

Scraping Amazon product listings using Python
The online retail and eCommerce industry is highly data-driven. Keeping the right data always in your stockpile has become more of a necessity not just to beat the competition but also to stay in the business line.
Amazon is one of the most popular and largest online stores. A survey shows there are over 353 million products listed over various marketplaces in Amazon. Consider the option of you getting a particular product from those. Manual copy pasting might seem to be a tedious and arduous task. That’s where an automated amazon web scraping comes in handy.
So what is meant by amazon scraper or web scraping?
Web scraping or web harvesting is the process of scouring the web for necessary details and furnishing the collated information in your preferred format like CSV, Excel, API etc. Ideally, to scrape amazon product data, we use a software program called bots or scraper that uses the URL provided to make HTTP requests, parses the HTML webpage, accumulates the content.
Benefits of scraping eCommerce websites
Competitive Price Monitoring
When it comes to retail industry price is the key player. Right from the socks for your shoes to any large-scale appliances like TV, refrigerators everything is available online these days. A consumer often compares the product online even before deciding to buy. So amazon scraper does a comparative study with your competitors always helps in pricing your product accordingly.
Companies are now using data scraping tools to scrape amazon prices in order to keep track of their competitors’ pricing. An amazon web scraper will update you with all the latest price fluctuations in the market for adopting dynamic pricing strategy. A well-designed amazon scraper can scrape amazon prices of your competitors on a scheduled basis, which helps you develop a competitive pricing strategy.
Product Ranking
The customer buys products that appear on top of the search list. Amazon ranks their top-selling products on an hourly basis. By collating web scraper amazon product listings details, sellers can understand how and why other products are ranked higher than theirs and work on displaying their products first on the page.
A targeted amazon product scraper will provide you with a detailed picture of your product listings and will notify you if the ranking changes. This will help an organization to curate strategies to improve their product visibility in amazon.
Amazon Scraper Product Categorisation
“Sapiens: A Brief History of Humankind” should appear under the category Books, Books > History > World, and Books > Yuval Noah Harari. When a simple book can be categorised in three ways, calculate the various combinations on how to classify your product. The categorisation of the products can be improved by understanding the various contexts where the same products can be sold.
An amazon product scraper will offer datasets that contain all the products as well as the category to which they belong, allowing you to place your products in the most appropriate category to improve sales.
Customer Information Management
Seller needs to know who their buyers are. Accumulating customer information like customer name, location, age, what product is being brought is essential to form effective market insights. This results in increased sales and builds the customer relationship.
The Amazon data scraper will provide you with a detailed picture of who your consumers are and which demographic groups they belong to, allowing you to target your marketing efforts toward them.
Sentiment Analysis
Amazon provides the customers to voice out their feedback on the quality of the product, the delivery, and the seller. A seller can enhance their customer experience by aggregating web scraper amazon reviews provided by the customers in the Amazon webpage using an amazon review scraper. An Amazon review scraper may also assist you in developing innovative products depending on the needs of your customers.
To form effective insights like these you need to have the relevant information at hand first. Let’s develop a simple crawler to scrape amazon product data using Python.
How to scrape Amazon listings using Python
The following code will show how to scrape the Amazon product listings using Python.
Here, Python 2.7 is used over other versions because this particular version has many modules and libraries that are built exclusively for web scraping.
Prerequisites:
Before going into the actual coding, make sure the following requirements are met.
- Have Python 2.7 version installed and running in your system.
- Install the LXML and Requests module up and running in your system.
After installing and executing Python in your system, follow the below steps.
Let’s keep this as a simple crawler bot that scrapes the product listings that appear on a customer search and fetches their links.
