своё приключение в БК Лига Ставок с нашим фрибетом. Активируйте ваш фрибет уже сегодня и стартуйте к выигрышам!
Представляем выпуске эксклюзивного промокода для БК Лига Ставок! Этот специальный промокод предоставляет доступ к особым бонусам и усиливает ваш игровой процесс, делая его ещё более выгодным и захватывающим. Где взять промокод лига ставок для активации сегодня! С его использованием, игроки получают непосредственный доступ к дополнительным бонусам на ставки, привилегиям при регистрации и эксклюзивным акциям. Воспользуйтесь этой возможностью стать частью элитного клуба пользователей БК Лига Ставок и максимизируйте свои выигрыши с нашим промокодом. Используйте код прямо сейчас и начните выигрывать еще до первой ставки!
casino tr?c tuy?n: casino tr?c tuy?n – web c? b?c online uy tín
Рады сообщить о выпуске эксклюзивного промокода для БК Лига Ставок! Этот уникальный код открывает доступ к эксклюзивным привилегиям и усиливает ваш опыт ставок, делая его более прибыльным и волнующим. Промокоды на лига ставок для активации сегодня! С данным промокодом, игроки получают доступ к дополнительным бонусам на ставки, ускоренной процедуре регистрации и специальным предложениям. Воспользуйтесь этой возможностью стать частью привилегированной группы пользователей БК Лига Ставок и увеличьте свои шансы на успех с нашим промокодом. Используйте код прямо сейчас и заберите свои бонусы еще до первой ставки!
Рады сообщить о доступности эксклюзивного промокода для БК Лига Ставок! Этот специальный промокод предоставляет доступ к эксклюзивным привилегиям и усиливает ваш игровой процесс, делая его ещё более выгодным и захватывающим. Лига ставок промокод фрибет после ввода кода! С данным промокодом, игроки получают непосредственный доступ к дополнительным бонусам на ставки, привилегиям при регистрации и специальным предложениям. Не упустите шанс стать частью привилегированной группы пользователей БК Лига Ставок и максимизируйте свои выигрыши с нашим промокодом. Активируйте промокод уже сегодня и начните выигрывать еще до первой ставки!
casino tr?c tuy?n uy tin casino tr?c tuy?n vi?t nam casino tr?c tuy?n
Самый ожидаемый футбольный поединок сезона – Манчестер Сити против Реала Мадрид! Страсть, нервы, и невероятные эмоции ждут нас на поле. Но этот день может быть еще более захватывающим благодаря промокоду PLAYDAY от 1win! Ставьте на своего героя с уверенностью и повысьте свои шансы на победу! Не упустите шанс – забирайте Манчестер Сити Реал бонус код за регистрацию уже сегодня!
Самый ожидаемый футбольный поединок сезона – Манчестер Сити против Реала Мадрид! Энтузиазм, нервы, и ожидание ждут нас на поле. Но этот день может быть еще более захватывающим благодаря промокоду PLAYDAY от 1win! Ставьте на своего героя с уверенностью и растите свои шансы на победу! Не упустите шанс – забирайте Манчестер Сити Реал Мадрид промокод уже сегодня!
Самый ожидаемый футбольный поединок сезона – Манчестер Сити против Реала Мадрид! Азарт, напряжение, и невероятные эмоции ждут нас на поле. Но этот день может быть еще более интригующим благодаря промокоду PLAYDAY от 1win! Ставьте на своего героя с уверенностью и повысьте свои шансы на победу! Не упустите шанс – забирайте Манчестер Сити Реал бонус код за регистрацию уже сегодня!
Самый ожидаемый футбольный поединок сезона – Манчестер Сити против Реала Мадрид! Энтузиазм, нервы, и адреналин ждут нас на поле. Но этот день может быть еще более захватывающим благодаря промокоду PLAYDAY от 1win! Ставьте на своего любимца с уверенностью и удвойте свои шансы на победу! Не упустите шанс – забирайте Манчестер Сити Реал бонус код за регистрацию уже сегодня!
Битва гигантов на поле – Бавария против Арсенала! Волнение, возбуждение и невероятные моменты ждут нас в этом схватке. Но почему бы не добавить еще больше эмоций с помощью промокода PLAYDAY от 1win? Сделайте ставку на победный исход и растите свои выигрышные возможности! Не упустите этот шанс – используйте Бавария Арсенал бонус 500 уже сегодня и наслаждайтесь игры в полную силу!
http://casinvietnam.shop/# casino tr?c tuy?n vi?t nam
Битва гигантов на поле – Бавария против Арсенала! Эмоции, напряжение и уникальные ситуации ждут нас в этом противостоянии. Но почему бы не добавить еще больше адреналина с помощью промокода PLAYDAY от 1win? Сделайте ставку на победную команду и повысьте свои шансы на победу! Не упустите этот момент – активируйте Бавария Арсенал промокод уже сегодня и радуйтесь игры в полную силу!
Встречайте матч на высшем уровне с промокодом PLAYDAY от 1win! Независимо от того, на какую событие вы ставите – будь то спортивное противостояние – этот промокод приносит вам дополнительные шансы для победы. Расти свои выигрышные шансы, активируя промокод PLAYDAY при размещении ставок. Не упустите возможность на потрясающие впечатления и дополнительные выигрыши – воспользуйтесь 1win casino бонусы прямо сейчас на 1win!
Встречайте спортивное событие на высшем уровне с промокодом PLAYDAY от 1win! Независимо от того, на какую матч вы ставите – будь то футбольная битва – этот промокод приносит вам дополнительные шансы для победы. Увеличьте свои шансы на успех, используя промокод PLAYDAY при размещении ставок. Не упустите возможность на потрясающие впечатления и бонусные выигрыши – воспользуйтесь 1win casino бонус код прямо сейчас на 1win!
Встречайте матч на новом уровне с промокодом PLAYDAY от 1win! Независимо от того, на какой событие вы ставите – будь то баскетбольный поединок – этот промокод приносит вам экстра-шансы для победы. Расти свои вероятность победы, используя промокод PLAYDAY при размещении ставок. Не упустите возможность на увлекательный опыт и дополнительные выигрыши – воспользуйтесь промокод на 1win на сегодня прямо сейчас на 1win!
Встречайте игру на высшем уровне с промокодом PLAYDAY от 1win! Независимо от того, на какой событие вы ставите – будь то баскетбольный поединок – этот промокод приносит вам экстра-шансы для победы. Расти свои вероятность победы, применяя промокод PLAYDAY при размещении ставок. Не упустите шанс на захватывающий опыт и дополнительные выигрыши – воспользуйтесь бонус код 1win прямо сейчас на 1win!
game c? b?c online uy tín: dánh bài tr?c tuy?n – casino tr?c tuy?n
В настоящее время наши дни могут содержать неожиданные расходы и экономические трудности, и в такие моменты каждый ищет помощь. На сайте займ в беларуси вам помогут без избыточной бюрократии. В своей роли агента я стремлюсь распространить эту информацию, чтобы помочь людям в сложной ситуации. Наша платформа обеспечивает прозрачные условия и быструю обработку заявок, чтобы каждый мог решить свои денежные проблемы быстро и без лишних хлопот.
подъем домов
В настоящее время наши дни могут содержать внезапные издержки и экономические трудности, и в такие моменты каждый ищет помощь. На сайте займ денег вам помогут без лишних сложностей. В своей роли агента я стремлюсь поделиться этими сведениями, чтобы помочь тем, кто столкнулся с временными трудностями. Наша система обеспечивает честные условия и быструю обработку заявок, чтобы каждый мог решить свои денежные проблемы оперативно и без лишних затрат времени.
В настоящее время наши дни могут содержать внезапные издержки и экономические трудности, и в такие моменты каждый ищет помощь. На сайте получить займ в Минске вам помогут без лишних сложностей. В своей роли представителя я стремлюсь поделиться этими сведениями, чтобы помочь тем, кто столкнулся с временными трудностями. Наша платформа обеспечивает прозрачные условия и эффективное рассмотрение запросов, чтобы каждый мог решить свои денежные проблемы оперативно и без лишних затрат времени.