Step 1: Import the necessary modules and library that are required for developing amazon scraping tool.
import requests import pprint from lxml import html
Step 2: Create an object to store the session for a particular HTTP request.
sess = requests.Session()
Step 3: Create a user-agent object. This is used to identify the device from where the request is made either desktop, tablet or mobile and fake the number of browser hits.
sess.headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0'
Step 4: Store the website URL to be scraped in the url object.
url = "https://www.amazon.co.uk/s?me=A2TJZM2IPQFK92&merchant=A2TJZM2IPQFK92&qid=1541748022"
Step 5: Pass this url in sess.get() to get the link to be scraped for that particular session and store the result in a variable termed “res”.
res = sess.get(url)
Step 6: This result will be in machine-readable format. All the content fetched is stored in a variable “data”.
data = res.content
Step 7: The collated information is structured using HTML.fromstring() and stored in a variable – tree.
tree = html.fromstring(data)
Step 8: The structured information is stored in a file – cont.html using the write().
f=open("Cont.html","w")
f.write("%s"%data)
f.close()
Step 9: On inspecting the HTML page, the required information is present in a particular DOM structure. Find out that structure and pass it to the file to pick up only those contents. This file is searched for that particular format and the contents here the links to the listings are then fetched. These links are stored in a text file namely Links.txt.
pdpLinks = tree.xpath('/html/body/div[1]/div[2]/div/div[3]/div[2]/div/div[4]/div[1]/div/ul/li/div/div/div[1]/a/@href')
for links in pdpLinks:
print links
with open ("Links.txt", "a") as fh:
fh.write ("%s"%links+"\n")
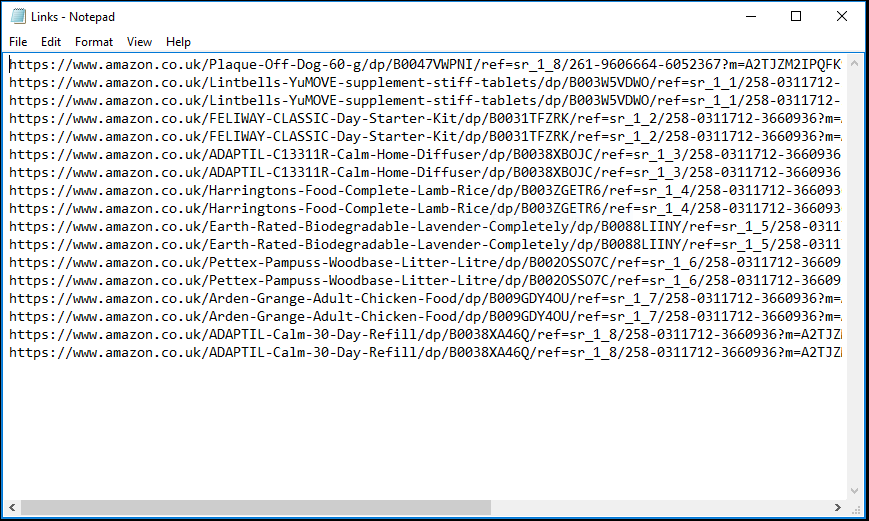
The scraped data would be stored in a structured text format like below.
Major road-blocks while scraping eCommerce websites
Even though developing an amazon web scraping tool has become simpler with Python, individual retail scraper bots face many hurdles. Scraping eCommerce websites have proved to be a more challenging task than any other industries.
The following are the key challenges encountered while trying to scrape any retail webpage.
- Massive dataset
- Bot Modernization
- Legal issues
- Bot bypassing
- CAPTCHA and IP blocks
Every day hundreds and thousands of products get added to the already large database of Amazon list. Scraping a specific brand or seller proves to be a prolonged and tiresome process. Moreover, these listings are ranked and updated every hour. Therefore, the program that you have written to develop amazon product scraper needs constant enhancements to cater to the changes.
The number of HTTP requests made to the server is monitored. If there are many requests coming from the same IP address the source might detect the scraping bot and block the identified IP access to their site. Moreover, amazon scraper bots are usually blocked at the CAPTCHA pages. Outsourcing your data scraping requirements might be a good option because it improves the data’s legitimacy and freshness. A customized web scraping tool can assist you in receiving data at scale in the fastest time possible to scrape amazon product data.
That’s where scraping services brighten your business. At Scrapeworks, we take care of all the technical tasks so that you can improve the quality of your operations using amazon scraper. Utilize our various retail scraping services to increase your sales.

Kalpana Rajarajan
Content Marketing Specialist