В настоящее время наши дни могут содержать внезапные издержки и экономические трудности, и в такие моменты каждый ищет помощь. На сайте получить деньги в долг вам помогут без лишних сложностей. В своей роли представителя я стремлюсь распространить эту информацию, чтобы помочь людям в сложной ситуации. Наша система обеспечивает честные условия и быструю обработку заявок, чтобы каждый мог разрешить свои финансовые вопросы оперативно и без лишних затрат времени.
PBN sites
We shall create a web of privately-owned blog network sites!
Pros of our PBN network:
We execute everything so GOOGLE DOES NOT understand that THIS IS A private blog network!!!
1- We buy domain names from distinct registrars
2- The leading site is hosted on a virtual private server (Virtual Private Server is rapid hosting)
3- Other sites are on various hostings
4- We designate a unique Google profile to each site with verification in Google Search Console.
5- We make websites on WordPress, we don’t use plugins with assistance from which malware penetrate and through which pages on your websites are produced.
6- We don’t repeat templates and employ only distinct text and pictures
We don’t work with website design; the client, if desired, can then edit the websites to suit his wishes
В наше время многие из нас сталкиваются с внезапными затратами и экономическими вызовами, и в такие моменты важно иметь доступ к дополнительным средствам. На сайте деньги в долг вам помогут быстро и удобно. В качестве представителя Брокерс Групп, я рад делиться этой важной информацией, чтобы помочь людям, кто нуждается в финансовой поддержке. Наша система гарантирует прозрачные условия и оперативное рассмотрение запросов, чтобы каждый мог решить свои финансовые вопросы быстро и эффективно.
what is the alternative to voltaren
В наше время многие из нас сталкиваются с непредвиденными расходами и денежными трудностями, и в такие моменты важно иметь возможность взять кредит. На сайте займ в РБ вам помогут быстро и удобно. В качестве официального представителя Брокерс Групп, я рад делиться этой информацией, чтобы помочь каждому, кто нуждается в финансовой поддержке. Наша система гарантирует честные условия и оперативное рассмотрение запросов, чтобы каждый мог решить свои финансовые вопросы быстро и эффективно.
В наше время многие из нас сталкиваются с непредвиденными расходами и экономическими вызовами, и в такие моменты важно иметь доступ к дополнительным средствам. На сайте займ в беларуси вам помогут быстро и удобно. В качестве представителя Брокерс Групп, я с удовольствием делиться этой важной информацией, чтобы помочь каждому, кто столкнулся с финансовыми трудностями. Наша система гарантирует честные условия и быструю обработку заявок, чтобы каждый мог разрешить свои денежные проблемы с минимальными временными затратами.
choi casino tr?c tuy?n tren di?n tho?i casino tr?c tuy?n uy tin game c? b?c online uy tin
В наше время многие из нас сталкиваются с непредвиденными расходами и денежными трудностями, и в такие моменты важно иметь доступ к дополнительным средствам. На сайте займ в РБ вам помогут с минимальными усилиями. В качестве официального представителя Брокерс Групп, я рад делиться этой информацией, чтобы помочь людям, кто столкнулся с финансовыми трудностями. Наша система гарантирует прозрачные условия и быструю обработку заявок, чтобы каждый мог разрешить свои денежные проблемы быстро и эффективно.
tamsulosin hexal 0 4 mg
В настоящей эпохе финансовые трудности встречаются часто, и каждый из нас может оказаться в ситуации, когда необходима дополнительная финансовая поддержка. На сайте moneybel.ru помогут решить эти проблемы, принося простой и лёгкий метод получения кредита. Мы понимаем, что времени на решение проблемы не хватает, поэтому наш процесс обработки заявок максимально быстр и эффективен. В качестве представителя Манибел, наша цель – помочь каждому клиенту преодолеть финансовые затруднения, предложив ясные и выгодные условия займа. Доверьтесь нам, и мы решим ваши финансовые проблемы.
В настоящей эпохе финансовые сложности не редкость, и каждый человек может оказаться в ситуации, когда необходима дополнительная финансовая поддержка. На сайте взять деньги в долг помогут преодолеть эти трудности, предоставляя простой и лёгкий метод получения кредита. Мы понимаем, что времени на решение проблемы не хватает, поэтому мы обрабатываем заявки оперативно и эффективно. В роли представителя Манибел, мы нацелены на то, чтобы помочь каждому клиенту преодолеть свои денежные трудности, предложив ясные и выгодные условия займа. Доверьтесь нам, и мы решим ваши финансовые проблемы.
tizanidine alcohol
best time of day to take venlafaxine for hot flashes
В настоящей эпохе финансовые сложности не редкость, и каждый из нас может оказаться в ситуации, когда потребуется дополнительная финансовая помощь. На сайте займы онлайн помогут решить эти проблемы, предоставляя простой и лёгкий метод получения кредита. Мы понимаем, что время играет ключевую роль, поэтому мы обрабатываем заявки оперативно и эффективно. В качестве представителя Манибел, мы нацелены на то, чтобы помочь каждому клиенту преодолеть свои денежные трудности, предложив ясные и выгодные условия займа. Доверьтесь нам, и мы поможем вам в решении ваших финансовых проблем.
https://casinvietnam.shop/# casino tr?c tuy?n vi?t nam
В настоящей эпохе финансовые сложности не редкость, и каждый человек может оказаться в ситуации, когда необходима дополнительная финансовая поддержка. На сайте срочно взять деньги помогут решить эти проблемы, принося простой и удобный способ получения кредита. Мы осознаём, что время играет ключевую роль, поэтому наш процесс обработки заявок максимально быстр и эффективен. В роли представителя Манибел, мы нацелены на то, чтобы помочь каждому клиенту преодолеть свои денежные трудности, предложив ясные и выгодные условия займа. Доверьтесь нашей компании, и мы поможем вам в решении ваших финансовых проблем.
Bellenty – ваш надёжный союзник в области конвейерных решений. Для вас купить конвейерные ленты в Минске помогут консультанты интернет-магазина. Благодаря нашему практике и компетентности мы гарантируем, что каждая лента, предлагаемая нами, соответствует высочайшим стандартам стандартам качества и эффективности. Мы изготавливаем индивидуальные решения, учитывая особые потребности наших заказчиков. Независимо от величины, состава или технических характеристик, Bellenty обеспечивает идеальное решение для вашего конвейерного оборудования, даря вашему бизнесу надёжность и эффективность.
Bellenty – ваш надёжный союзник в области конвейерных решений. Для вас стоимость конвейерных лент в Минске помогут консультанты интернет-магазина. Благодаря нашему практике и профессионализму мы гарантируем, что каждая лента, предлагаемая нами, соответствует высочайшим стандартам стандартам качества и эффективности. Мы разрабатываем индивидуальные решения, учитывая особые потребности наших клиентов. Независимо от величины, состава или спецификаций, Bellenty обеспечивает идеальное решение для вашего конвейерного оборудования, даря вашему бизнесу надёжность и эффективность.
Bellenty – ваш надёжный союзник в области конвейерных решений. Для вас стоимость конвейерных лент в Минске помогут консультанты магазина. Благодаря нашему опыту и компетентности мы гарантируем, что каждая лента, предлагаемая нами, соответствует высочайшим стандартам стандартам качества и эффективности. Мы изготавливаем индивидуальные решения, учитывая особые потребности наших клиентов. Независимо от величины, материала или спецификаций, Bellenty обеспечивает идеальное решение для вашего конвейерного оборудования, даря вашему бизнесу надёжность и эффективность.
Bellenty – ваш надёжный союзник в области конвейерных решений. Для вас стоимость лент конвейерных в Минске помогут консультанты интернет-магазина. Благодаря нашему опыту и профессионализму мы гарантируем, что каждая лента, предлагаемая нами, соответствует высочайшим стандартам качества и эффективности. Мы производим индивидуальные решения, учитывая уникальные потребности наших заказчиков. Независимо от величины, состава или спецификаций, Bellenty обеспечивает идеальное решение для вашего конвейерного оборудования, даря вашему бизнесу надёжность и эффективность.
Your article helped me a lot, is there any more related content? Thanks!
https://casinvietnam.com/# casino tr?c tuy?n vi?t nam